 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlue River Controls: A toolkit for Reinforcement Learning Control Systems on Hardware
Jan 07, 2020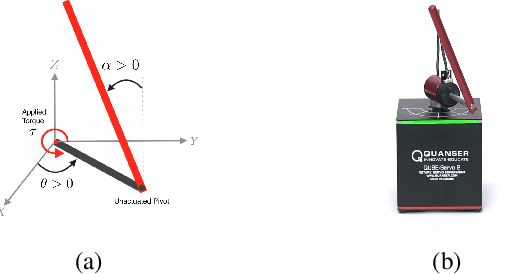
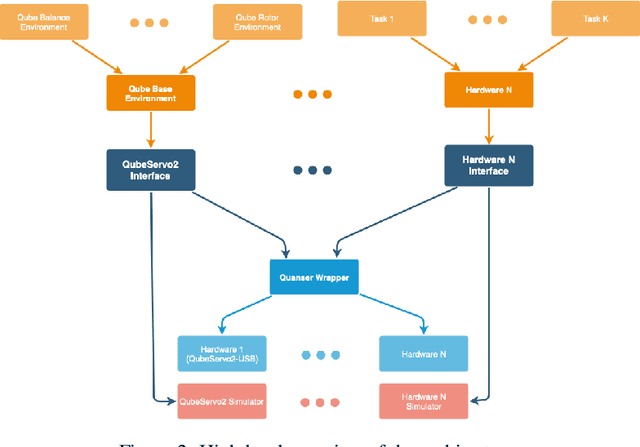
We provide a simple hardware wrapper around the Quanser's hardware-in-the-loop software development kit (HIL SDK) to allow for easy development of new Quanser hardware. To connect to the hardware we use a module written in Cython. The internal QuanserWrapper class handles most of the difficult aspects of interacting with hardware, including the timing (using a hardware timer), and ensuring the data sent to hardware is safe and correct, where safety corresponds to safe operating voltage and current for the specified hardware. Much of the recent success of Reinforcement learning (RL) has been made possible with training and testing tools like OpenAI Gym and Deepmind Control Suite. Unfortunately, tools for quickly testing and transferring high-frequency RL algorithms from simulation to real hardware environment remain mostly absent. We present Blue River Controls, a tool that allows to train and test reinforcement learning algorithms on real-world hardware. It features a simple interface based on OpenAI Gym, that works directly on both simulation and hardware. We use Quanser's Qube Servo2-USB platform, an underactuated rotary pendulum as an initial testing device. We also provide tools to simplify training RL algorithms on other hardware. Several baselines, from both classical controllers and pretrained RL agents are included to compare performance across tasks. Blue River Controls is available at this https URL: https://github.com/BlueRiverTech/quanser-openai-driver
Transparency and Explanation in Deep Reinforcement Learning Neural Networks
Sep 17, 2018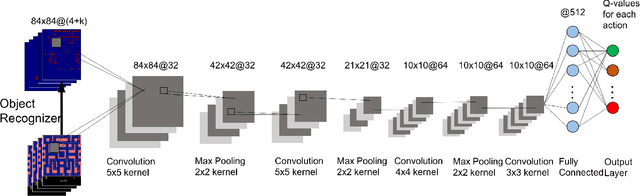


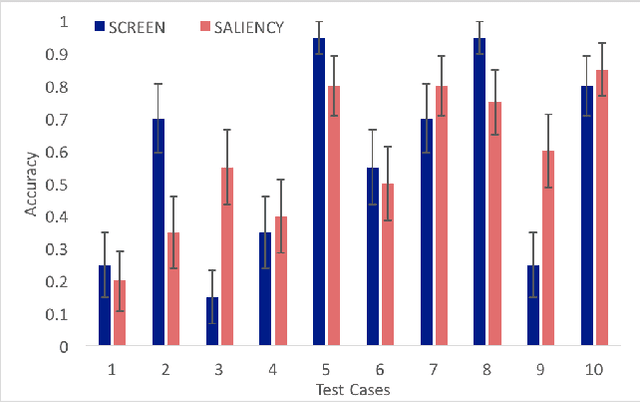
Autonomous AI systems will be entering human society in the near future to provide services and work alongside humans. For those systems to be accepted and trusted, the users should be able to understand the reasoning process of the system, i.e. the system should be transparent. System transparency enables humans to form coherent explanations of the system's decisions and actions. Transparency is important not only for user trust, but also for software debugging and certification. In recent years, Deep Neural Networks have made great advances in multiple application areas. However, deep neural networks are opaque. In this paper, we report on work in transparency in Deep Reinforcement Learning Networks (DRLN). Such networks have been extremely successful in accurately learning action control in image input domains, such as Atari games. In this paper, we propose a novel and general method that (a) incorporates explicit object recognition processing into deep reinforcement learning models, (b) forms the basis for the development of "object saliency maps", to provide visualization of internal states of DRLNs, thus enabling the formation of explanations and (c) can be incorporated in any existing deep reinforcement learning framework. We present computational results and human experiments to evaluate our approach.