 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPTreeO: An R package for continual regression with dividing local Gaussian processes
Oct 01, 2024



We introduce GPTreeO, a flexible R package for scalable Gaussian process (GP) regression, particularly tailored to continual learning problems. GPTreeO builds upon the Dividing Local Gaussian Processes (DLGP) algorithm, in which a binary tree of local GP regressors is dynamically constructed using a continual stream of input data. In GPTreeO we extend the original DLGP algorithm by allowing continual optimisation of the GP hyperparameters, incorporating uncertainty calibration, and introducing new strategies for how the local partitions are created. Moreover, the modular code structure allows users to interface their favourite GP library to perform the local GP regression in GPTreeO. The flexibility of GPTreeO gives the user fine-grained control of the balance between computational speed, accuracy, stability and smoothness. We conduct a sensitivity analysis to show how GPTreeO's configurable features impact the regression performance in a continual learning setting.
A copula-based boosting model for time-to-event prediction with dependent censoring
Oct 10, 2022
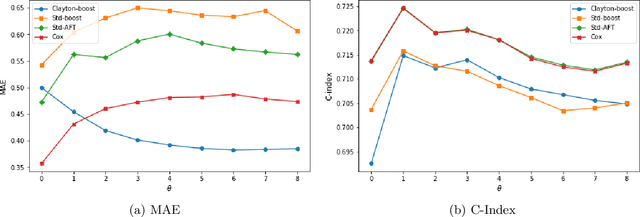
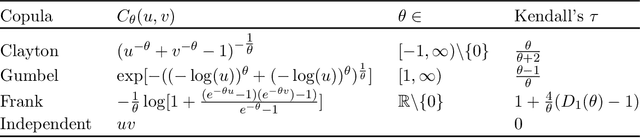
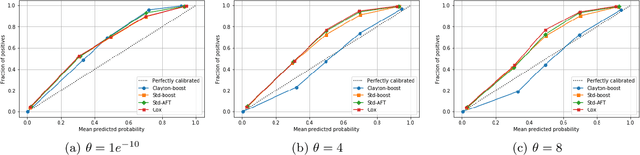
A characteristic feature of time-to-event data analysis is possible censoring of the event time. Most of the statistical learning methods for handling censored data are limited by the assumption of independent censoring, even if this can lead to biased predictions when the assumption does not hold. This paper introduces Clayton-boost, a boosting approach built upon the accelerated failure time model, which uses a Clayton copula to handle the dependency between the event and censoring distributions. By taking advantage of a copula, the independent censoring assumption is not needed any more. During comparisons with commonly used methods, Clayton-boost shows a strong ability to remove prediction bias at the presence of dependent censoring and outperforms the comparing methods either if the dependency strength or percentage censoring are considerable. The encouraging performance of Clayton-boost shows that there is indeed reasons to be critical about the independent censoring assumption, and that real-world data could highly benefit from modelling the potential dependency.
A Machine Learning Approach to Safer Airplane Landings: Predicting Runway Conditions using Weather and Flight Data
Jul 01, 2021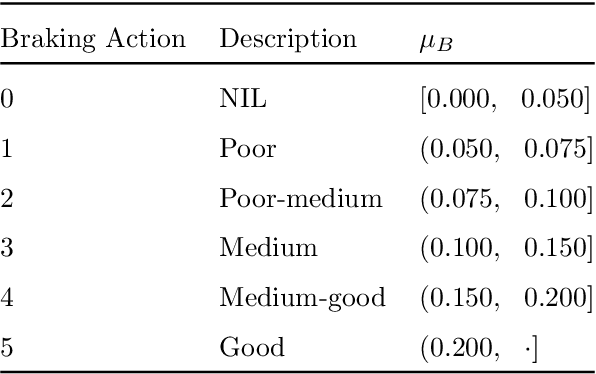
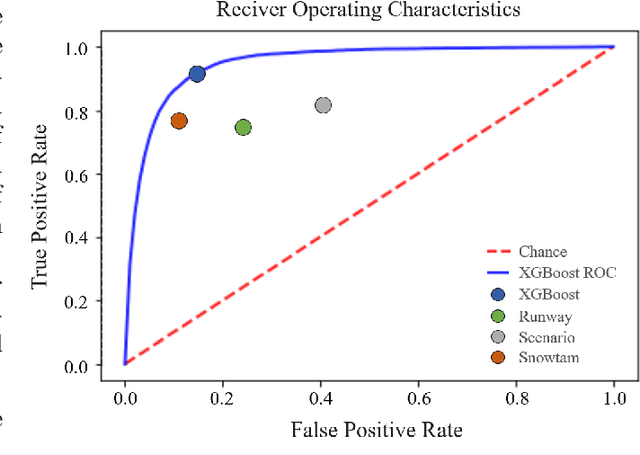
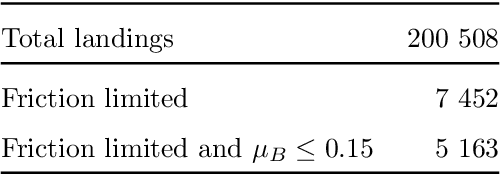

The presence of snow and ice on runway surfaces reduces the available tire-pavement friction needed for retardation and directional control and causes potential economic and safety threats for the aviation industry during the winter seasons. To activate appropriate safety procedures, pilots need accurate and timely information on the actual runway surface conditions. In this study, XGBoost is used to create a combined runway assessment system, which includes a classifcation model to predict slippery conditions and a regression model to predict the level of slipperiness. The models are trained on weather data and data from runway reports. The runway surface conditions are represented by the tire-pavement friction coefficient, which is estimated from flight sensor data from landing aircrafts. To evaluate the performance of the models, they are compared to several state-of-the-art runway assessment methods. The XGBoost models identify slippery runway conditions with a ROC AUC of 0.95, predict the friction coefficient with a MAE of 0.0254, and outperforms all the previous methods. The results show the strong abilities of machine learning methods to model complex, physical phenomena with a good accuracy when domain knowledge is used in the variable extraction. The XGBoost models are combined with SHAP (SHapley Additive exPlanations) approximations to provide a comprehensible decision support system for airport operators and pilots, which can contribute to safer and more economic operations of airport runways.
Simple statistical models and sequential deep learning for Lithium-ion batteries degradation under dynamic conditions: Fractional Polynomials vs Neural Networks
Feb 16, 2021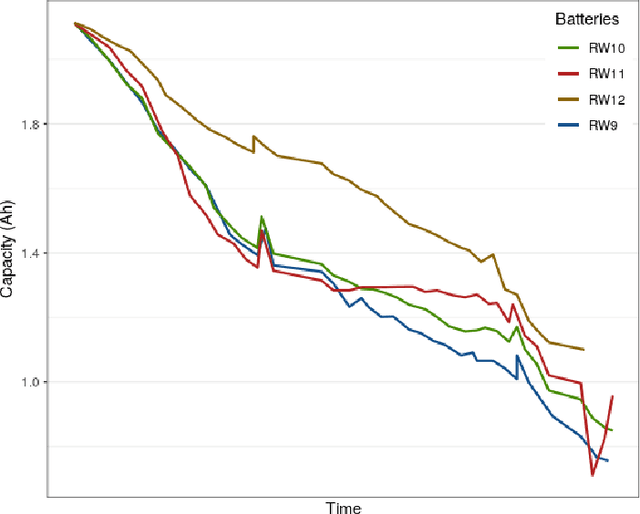
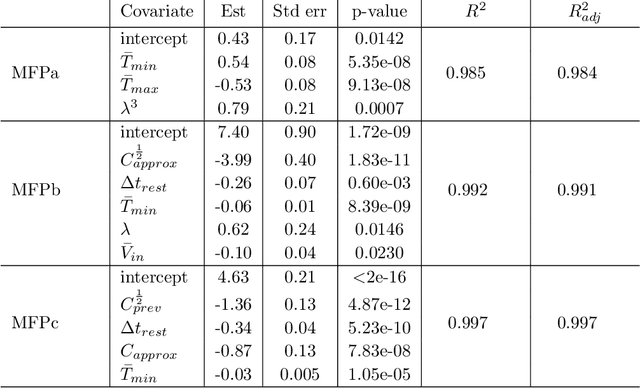
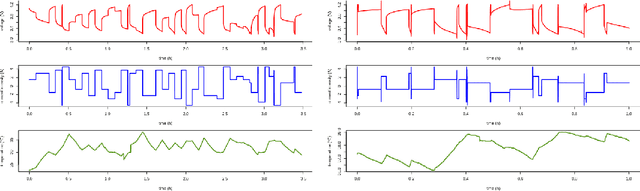
Longevity and safety of Lithium-ion batteries are facilitated by efficient monitoring and adjustment of the battery operating conditions: hence, it is crucial to implement fast and accurate algorithms for State of Health (SoH) monitoring on the Battery Management System. The task is challenging due to the complexity and multitude of the factors contributing to the battery capacity degradation, especially because the different degradation processes occur at various timescales and their interactions play an important role. This paper proposes and compares two data-driven approaches: a Long Short-Term Memory neural network, from the field of deep learning, and a Multivariable Fractional Polynomial regression, from classical statistics. Models from both classes are trained from historical data of one exhausted cell and used to predict the SoH of other cells. This work uses data provided by the NASA Ames Prognostics Center of Excellence, characterised by varying loads which simulate dynamic operating conditions. Two hypothetical scenarios are considered: one assumes that a recent true capacity measurement is known, the other relies solely on the cell nominal capacity. Both methods are effective, with low prediction errors, and the advantages of one over the other in terms of interpretability and complexity are discussed in a critical way.
A U-statistic estimator for the variance of resampling-based error estimators
Dec 18, 2013We revisit resampling procedures for error estimation in binary classification in terms of U-statistics. In particular, we exploit the fact that the error rate estimator involving all learning-testing splits is a U-statistic. Thus, it has minimal variance among all unbiased estimators and is asymptotically normally distributed. Moreover, there is an unbiased estimator for this minimal variance if the total sample size is at least the double learning set size plus two. In this case, we exhibit such an estimator which is another U-statistic. It enjoys, again, various optimality properties and yields an asymptotically exact hypothesis test of the equality of error rates when two learning algorithms are compared. Our statements apply to any deterministic learning algorithms under weak non-degeneracy assumptions.