 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchAlign3D: Local Feature Alignment for Dense 3D Shape understanding
Jan 05, 2026Current foundation models for 3D shapes excel at global tasks (retrieval, classification) but transfer poorly to local part-level reasoning. Recent approaches leverage vision and language foundation models to directly solve dense tasks through multi-view renderings and text queries. While promising, these pipelines require expensive inference over multiple renderings, depend heavily on large language-model (LLM) prompt engineering for captions, and fail to exploit the inherent 3D geometry of shapes. We address this gap by introducing an encoder-only 3D model that produces language-aligned patch-level features directly from point clouds. Our pre-training approach builds on existing data engines that generate part-annotated 3D shapes by pairing multi-view SAM regions with VLM captioning. Using this data, we train a point cloud transformer encoder in two stages: (1) distillation of dense 2D features from visual encoders such as DINOv2 into 3D patches, and (2) alignment of these patch embeddings with part-level text embeddings through a multi-positive contrastive objective. Our 3D encoder achieves zero-shot 3D part segmentation with fast single-pass inference without any test-time multi-view rendering, while significantly outperforming previous rendering-based and feed-forward approaches across several 3D part segmentation benchmarks. Project website: https://souhail-hadgi.github.io/patchalign3dsite/
Self-Supervised Dual Contouring
May 28, 2024



Learning-based isosurface extraction methods have recently emerged as a robust and efficient alternative to axiomatic techniques. However, the vast majority of such approaches rely on supervised training with axiomatically computed ground truths, thus potentially inheriting biases and data artifacts of the corresponding axiomatic methods. Steering away from such dependencies, we propose a self-supervised training scheme for the Neural Dual Contouring meshing framework, resulting in our method: Self-Supervised Dual Contouring (SDC). Instead of optimizing predicted mesh vertices with supervised training, we use two novel self-supervised loss functions that encourage the consistency between distances to the generated mesh up to the first order. Meshes reconstructed by SDC surpass existing data-driven methods in capturing intricate details while being more robust to possible irregularities in the input. Furthermore, we use the same self-supervised training objective linking inferred mesh and input SDF, to regularize the training process of Deep Implicit Networks (DINs). We demonstrate that the resulting DINs produce higher-quality implicit functions, ultimately leading to more accurate and detail-preserving surfaces compared to prior baselines for different input modalities. Finally, we demonstrate that our self-supervised losses improve meshing performance in the single-view reconstruction task by enabling joint training of predicted SDF and resulting output mesh. We open-source our code at https://github.com/Sentient07/SDC
Reduced Representation of Deformation Fields for Effective Non-rigid Shape Matching
Nov 26, 2022



In this work we present a novel approach for computing correspondences between non-rigid objects, by exploiting a reduced representation of deformation fields. Different from existing works that represent deformation fields by training a general-purpose neural network, we advocate for an approximation based on mesh-free methods. By letting the network learn deformation parameters at a sparse set of positions in space (nodes), we reconstruct the continuous deformation field in a closed-form with guaranteed smoothness. With this reduction in degrees of freedom, we show significant improvement in terms of data-efficiency thus enabling limited supervision. Furthermore, our approximation provides direct access to first-order derivatives of deformation fields, which facilitates enforcing desirable regularization effectively. Our resulting model has high expressive power and is able to capture complex deformations. We illustrate its effectiveness through state-of-the-art results across multiple deformable shape matching benchmarks. Our code and data are publicly available at: https://github.com/Sentient07/DeformationBasis.
Implicit field supervision for robust non-rigid shape matching
Mar 16, 2022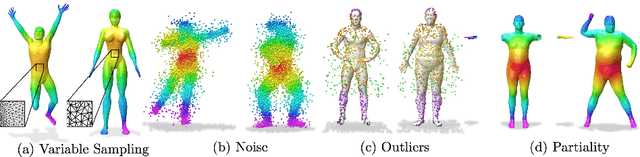
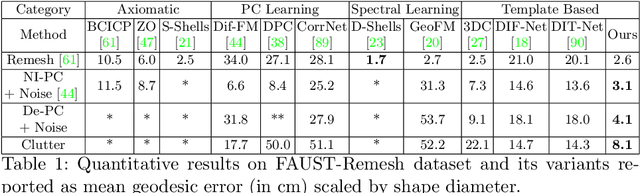
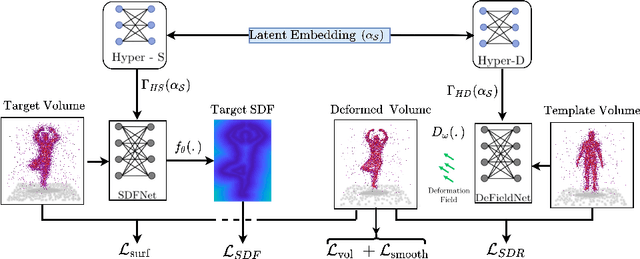
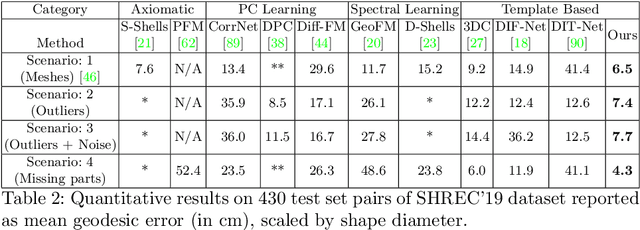
Establishing a correspondence between two non-rigidly deforming shapes is one of the most fundamental problems in visual computing. Existing methods often show weak resilience when presented with challenges innate to real-world data such as noise, outliers, self-occlusion etc. On the other hand, auto-decoders have demonstrated strong expressive power in learning geometrically meaningful latent embeddings. However, their use in shape analysis and especially in non-rigid shape correspondence has been limited. In this paper, we introduce an approach based on auto-decoder framework, that learns a continuous shape-wise deformation field over a fixed template. By supervising the deformation field for points on-surface and regularising for points off-surface through a novel Signed Distance Regularisation (SDR), we learn an alignment between the template and shape volumes. Unlike classical correspondence techniques, our method is remarkably robust in the presence of strong artefacts and can be generalised to arbitrary shape categories. Trained on clean water-tight meshes, without any data-augmentation, we demonstrate compelling performance on compromised data and real-world scans.
Tracking Pedestrian Heads in Dense Crowd
Mar 24, 2021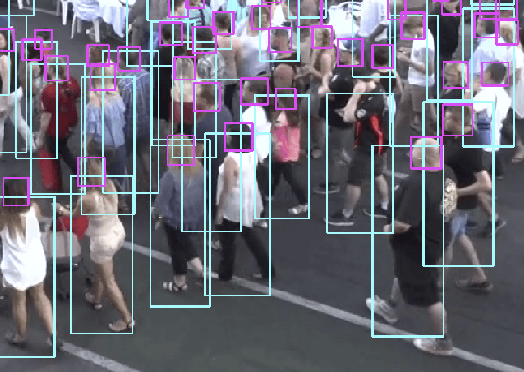
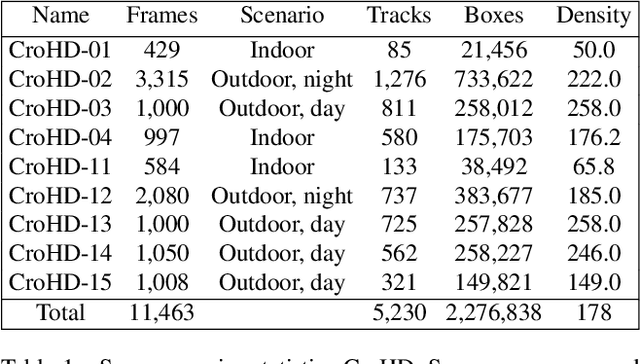

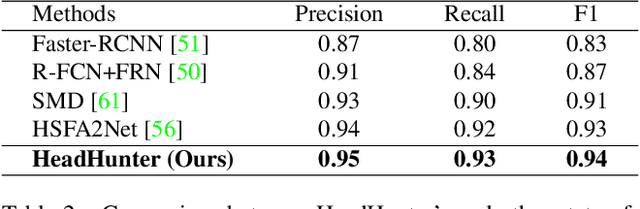
Tracking humans in crowded video sequences is an important constituent of visual scene understanding. Increasing crowd density challenges visibility of humans, limiting the scalability of existing pedestrian trackers to higher crowd densities. For that reason, we propose to revitalize head tracking with Crowd of Heads Dataset (CroHD), consisting of 9 sequences of 11,463 frames with over 2,276,838 heads and 5,230 tracks annotated in diverse scenes. For evaluation, we proposed a new metric, IDEucl, to measure an algorithm's efficacy in preserving a unique identity for the longest stretch in image coordinate space, thus building a correspondence between pedestrian crowd motion and the performance of a tracking algorithm. Moreover, we also propose a new head detector, HeadHunter, which is designed for small head detection in crowded scenes. We extend HeadHunter with a Particle Filter and a color histogram based re-identification module for head tracking. To establish this as a strong baseline, we compare our tracker with existing state-of-the-art pedestrian trackers on CroHD and demonstrate superiority, especially in identity preserving tracking metrics. With a light-weight head detector and a tracker which is efficient at identity preservation, we believe our contributions will serve useful in advancement of pedestrian tracking in dense crowds.