 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData and knowledge-driven approaches for multilingual training to improve the performance of speech recognition systems of Indian languages
Jan 24, 2022

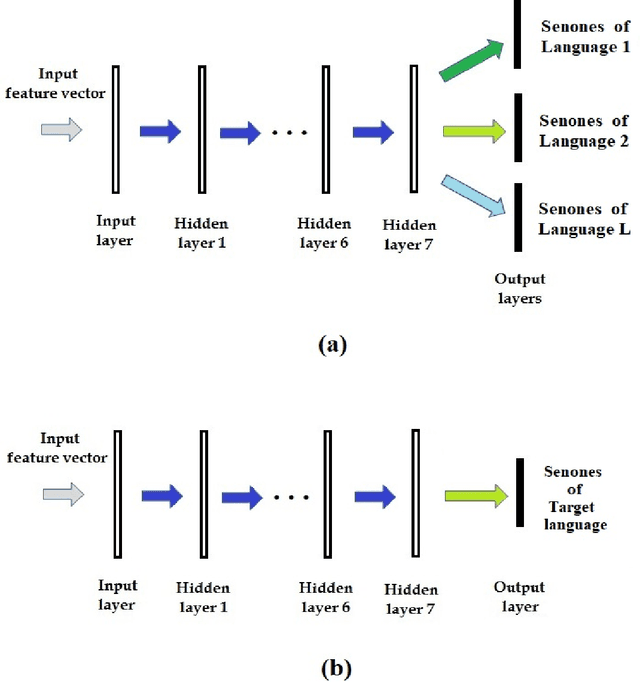
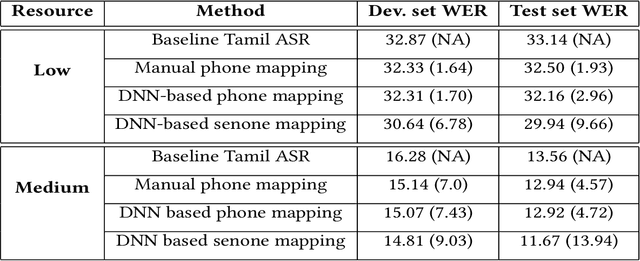
We propose data and knowledge-driven approaches for multilingual training of the automated speech recognition (ASR) system for a target language by pooling speech data from multiple source languages. Exploiting the acoustic similarities between Indian languages, we implement two approaches. In phone/senone mapping, deep neural network (DNN) learns to map senones or phones from one language to the others, and the transcriptions of the source languages are modified such that they can be used along with the target language data to train and fine-tune the target language ASR system. In the other approach, we model the acoustic information for all the languages simultaneously by training a multitask DNN (MTDNN) to predict the senones of each language in different output layers. The cross-entropy loss and the weight update procedure are modified such that only the shared layers and the output layer responsible for predicting the senone classes of a language are updated during training, if the feature vector belongs to that particular language. In the low-resource setting (LRS), 40 hours of transcribed data each for Tamil, Telugu and Gujarati languages are used for training. The DNN based senone mapping technique gives relative improvements in word error rates (WER) of 9.66%, 7.2% and 15.21% over the baseline system for Tamil, Gujarati and Telugu languages, respectively. In medium-resourced setting (MRS), 160, 275 and 135 hours of data for Tamil, Kannada and Hindi languages are used, where, the same technique gives better relative improvements of 13.94%, 10.28% and 27.24% for Tamil, Kannada and Hindi, respectively. The MTDNN with senone mapping based training in LRS, gives higher relative WER improvements of 15.0%, 17.54% and 16.06%, respectively for Tamil, Gujarati and Telugu, whereas in MRS, we see improvements of 21.24% 21.05% and 30.17% for Tamil, Kannada and Hindi languages, respectively.