 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models and Weak Supervision for Social Media data annotation: an evaluation using COVID-19 self-reported vaccination tweets
Sep 12, 2023
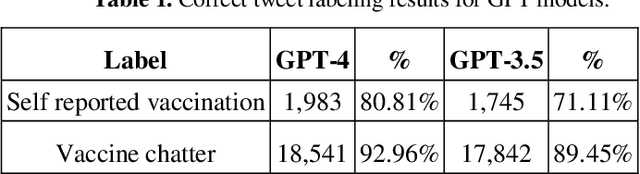

The COVID-19 pandemic has presented significant challenges to the healthcare industry and society as a whole. With the rapid development of COVID-19 vaccines, social media platforms have become a popular medium for discussions on vaccine-related topics. Identifying vaccine-related tweets and analyzing them can provide valuable insights for public health research-ers and policymakers. However, manual annotation of a large number of tweets is time-consuming and expensive. In this study, we evaluate the usage of Large Language Models, in this case GPT-4 (March 23 version), and weak supervision, to identify COVID-19 vaccine-related tweets, with the purpose of comparing performance against human annotators. We leveraged a manu-ally curated gold-standard dataset and used GPT-4 to provide labels without any additional fine-tuning or instructing, in a single-shot mode (no additional prompting).
TweetDIS: A Large Twitter Dataset for Natural Disasters Built using Weak Supervision
Jul 11, 2022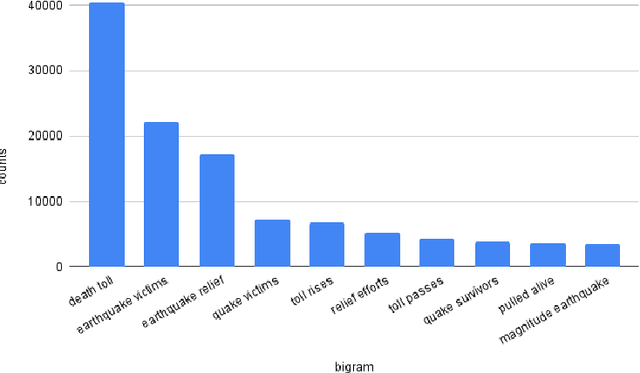
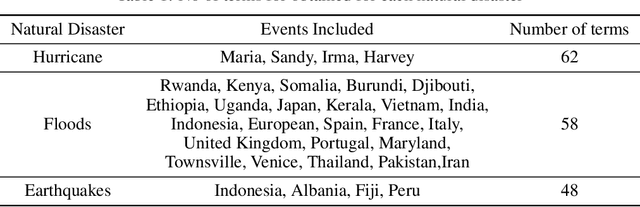
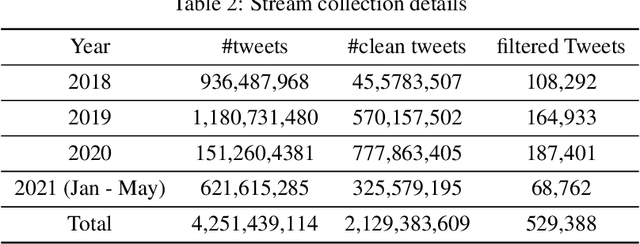
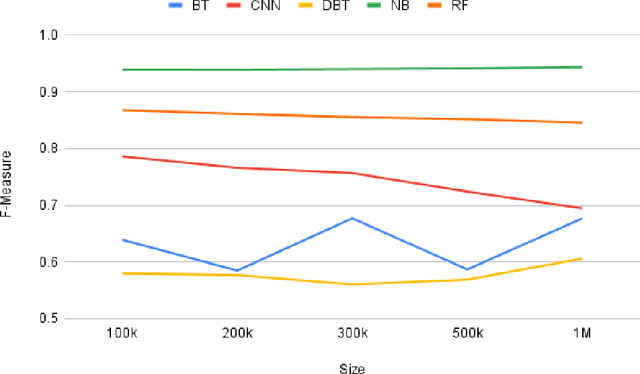
Social media is often utilized as a lifeline for communication during natural disasters. Traditionally, natural disaster tweets are filtered from the Twitter stream using the name of the natural disaster and the filtered tweets are sent for human annotation. The process of human annotation to create labeled sets for machine learning models is laborious, time consuming, at times inaccurate, and more importantly not scalable in terms of size and real-time use. In this work, we curate a silver standard dataset using weak supervision. In order to validate its utility, we train machine learning models on the weakly supervised data to identify three different types of natural disasters i.e earthquakes, hurricanes and floods. Our results demonstrate that models trained on the silver standard dataset achieved performance greater than 90% when classifying a manually curated, gold-standard dataset. To enable reproducible research and additional downstream utility, we release the silver standard dataset for the scientific community.
Characterization of Potential Drug Treatments for COVID-19 using Social Media Data and Machine Learning
Jul 20, 2020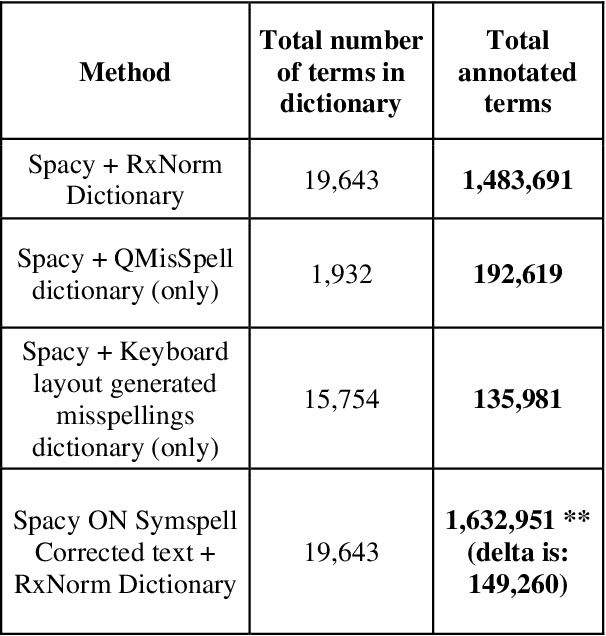
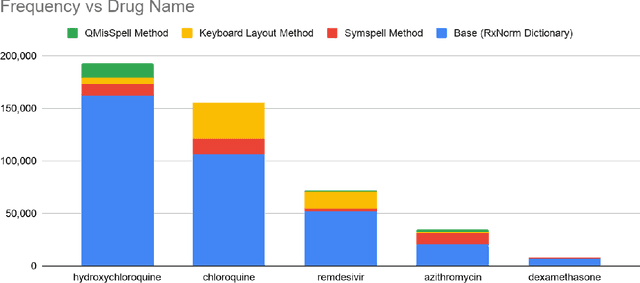
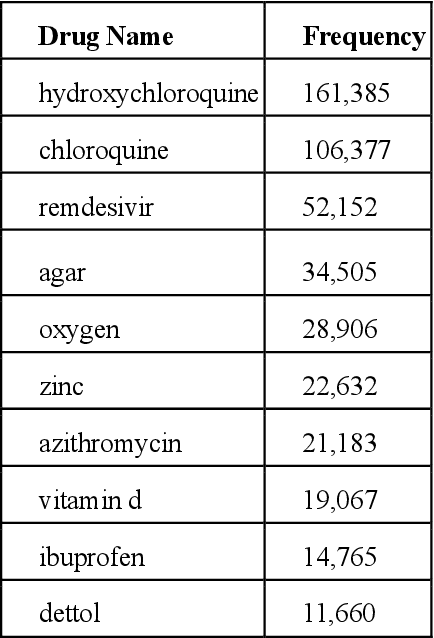
Since the classification of COVID-19 as a global pandemic, there have been many attempts to treat and contain the virus. Although there is no specific antiviral treatment recommended for COVID-19, there are several drugs that can potentially help with symptoms. In this work, we mined a large twitter dataset of 424 million tweets of COVID-19 chatter to identify discourse around potential treatments. While seemingly a straightforward task, due to the informal nature of language use in Twitter, we demonstrate the need of machine learning methods to aid in this task. By applying these methods we are able to recover almost 15% additional data than with traditional methods, showing the need of more sophisticated approaches than just text matching.