 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperational Wind Speed Forecasts for Chile's Electric Power Sector Using a Hybrid ML Model
Sep 17, 2024



As Chile's electric power sector advances toward a future powered by renewable energy, accurate forecasting of renewable generation is essential for managing grid operations. The integration of renewable energy sources is particularly challenging due to the operational difficulties of managing their power generation, which is highly variable compared to fossil fuel sources, delaying the availability of clean energy. To mitigate this, we quantify the impact of increasing intermittent generation from wind and solar on thermal power plants in Chile and introduce a hybrid wind speed forecasting methodology which combines two custom ML models for Chile. The first model is based on TiDE, an MLP-based ML model for short-term forecasts, and the second is based on a graph neural network, GraphCast, for medium-term forecasts up to 10 days. Our hybrid approach outperforms the most accurate operational deterministic systems by 4-21% for short-term forecasts and 5-23% for medium-term forecasts and can directly lower the impact of wind generation on thermal ramping, curtailment, and system-level emissions in Chile.
Sustainable AI: Environmental Implications, Challenges and Opportunities
Oct 30, 2021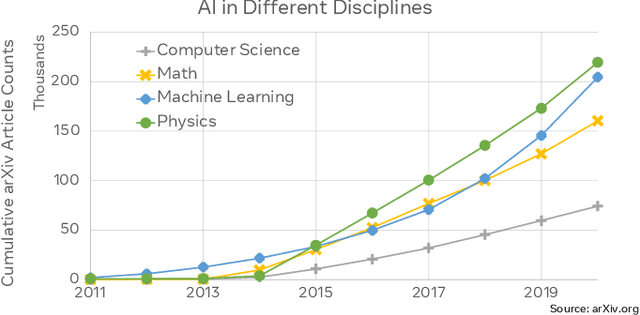
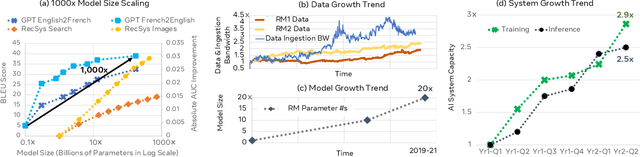
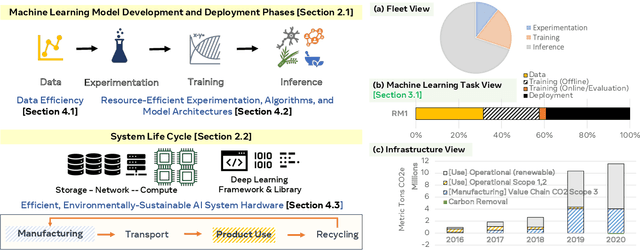
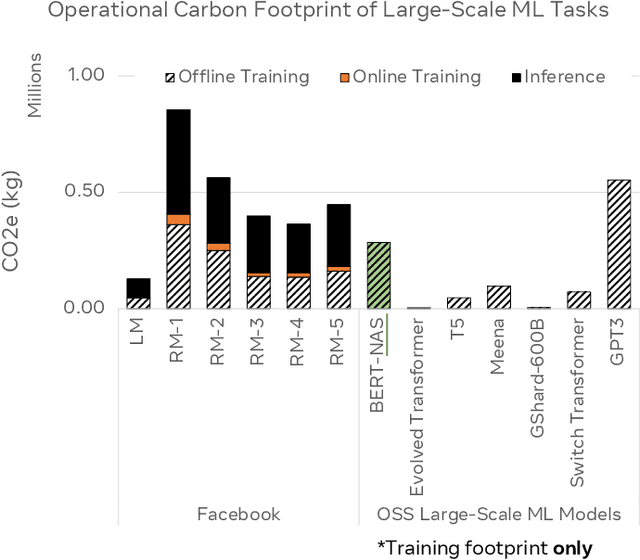
This paper explores the environmental impact of the super-linear growth trends for AI from a holistic perspective, spanning Data, Algorithms, and System Hardware. We characterize the carbon footprint of AI computing by examining the model development cycle across industry-scale machine learning use cases and, at the same time, considering the life cycle of system hardware. Taking a step further, we capture the operational and manufacturing carbon footprint of AI computing and present an end-to-end analysis for what and how hardware-software design and at-scale optimization can help reduce the overall carbon footprint of AI. Based on the industry experience and lessons learned, we share the key challenges and chart out important development directions across the many dimensions of AI. We hope the key messages and insights presented in this paper can inspire the community to advance the field of AI in an environmentally-responsible manner.
A Comparative Study of Fuzzy Classification Methods on Breast Cancer Data
May 04, 2004
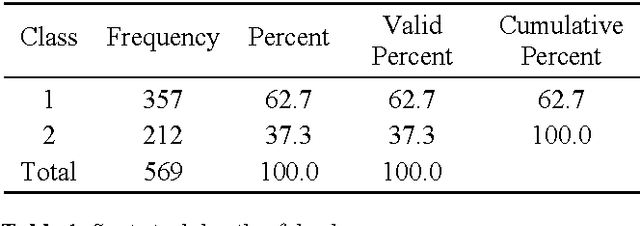

In this paper, we examine the performance of four fuzzy rule generation methods on Wisconsin breast cancer data. The first method generates fuzzy if then rules using the mean and the standard deviation of attribute values. The second approach generates fuzzy if then rules using the histogram of attributes values. The third procedure generates fuzzy if then rules with certainty of each attribute into homogeneous fuzzy sets. In the fourth approach, only overlapping areas are partitioned. The first two approaches generate a single fuzzy if then rule for each class by specifying the membership function of each antecedent fuzzy set using the information about attribute values of training patterns. The other two approaches are based on fuzzy grids with homogeneous fuzzy partitions of each attribute. The performance of each approach is evaluated on breast cancer data sets. Simulation results show that the Modified grid approach has a high classification rate of 99.73 %.