 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models and Weak Supervision for Social Media data annotation: an evaluation using COVID-19 self-reported vaccination tweets
Paper and Code
Sep 12, 2023
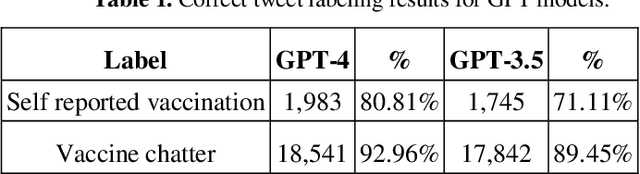

The COVID-19 pandemic has presented significant challenges to the healthcare industry and society as a whole. With the rapid development of COVID-19 vaccines, social media platforms have become a popular medium for discussions on vaccine-related topics. Identifying vaccine-related tweets and analyzing them can provide valuable insights for public health research-ers and policymakers. However, manual annotation of a large number of tweets is time-consuming and expensive. In this study, we evaluate the usage of Large Language Models, in this case GPT-4 (March 23 version), and weak supervision, to identify COVID-19 vaccine-related tweets, with the purpose of comparing performance against human annotators. We leveraged a manu-ally curated gold-standard dataset and used GPT-4 to provide labels without any additional fine-tuning or instructing, in a single-shot mode (no additional prompting).