 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple statistical models and sequential deep learning for Lithium-ion batteries degradation under dynamic conditions: Fractional Polynomials vs Neural Networks
Feb 16, 2021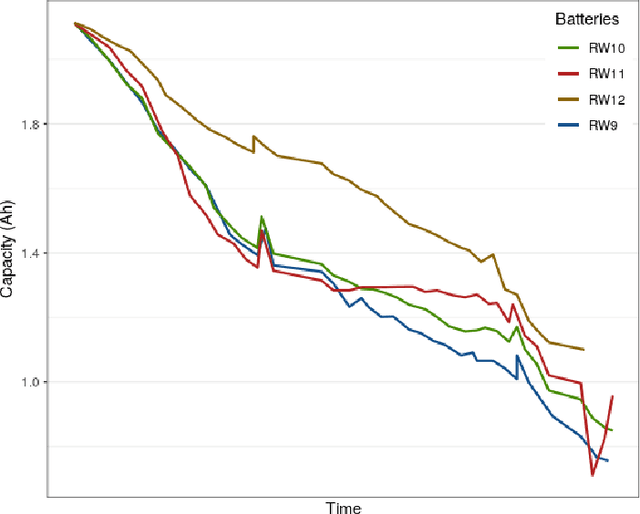
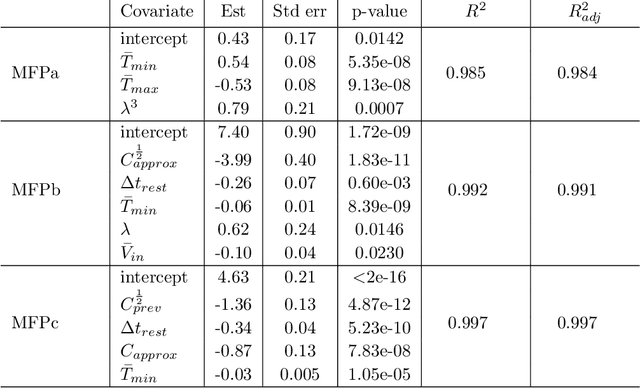
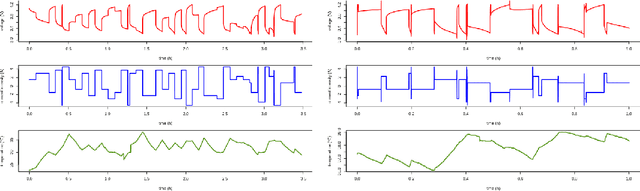
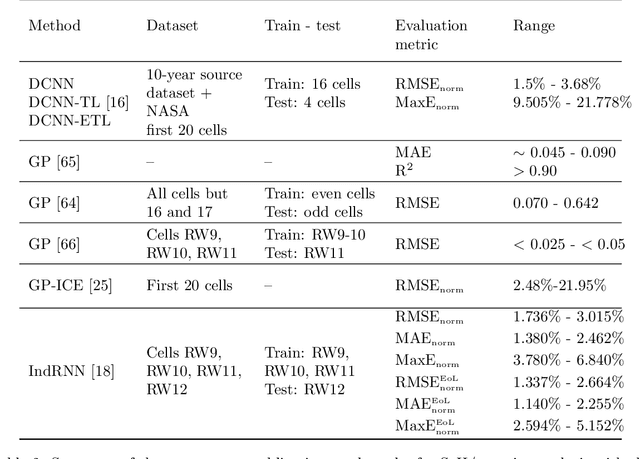
Longevity and safety of Lithium-ion batteries are facilitated by efficient monitoring and adjustment of the battery operating conditions: hence, it is crucial to implement fast and accurate algorithms for State of Health (SoH) monitoring on the Battery Management System. The task is challenging due to the complexity and multitude of the factors contributing to the battery capacity degradation, especially because the different degradation processes occur at various timescales and their interactions play an important role. This paper proposes and compares two data-driven approaches: a Long Short-Term Memory neural network, from the field of deep learning, and a Multivariable Fractional Polynomial regression, from classical statistics. Models from both classes are trained from historical data of one exhausted cell and used to predict the SoH of other cells. This work uses data provided by the NASA Ames Prognostics Center of Excellence, characterised by varying loads which simulate dynamic operating conditions. Two hypothetical scenarios are considered: one assumes that a recent true capacity measurement is known, the other relies solely on the cell nominal capacity. Both methods are effective, with low prediction errors, and the advantages of one over the other in terms of interpretability and complexity are discussed in a critical way.
Explainable Artificial Intelligence: How Subsets of the Training Data Affect a Prediction
Dec 07, 2020



There is an increasing interest in and demand for interpretations and explanations of machine learning models and predictions in various application areas. In this paper, we consider data-driven models which are already developed, implemented and trained. Our goal is to interpret the models and explain and understand their predictions. Since the predictions made by data-driven models rely heavily on the data used for training, we believe explanations should convey information about how the training data affects the predictions. To do this, we propose a novel methodology which we call Shapley values for training data subset importance. The Shapley value concept originates from coalitional game theory, developed to fairly distribute the payout among a set of cooperating players. We extend this to subset importance, where a prediction is explained by treating the subsets of the training data as players in a game where the predictions are the payouts. We describe and illustrate how the proposed method can be useful and demonstrate its capabilities on several examples. We show how the proposed explanations can be used to reveal biasedness in models and erroneous training data. Furthermore, we demonstrate that when predictions are accurately explained in a known situation, then explanations of predictions by simple models correspond to the intuitive explanations. We argue that the explanations enable us to perceive more of the inner workings of the algorithms, and illustrate how models producing similar predictions can be based on very different parts of the training data. Finally, we show how we can use Shapley values for subset importance to enhance our training data acquisition, and by this reducing prediction error.
Online Detection of Sparse Changes in High-Dimensional Data Streams Using Tailored Projections
Aug 06, 2019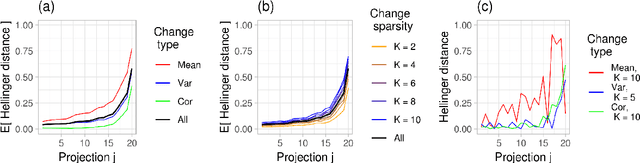
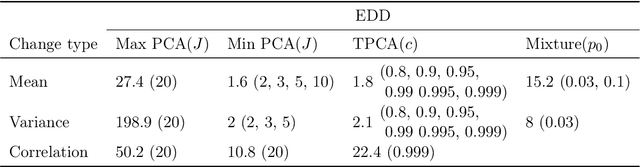
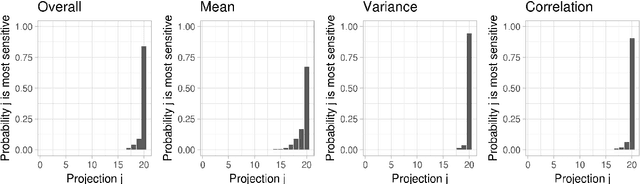
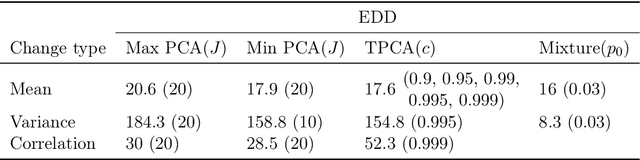
When applying principal component analysis (PCA) for dimension reduction, the most varying projections are usually used in order to retain most of the information. For the purpose of anomaly and change detection, however, the least varying projections are often the most important ones. In this article, we present a novel method that automatically tailors the choice of projections to monitor for sparse changes in the mean and/or covariance matrix of high-dimensional data. A subset of the least varying projections is almost always selected based on a criteria of the projection's sensitivity to changes. Our focus is on online/sequential change detection, where the aim is to detect changes as quickly as possible, while controlling false alarms at a specified level. A combination of tailored PCA and a generalized log-likelihood monitoring procedure displays high efficiency in detecting even very sparse changes in the mean, variance and correlation. We demonstrate on real data that tailored PCA monitoring is efficient for sparse change detection also when the data streams are highly auto-correlated and non-normal. Notably, error control is achieved without a large validation set, which is needed in most existing methods.