 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubject-independent Classification of Meditative State from the Resting State using EEG
Apr 25, 2025While it is beneficial to objectively determine whether a subject is meditating, most research in the literature reports good results only in a subject-dependent manner. This study aims to distinguish the modified state of consciousness experienced during Rajyoga meditation from the resting state of the brain in a subject-independent manner using EEG data. Three architectures have been proposed and evaluated: The CSP-LDA Architecture utilizes common spatial pattern (CSP) for feature extraction and linear discriminant analysis (LDA) for classification. The CSP-LDA-LSTM Architecture employs CSP for feature extraction, LDA for dimensionality reduction, and long short-term memory (LSTM) networks for classification, modeling the binary classification problem as a sequence learning problem. The SVD-NN Architecture uses singular value decomposition (SVD) to select the most relevant components of the EEG signals and a shallow neural network (NN) for classification. The CSP-LDA-LSTM architecture gives the best performance with 98.2% accuracy for intra-subject classification. The SVD-NN architecture provides significant performance with 96.4\% accuracy for inter-subject classification. This is comparable to the best-reported accuracies in the literature for intra-subject classification. Both architectures are capable of capturing subject-invariant EEG features for effectively classifying the meditative state from the resting state. The high intra-subject and inter-subject classification accuracies indicate these systems' robustness and their ability to generalize across different subjects.
Low-Resource End-to-end Sanskrit TTS using Tacotron2, WaveGlow and Transfer Learning
Dec 07, 2022End-to-end text-to-speech (TTS) systems have been developed for European languages like English and Spanish with state-of-the-art speech quality, prosody, and naturalness. However, development of end-to-end TTS for Indian languages is lagging behind in terms of quality. The challenges involved in such a task are: 1) scarcity of quality training data; 2) low efficiency during training and inference; 3) slow convergence in the case of large vocabulary size. In our work reported in this paper, we have investigated the use of fine-tuning the English-pretrained Tacotron2 model with limited Sanskrit data to synthesize natural sounding speech in Sanskrit in low resource settings. Our experiments show encouraging results, achieving an overall MOS of 3.38 from 37 evaluators with good Sanskrit spoken knowledge. This is really a very good result, considering the fact that the speech data we have used is of duration 2.5 hours only.
Functional Connectivity Methods for EEG-based Biometrics on a Large, Heterogeneous Dataset
Jun 03, 2022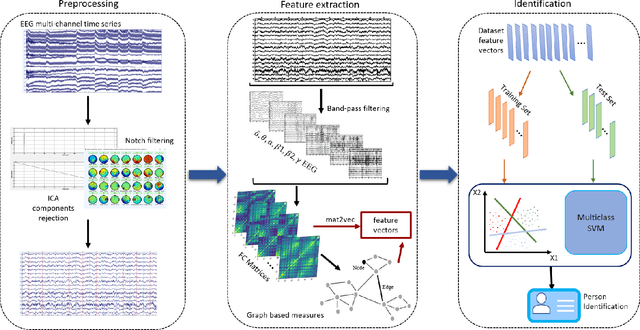
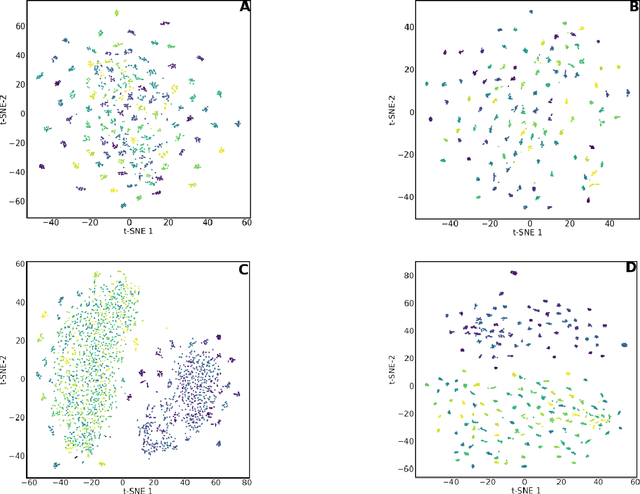
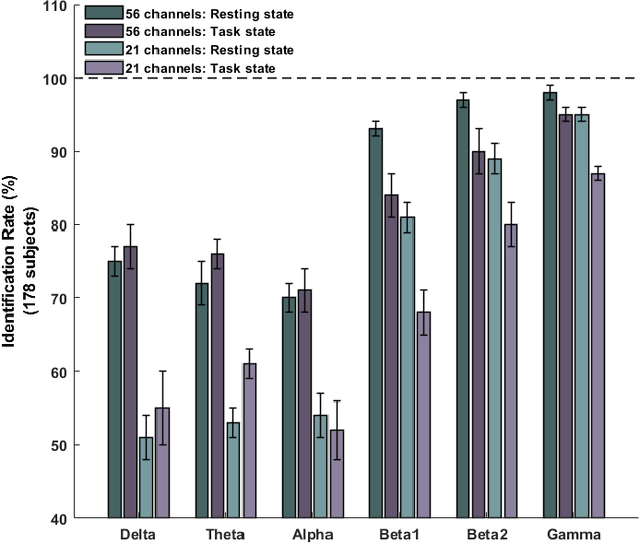
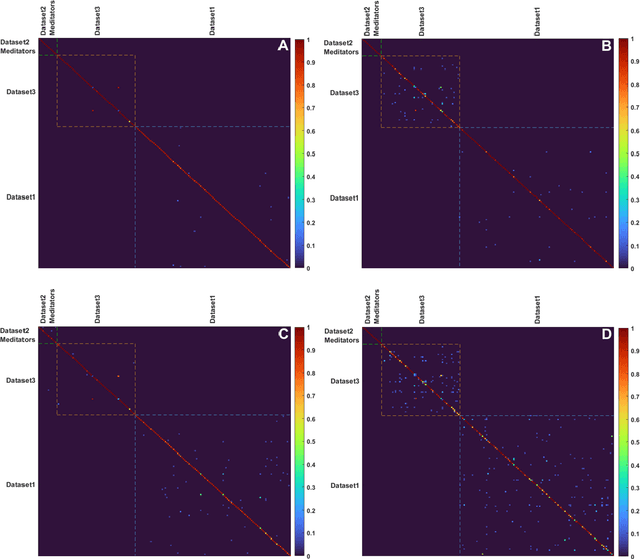
This study examines the utility of functional connectivity (FC) and graph-based (GB) measures with a support vector machine classifier for use in electroencephalogram (EEG) based biometrics. Although FC-based features have been used in biometric applications, studies assessing the identification algorithms on heterogeneous and large datasets are scarce. This work investigates the performance of FC and GB metrics on a dataset of 184 subjects formed by pooling three datasets recorded under different protocols and acquisition systems. The results demonstrate the higher discriminatory power of FC than GB metrics. The identification accuracy increases with higher frequency EEG bands, indicating the enhanced uniqueness of the neural signatures in beta and gamma bands. Using all the 56 EEG channels common to the three databases, the best identification accuracy of 97.4% is obtained using phase-locking value (PLV) based measures extracted from the gamma frequency band. Further, we investigate the effect of the length of the analysis epoch to determine the data acquisition time required to obtain satisfactory identification accuracy. When the number of channels is reduced to 21 from 56, there is a marginal reduction of 2.4% only in the identification accuracy using PLV features in the gamma band. Additional experiments have been conducted to study the effect of the cognitive state of the subject and mismatched train/test conditions on the performance of the system.
Data and knowledge-driven approaches for multilingual training to improve the performance of speech recognition systems of Indian languages
Jan 24, 2022

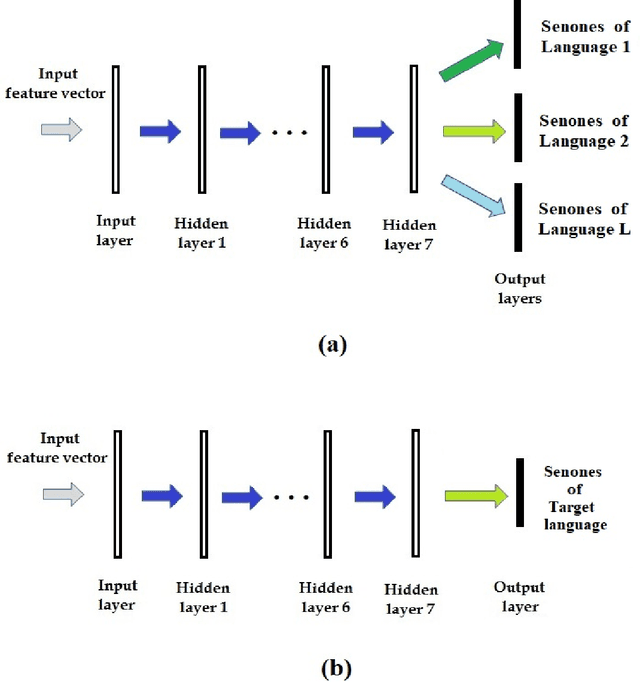
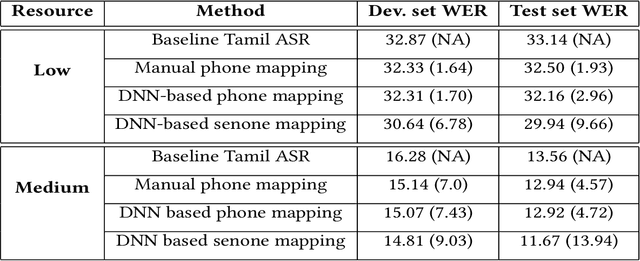
We propose data and knowledge-driven approaches for multilingual training of the automated speech recognition (ASR) system for a target language by pooling speech data from multiple source languages. Exploiting the acoustic similarities between Indian languages, we implement two approaches. In phone/senone mapping, deep neural network (DNN) learns to map senones or phones from one language to the others, and the transcriptions of the source languages are modified such that they can be used along with the target language data to train and fine-tune the target language ASR system. In the other approach, we model the acoustic information for all the languages simultaneously by training a multitask DNN (MTDNN) to predict the senones of each language in different output layers. The cross-entropy loss and the weight update procedure are modified such that only the shared layers and the output layer responsible for predicting the senone classes of a language are updated during training, if the feature vector belongs to that particular language. In the low-resource setting (LRS), 40 hours of transcribed data each for Tamil, Telugu and Gujarati languages are used for training. The DNN based senone mapping technique gives relative improvements in word error rates (WER) of 9.66%, 7.2% and 15.21% over the baseline system for Tamil, Gujarati and Telugu languages, respectively. In medium-resourced setting (MRS), 160, 275 and 135 hours of data for Tamil, Kannada and Hindi languages are used, where, the same technique gives better relative improvements of 13.94%, 10.28% and 27.24% for Tamil, Kannada and Hindi, respectively. The MTDNN with senone mapping based training in LRS, gives higher relative WER improvements of 15.0%, 17.54% and 16.06%, respectively for Tamil, Gujarati and Telugu, whereas in MRS, we see improvements of 21.24% 21.05% and 30.17% for Tamil, Kannada and Hindi languages, respectively.