 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Level Privacy in Large Language Models
Mar 05, 2025The use of language models as remote services requires transmitting private information to external providers, raising significant privacy concerns. This process not only risks exposing sensitive data to untrusted service providers but also leaves it vulnerable to interception by eavesdroppers. Existing privacy-preserving methods for natural language processing (NLP) interactions primarily rely on semantic similarity, overlooking the role of contextual information. In this work, we introduce dchi-stencil, a novel token-level privacy-preserving mechanism that integrates contextual and semantic information while ensuring strong privacy guarantees under the dchi differential privacy framework, achieving 2epsilon-dchi-privacy. By incorporating both semantic and contextual nuances, dchi-stencil achieves a robust balance between privacy and utility. We evaluate dchi-stencil using state-of-the-art language models and diverse datasets, achieving comparable and even better trade-off between utility and privacy compared to existing methods. This work highlights the potential of dchi-stencil to set a new standard for privacy-preserving NLP in modern, high-risk applications.
Protecting Privacy in Classifiers by Token Manipulation
Jul 01, 2024Using language models as a remote service entails sending private information to an untrusted provider. In addition, potential eavesdroppers can intercept the messages, thereby exposing the information. In this work, we explore the prospects of avoiding such data exposure at the level of text manipulation. We focus on text classification models, examining various token mapping and contextualized manipulation functions in order to see whether classifier accuracy may be maintained while keeping the original text unrecoverable. We find that although some token mapping functions are easy and straightforward to implement, they heavily influence performance on the downstream task, and via a sophisticated attacker can be reconstructed. In comparison, the contextualized manipulation provides an improvement in performance.
Learning to Parallelize in a Shared-Memory Environment with Transformers
Apr 27, 2022
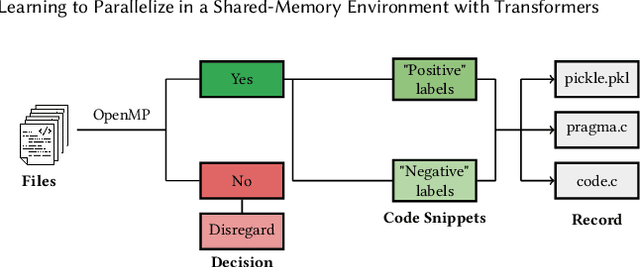

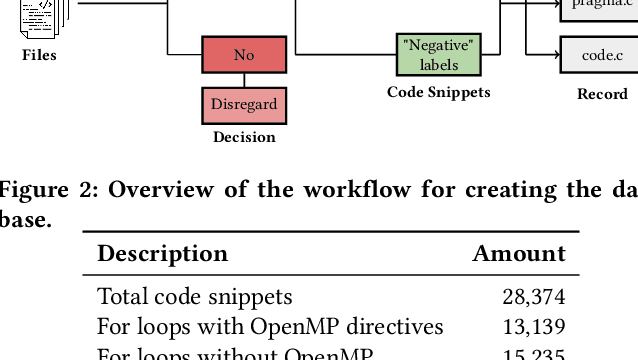
In past years, the world has switched to many-core and multi-core shared memory architectures. As a result, there is a growing need to utilize these architectures by introducing shared memory parallelization schemes to software applications. OpenMP is the most comprehensive API that implements such schemes, characterized by a readable interface. Nevertheless, introducing OpenMP into code is challenging due to pervasive pitfalls in management of parallel shared memory. To facilitate the performance of this task, many source-to-source (S2S) compilers have been created over the years, tasked with inserting OpenMP directives into code automatically. In addition to having limited robustness to their input format, these compilers still do not achieve satisfactory coverage and precision in locating parallelizable code and generating appropriate directives. In this work, we propose leveraging recent advances in ML techniques, specifically in natural language processing (NLP), to replace S2S compilers altogether. We create a database (corpus), Open-OMP, specifically for this goal. Open-OMP contains over 28,000 code snippets, half of which contain OpenMP directives while the other half do not need parallelization at all with high probability. We use the corpus to train systems to automatically classify code segments in need of parallelization, as well as suggest individual OpenMP clauses. We train several transformer models, named PragFormer, for these tasks, and show that they outperform statistically-trained baselines and automatic S2S parallelization compilers in both classifying the overall need for an OpenMP directive and the introduction of private and reduction clauses. Our source code and database are available at: https://github.com/Scientific-Computing-Lab-NRCN/PragFormer.
Complete CVDL Methodology for Investigating Hydrodynamic Instabilities
Apr 26, 2020
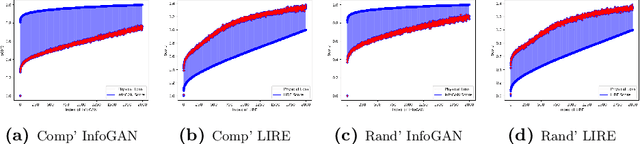

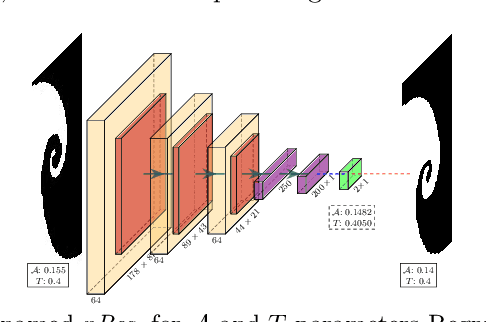
In fluid dynamics, one of the most important research fields is hydrodynamic instabilities and their evolution in different flow regimes. The investigation of said instabilities is concerned with the highly non-linear dynamics. Currently, three main methods are used for understanding of such phenomenon - namely analytical models, experiments and simulations - and all of them are primarily investigated and correlated using human expertise. In this work we claim and demonstrate that a major portion of this research effort could and should be analysed using recent breakthrough advancements in the field of Computer Vision with Deep Learning (CVDL, or Deep Computer-Vision). Specifically, we target and evaluate specific state-of-the-art techniques - such as Image Retrieval, Template Matching, Parameters Regression and Spatiotemporal Prediction - for the quantitative and qualitative benefits they provide. In order to do so we focus in this research on one of the most representative instabilities, the Rayleigh-Taylor one, simulate its behaviour and create an open-sourced state-of-the-art annotated database (RayleAI). Finally, we use adjusted experimental results and novel physical loss methodologies to validate the correspondence of the predicted results to actual physical reality to prove the models efficiency. The techniques which were developed and proved in this work can be served as essential tools for physicists in the field of hydrodynamics for investigating a variety of physical systems, and also could be used via Transfer Learning to other instabilities research. A part of the techniques can be easily applied on already exist simulation results. All models as well as the data-set that was created for this work, are publicly available at: https://github.com/scientific-computing-nrcn/SimulAI.