 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTweetDIS: A Large Twitter Dataset for Natural Disasters Built using Weak Supervision
Paper and Code
Jul 11, 2022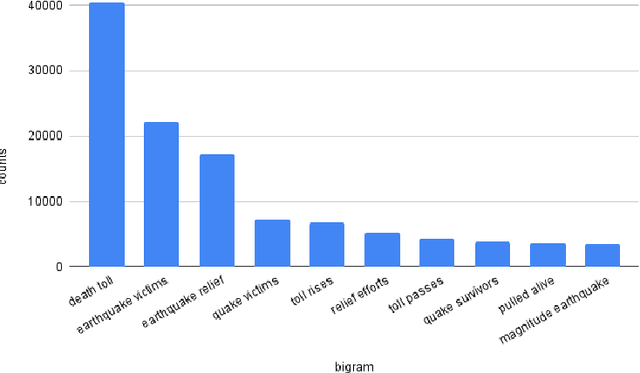
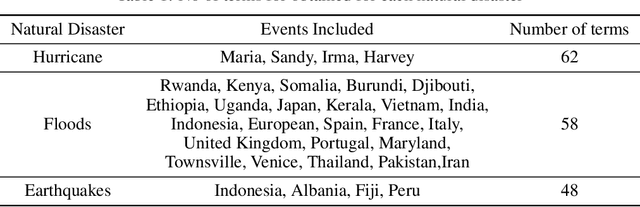
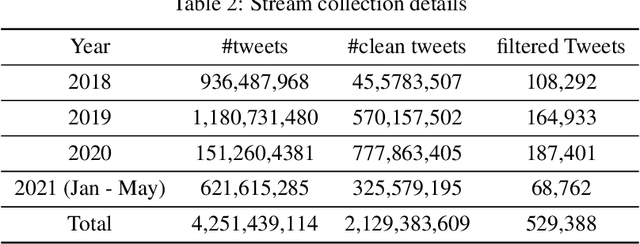
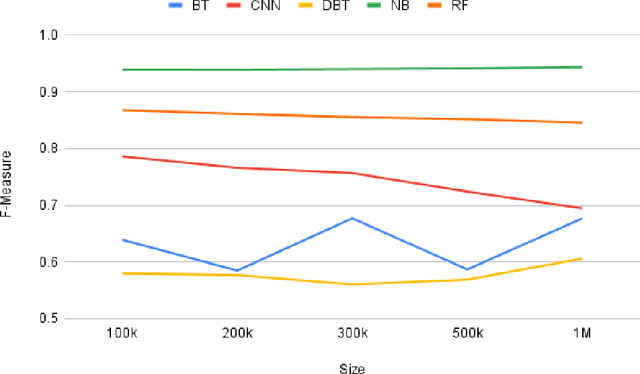
Social media is often utilized as a lifeline for communication during natural disasters. Traditionally, natural disaster tweets are filtered from the Twitter stream using the name of the natural disaster and the filtered tweets are sent for human annotation. The process of human annotation to create labeled sets for machine learning models is laborious, time consuming, at times inaccurate, and more importantly not scalable in terms of size and real-time use. In this work, we curate a silver standard dataset using weak supervision. In order to validate its utility, we train machine learning models on the weakly supervised data to identify three different types of natural disasters i.e earthquakes, hurricanes and floods. Our results demonstrate that models trained on the silver standard dataset achieved performance greater than 90% when classifying a manually curated, gold-standard dataset. To enable reproducible research and additional downstream utility, we release the silver standard dataset for the scientific community.