 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Mean Field Games and Mean Field Control with Applications to Finance
Jul 09, 2021


Financial markets and more generally macro-economic models involve a large number of individuals interacting through variables such as prices resulting from the aggregate behavior of all the agents. Mean field games have been introduced to study Nash equilibria for such problems in the limit when the number of players is infinite. The theory has been extensively developed in the past decade, using both analytical and probabilistic tools, and a wide range of applications have been discovered, from economics to crowd motion. More recently the interaction with machine learning has attracted a growing interest. This aspect is particularly relevant to solve very large games with complex structures, in high dimension or with common sources of randomness. In this chapter, we review the literature on the interplay between mean field games and deep learning, with a focus on three families of methods. A special emphasis is given to financial applications.
Policy Optimization for Linear-Quadratic Zero-Sum Mean-Field Type Games
Sep 02, 2020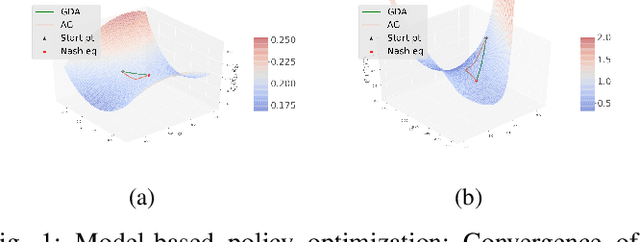
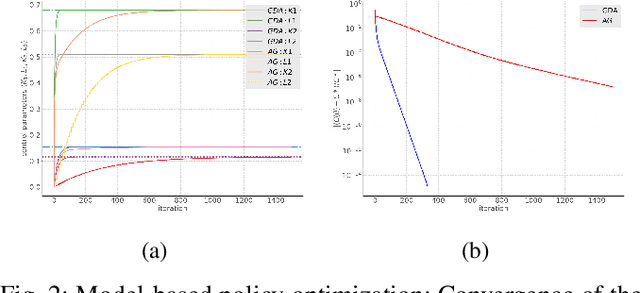
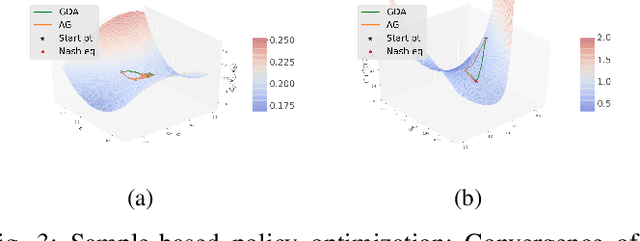
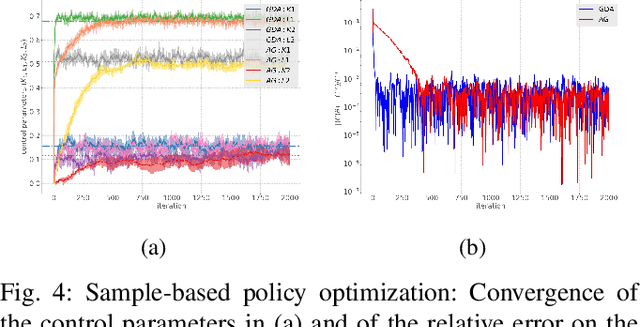
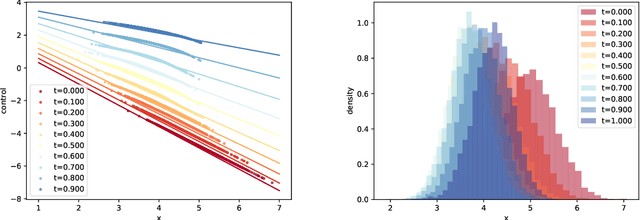
In this paper, zero-sum mean-field type games (ZSMFTG) with linear dynamics and quadratic utility are studied under infinite-horizon discounted utility function. ZSMFTG are a class of games in which two decision makers whose utilities sum to zero, compete to influence a large population of agents. In particular, the case in which the transition and utility functions depend on the state, the action of the controllers, and the mean of the state and the actions, is investigated. The game is analyzed and explicit expressions for the Nash equilibrium strategies are derived. Moreover, two policy optimization methods that rely on policy gradient are proposed for both model-based and sample-based frameworks. In the first case, the gradients are computed exactly using the model whereas they are estimated using Monte-Carlo simulations in the second case. Numerical experiments show the convergence of the two players' controls as well as the utility function when the two algorithms are used in different scenarios.
Linear-Quadratic Zero-Sum Mean-Field Type Games: Optimality Conditions and Policy Optimization
Sep 01, 2020
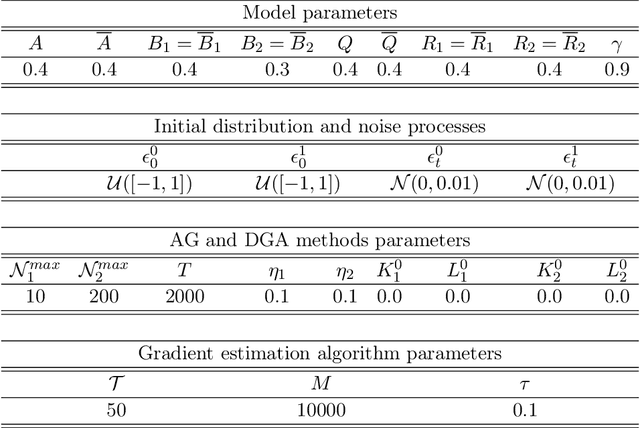
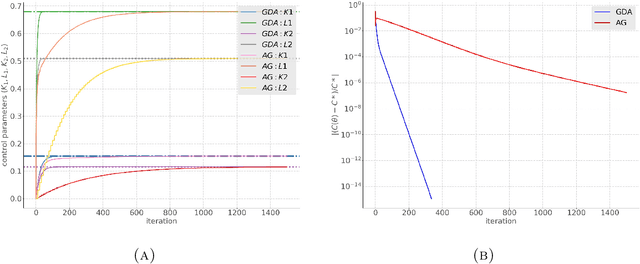
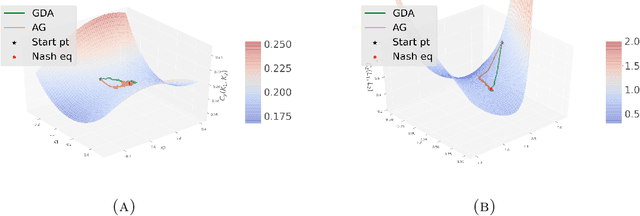
In this paper, zero-sum mean-field type games (ZSMFTG) with linear dynamics and quadratic cost are studied under infinite-horizon discounted utility function. ZSMFTG are a class of games in which two decision makers whose utilities sum to zero, compete to influence a large population of indistinguishable agents. In particular, the case in which the transition and utility functions depend on the state, the action of the controllers, and the mean of the state and the actions, is investigated. The optimality conditions of the game are analysed for both open-loop and closed-loop controls, and explicit expressions for the Nash equilibrium strategies are derived. Moreover, two policy optimization methods that rely on policy gradient are proposed for both model-based and sample-based frameworks. In the model-based case, the gradients are computed exactly using the model, whereas they are estimated using Monte-Carlo simulations in the sample-based case. Numerical experiments are conducted to show the convergence of the utility function as well as the two players' controls.
Model-Free Mean-Field Reinforcement Learning: Mean-Field MDP and Mean-Field Q-Learning
Oct 28, 2019


We develop a general reinforcement learning framework for mean field control (MFC) problems. Such problems arise for instance as the limit of collaborative multi-agent control problems when the number of agents is very large. The asymptotic problem can be phrased as the optimal control of a non-linear dynamics. This can also be viewed as a Markov decision process (MDP) but the key difference with the usual RL setup is that the dynamics and the reward now depend on the state's probability distribution itself. Alternatively, it can be recast as a MDP on the Wasserstein space of measures. In this work, we introduce generic model-free algorithms based on the state-action value function at the mean field level and we prove convergence for a prototypical Q-learning method. We then implement an actor-critic method and report numerical results on two archetypal problems: a finite space model motivated by a cyber security application and a continuous space model motivated by an application to swarm motion.
Linear-Quadratic Mean-Field Reinforcement Learning: Convergence of Policy Gradient Methods
Oct 09, 2019



We investigate reinforcement learning for mean field control problems in discrete time, which can be viewed as Markov decision processes for a large number of exchangeable agents interacting in a mean field manner. Such problems arise, for instance when a large number of robots communicate through a central unit dispatching the optimal policy computed by minimizing the overall social cost. An approximate solution is obtained by learning the optimal policy of a generic agent interacting with the statistical distribution of the states of the other agents. We prove rigorously the convergence of exact and model-free policy gradient methods in a mean-field linear-quadratic setting. We also provide graphical evidence of the convergence based on implementations of our algorithms.
Convergence Analysis of Machine Learning Algorithms for the Numerical Solution of Mean Field Control and Games: II -- The Finite Horizon Case
Aug 05, 2019


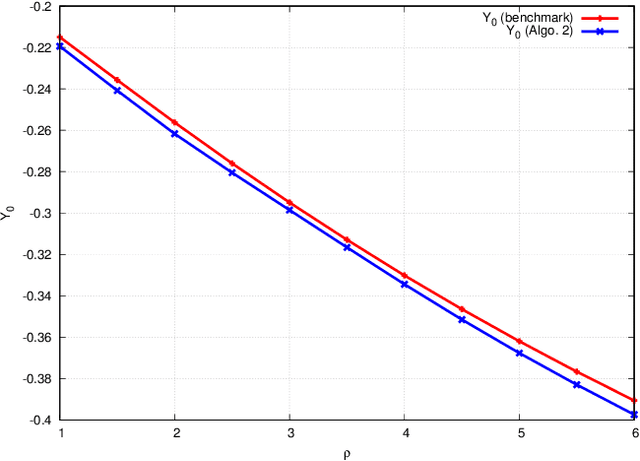
We propose two numerical methods for the optimal control of McKean-Vlasov dynamics in finite time horizon. Both methods are based on the introduction of a suitable loss function defined over the parameters of a neural network. This allows the use of machine learning tools, and efficient implementations of stochastic gradient descent in order to perform the optimization. In the first method, the loss function stems directly from the optimal control problem. We analyze the approximation and the estimation errors. The second method tackles a generic forward-backward stochastic differential equation system (FBSDE) of McKean-Vlasov type, and relies on suitable reformulation as a mean field control problem. To provide a guarantee on how our numerical schemes approximate the solution of the original mean field control problem, we introduce a new optimization problem, directly amenable to numerical computation, and for which we rigorously provide an error rate. Several numerical examples are provided. Both methods can easily be applied to problems with common noise, which is not the case with the existing technology. Furthermore, although the first approach is designed for mean field control problems, the second is more general and can also be applied to the FBSDE arising in the theory of mean field games.
Convergence Analysis of Machine Learning Algorithms for the Numerical Solution of Mean Field Control and Games: I -- The Ergodic Case
Jul 13, 2019



We propose two algorithms for the solution of the optimal control of ergodic McKean-Vlasov dynamics. Both algorithms are based on the approximation of the theoretical solutions by neural networks, the latter being characterized by their architecture and a set of parameters. This allows the use of modern machine learning tools, and efficient implementations of stochastic gradient descent. The first algorithm is based on the idiosyncrasies of the ergodic optimal control problem. We provide a mathematical proof of the convergence of the algorithm, and we analyze rigorously the approximation by controlling the different sources of error. The second method is an adaptation of the deep Galerkin method to the system of partial differential equations issued from the optimality condition. We demonstrate the efficiency of these algorithms on several numerical examples, some of them being chosen to show that our algorithms succeed where existing ones failed. We also argue that both methods can easily be applied to problems in dimensions larger than what can be found in the existing literature. Finally, we illustrate the fact that, although the first algorithm is specifically designed for mean field control problems, the second one is more general and can also be applied to the partial differential equation systems arising in the theory of mean field games.