 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Optimization for Linear-Quadratic Zero-Sum Mean-Field Type Games
Sep 02, 2020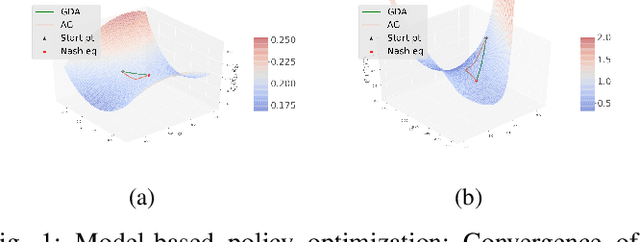
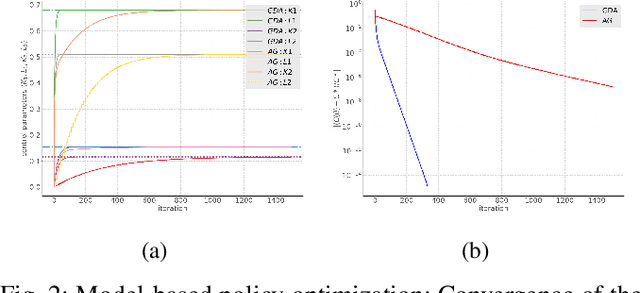
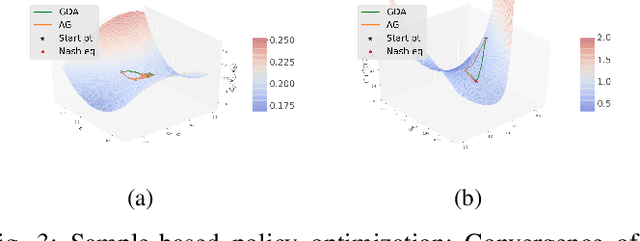
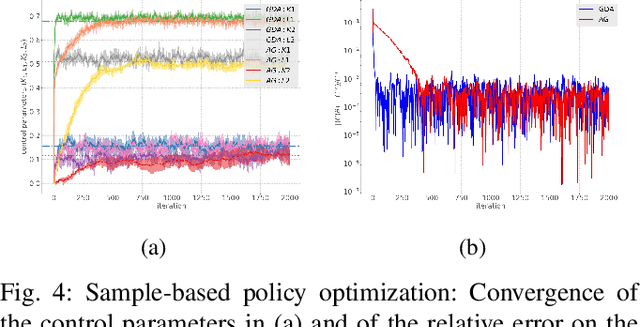
In this paper, zero-sum mean-field type games (ZSMFTG) with linear dynamics and quadratic utility are studied under infinite-horizon discounted utility function. ZSMFTG are a class of games in which two decision makers whose utilities sum to zero, compete to influence a large population of agents. In particular, the case in which the transition and utility functions depend on the state, the action of the controllers, and the mean of the state and the actions, is investigated. The game is analyzed and explicit expressions for the Nash equilibrium strategies are derived. Moreover, two policy optimization methods that rely on policy gradient are proposed for both model-based and sample-based frameworks. In the first case, the gradients are computed exactly using the model whereas they are estimated using Monte-Carlo simulations in the second case. Numerical experiments show the convergence of the two players' controls as well as the utility function when the two algorithms are used in different scenarios.
Linear-Quadratic Zero-Sum Mean-Field Type Games: Optimality Conditions and Policy Optimization
Sep 01, 2020
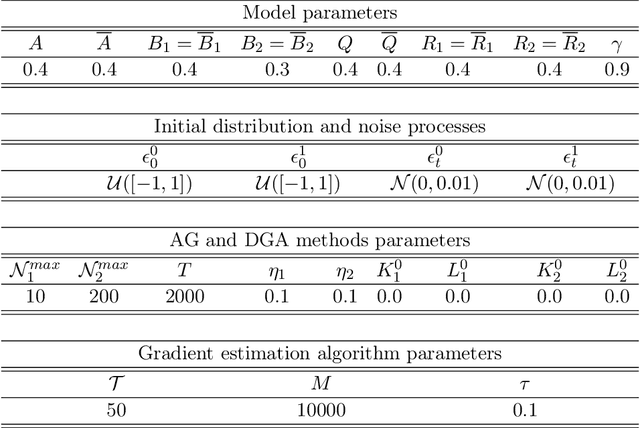
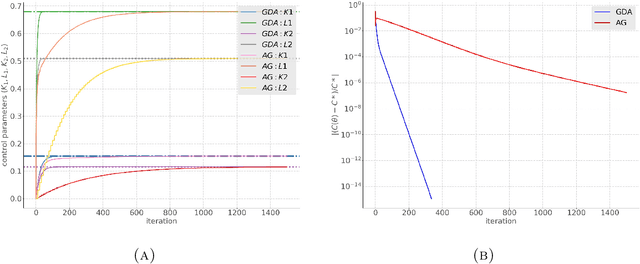
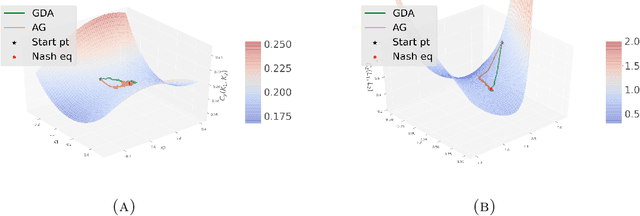
In this paper, zero-sum mean-field type games (ZSMFTG) with linear dynamics and quadratic cost are studied under infinite-horizon discounted utility function. ZSMFTG are a class of games in which two decision makers whose utilities sum to zero, compete to influence a large population of indistinguishable agents. In particular, the case in which the transition and utility functions depend on the state, the action of the controllers, and the mean of the state and the actions, is investigated. The optimality conditions of the game are analysed for both open-loop and closed-loop controls, and explicit expressions for the Nash equilibrium strategies are derived. Moreover, two policy optimization methods that rely on policy gradient are proposed for both model-based and sample-based frameworks. In the model-based case, the gradients are computed exactly using the model, whereas they are estimated using Monte-Carlo simulations in the sample-based case. Numerical experiments are conducted to show the convergence of the utility function as well as the two players' controls.
Model-Free Mean-Field Reinforcement Learning: Mean-Field MDP and Mean-Field Q-Learning
Oct 28, 2019


We develop a general reinforcement learning framework for mean field control (MFC) problems. Such problems arise for instance as the limit of collaborative multi-agent control problems when the number of agents is very large. The asymptotic problem can be phrased as the optimal control of a non-linear dynamics. This can also be viewed as a Markov decision process (MDP) but the key difference with the usual RL setup is that the dynamics and the reward now depend on the state's probability distribution itself. Alternatively, it can be recast as a MDP on the Wasserstein space of measures. In this work, we introduce generic model-free algorithms based on the state-action value function at the mean field level and we prove convergence for a prototypical Q-learning method. We then implement an actor-critic method and report numerical results on two archetypal problems: a finite space model motivated by a cyber security application and a continuous space model motivated by an application to swarm motion.
Linear-Quadratic Mean-Field Reinforcement Learning: Convergence of Policy Gradient Methods
Oct 09, 2019



We investigate reinforcement learning for mean field control problems in discrete time, which can be viewed as Markov decision processes for a large number of exchangeable agents interacting in a mean field manner. Such problems arise, for instance when a large number of robots communicate through a central unit dispatching the optimal policy computed by minimizing the overall social cost. An approximate solution is obtained by learning the optimal policy of a generic agent interacting with the statistical distribution of the states of the other agents. We prove rigorously the convergence of exact and model-free policy gradient methods in a mean-field linear-quadratic setting. We also provide graphical evidence of the convergence based on implementations of our algorithms.