 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Shape of Beliefs: Geometry, Dynamics, and Interventions along Representation Manifolds of Language Models' Posteriors
Feb 02, 2026Large language models (LLMs) represent prompt-conditioned beliefs (posteriors over answers and claims), but we lack a mechanistic account of how these beliefs are encoded in representation space, how they update with new evidence, and how interventions reshape them. We study a controlled setting in which Llama-3.2 generates samples from a normal distribution by implicitly inferring its parameters (mean and standard deviation) given only samples from the distribution in context. We find representations of curved "belief manifolds" for these parameters form with sufficient in-context learning and study how the model adapts when the distribution suddenly changes. While standard linear steering often pushes the model off-manifold and induces coupled, out-of-distribution shifts, geometry and field-aware steering better preserves the intended belief family. Our work demonstrates an example of linear field probing (LFP) as a simple approach to tile the data manifold and make interventions that respect the underlying geometry. We conclude that rich structure emerges naturally in LLMs and that purely linear concept representations are often an inadequate abstraction.
Jacobian Scopes: token-level causal attributions in LLMs
Jan 23, 2026Large language models (LLMs) make next-token predictions based on clues present in their context, such as semantic descriptions and in-context examples. Yet, elucidating which prior tokens most strongly influence a given prediction remains challenging due to the proliferation of layers and attention heads in modern architectures. We propose Jacobian Scopes, a suite of gradient-based, token-level causal attribution methods for interpreting LLM predictions. By analyzing the linearized relations of final hidden state with respect to inputs, Jacobian Scopes quantify how input tokens influence a model's prediction. We introduce three variants - Semantic, Fisher, and Temperature Scopes - which respectively target sensitivity of specific logits, the full predictive distribution, and model confidence (inverse temperature). Through case studies spanning instruction understanding, translation and in-context learning (ICL), we uncover interesting findings, such as when Jacobian Scopes point to implicit political biases. We believe that our proposed methods also shed light on recently debated mechanisms underlying in-context time-series forecasting. Our code and interactive demonstrations are publicly available at https://github.com/AntonioLiu97/JacobianScopes.
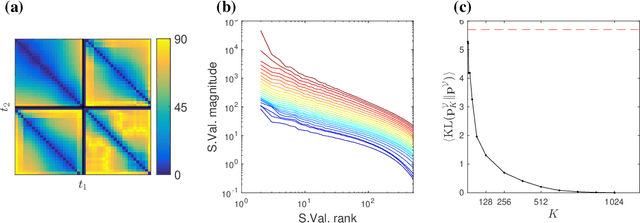
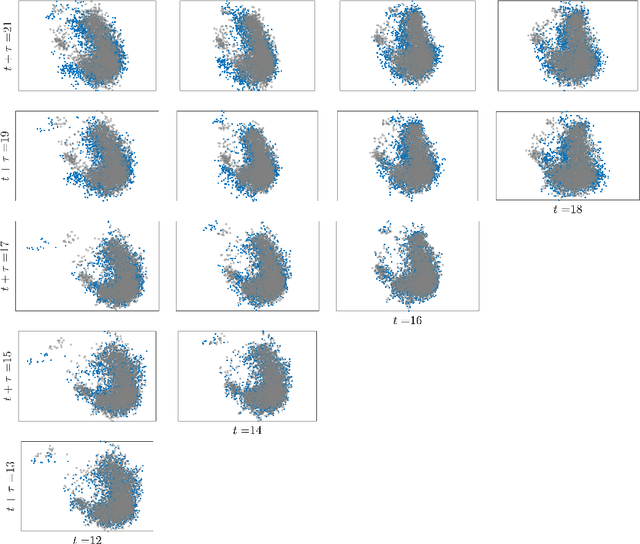
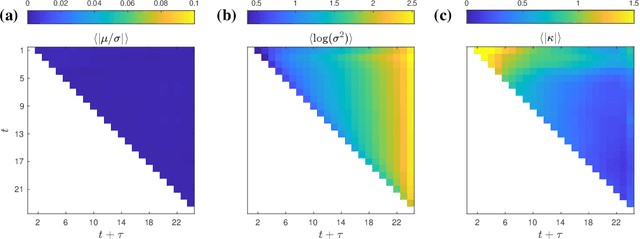
Density estimation with LLMs: a geometric investigation of in-context learning trajectories
Oct 07, 2024Large language models (LLMs) demonstrate remarkable emergent abilities to perform in-context learning across various tasks, including time series forecasting. This work investigates LLMs' ability to estimate probability density functions (PDFs) from data observed in-context; such density estimation (DE) is a fundamental task underlying many probabilistic modeling problems. We leverage the Intensive Principal Component Analysis (InPCA) to visualize and analyze the in-context learning dynamics of LLaMA-2 models. Our main finding is that these LLMs all follow similar learning trajectories in a low-dimensional InPCA space, which are distinct from those of traditional density estimation methods like histograms and Gaussian kernel density estimation (KDE). We interpret the LLaMA in-context DE process as a KDE with an adaptive kernel width and shape. This custom kernel model captures a significant portion of LLaMA's behavior despite having only two parameters. We further speculate on why LLaMA's kernel width and shape differs from classical algorithms, providing insights into the mechanism of in-context probabilistic reasoning in LLMs.
Lines of Thought in Large Language Models
Oct 02, 2024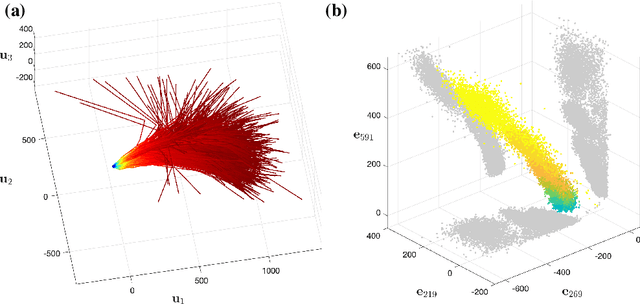
Large Language Models achieve next-token prediction by transporting a vectorized piece of text (prompt) across an accompanying embedding space under the action of successive transformer layers. The resulting high-dimensional trajectories realize different contextualization, or 'thinking', steps, and fully determine the output probability distribution. We aim to characterize the statistical properties of ensembles of these 'lines of thought.' We observe that independent trajectories cluster along a low-dimensional, non-Euclidean manifold, and that their path can be well approximated by a stochastic equation with few parameters extracted from data. We find it remarkable that the vast complexity of such large models can be reduced to a much simpler form, and we reflect on implications.
LLMs learn governing principles of dynamical systems, revealing an in-context neural scaling law
Feb 01, 2024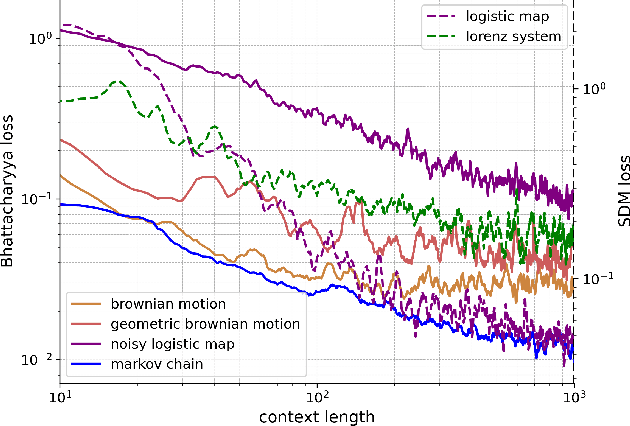
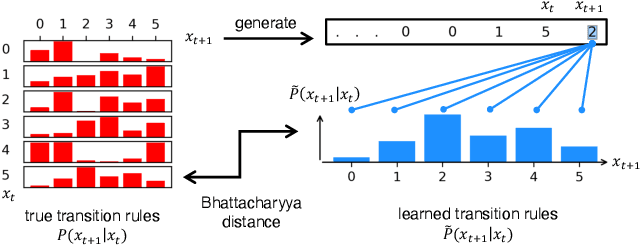
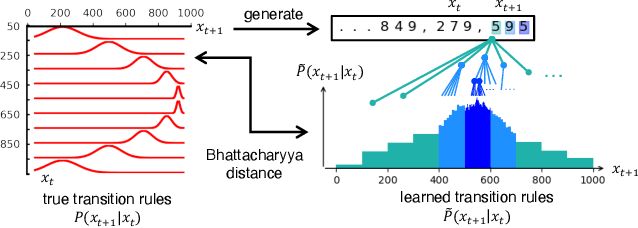
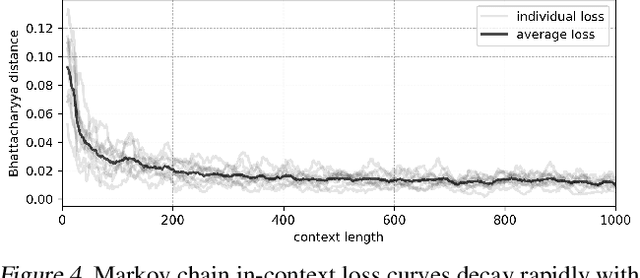
Pretrained large language models (LLMs) are surprisingly effective at performing zero-shot tasks, including time-series forecasting. However, understanding the mechanisms behind such capabilities remains highly challenging due to the complexity of the models. In this paper, we study LLMs' ability to extrapolate the behavior of dynamical systems whose evolution is governed by principles of physical interest. Our results show that LLaMA 2, a language model trained primarily on texts, achieves accurate predictions of dynamical system time series without fine-tuning or prompt engineering. Moreover, the accuracy of the learned physical rules increases with the length of the input context window, revealing an in-context version of neural scaling law. Along the way, we present a flexible and efficient algorithm for extracting probability density functions of multi-digit numbers directly from LLMs.