 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Soft-Domain Transfer and Named Entity Information on Deception Detection
Oct 18, 2024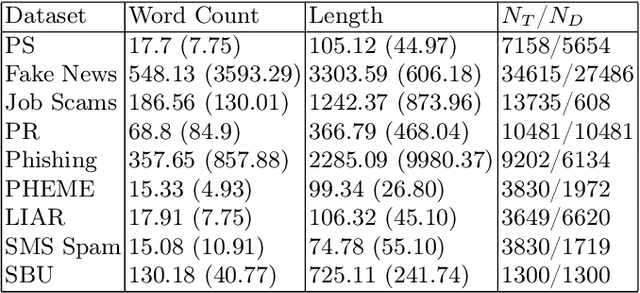
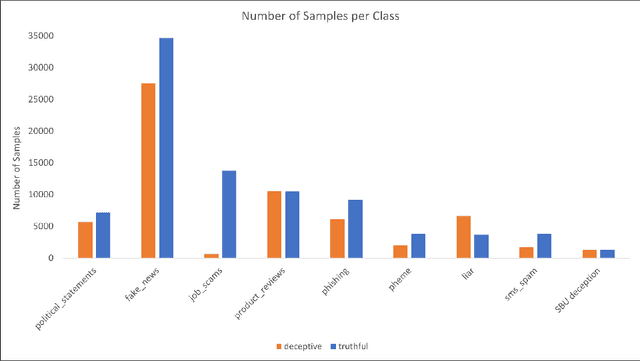
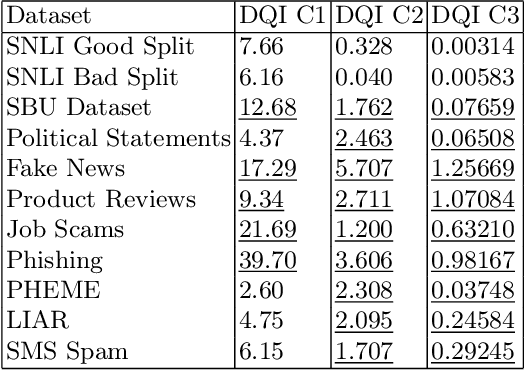

In the modern age an enormous amount of communication occurs online, and it is difficult to know when something written is genuine or deceitful. There are many reasons for someone to deceive online (e.g., monetary gain, political gain) and detecting this behavior without any physical interaction is a difficult task. Additionally, deception occurs in several text-only domains and it is unclear if these various sources can be leveraged to improve detection. To address this, eight datasets were utilized from various domains to evaluate their effect on classifier performance when combined with transfer learning via intermediate layer concatenation of fine-tuned BERT models. We find improvements in accuracy over the baseline. Furthermore, we evaluate multiple distance measurements between datasets and find that Jensen-Shannon distance correlates moderately with transfer learning performance. Finally, the impact was evaluated of multiple methods, which produce additional information in a dataset's text via named entities, on BERT performance and we find notable improvement in accuracy of up to 11.2%.
Experiments in Extractive Summarization: Integer Linear Programming, Term/Sentence Scoring, and Title-driven Models
Aug 01, 2020
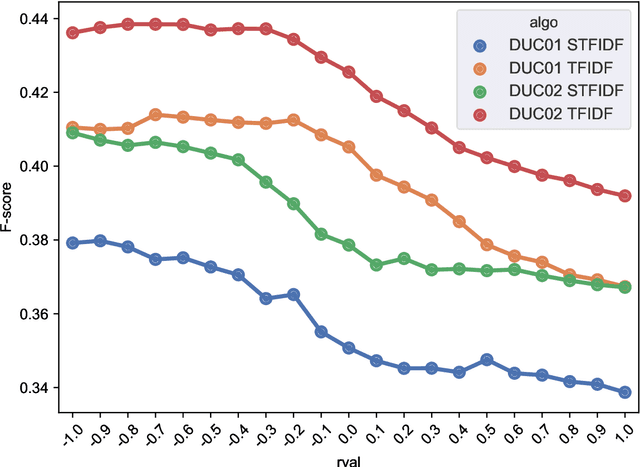

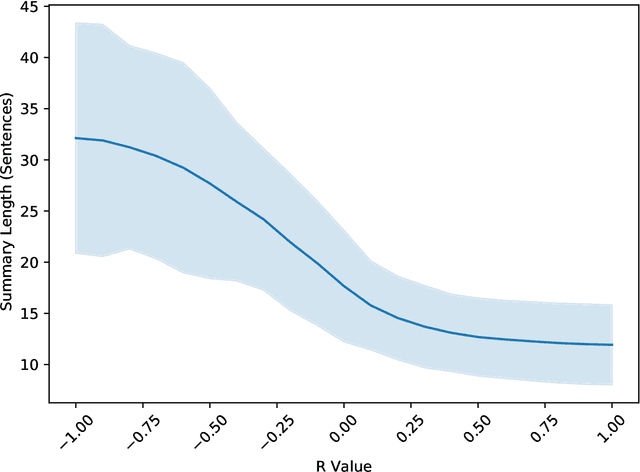
In this paper, we revisit the challenging problem of unsupervised single-document summarization and study the following aspects: Integer linear programming (ILP) based algorithms, Parameterized normalization of term and sentence scores, and Title-driven approaches for summarization. We describe a new framework, NewsSumm, that includes many existing and new approaches for summarization including ILP and title-driven approaches. NewsSumm's flexibility allows to combine different algorithms and sentence scoring schemes seamlessly. Our results combining sentence scoring with ILP and normalization are in contrast to previous work on this topic, showing the importance of a broader search for optimal parameters. We also show that the new title-driven reduction idea leads to improvement in performance for both unsupervised and supervised approaches considered.
Online News Media Website Ranking Using User Generated Content
Oct 28, 2019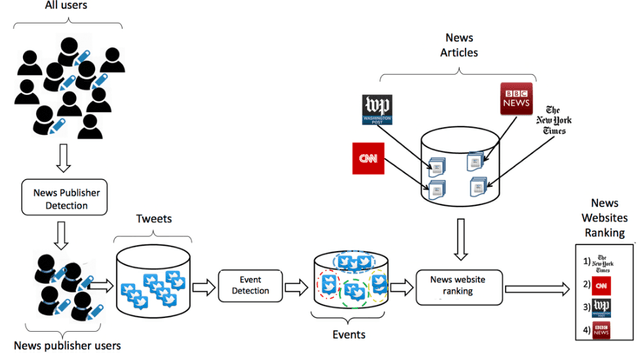
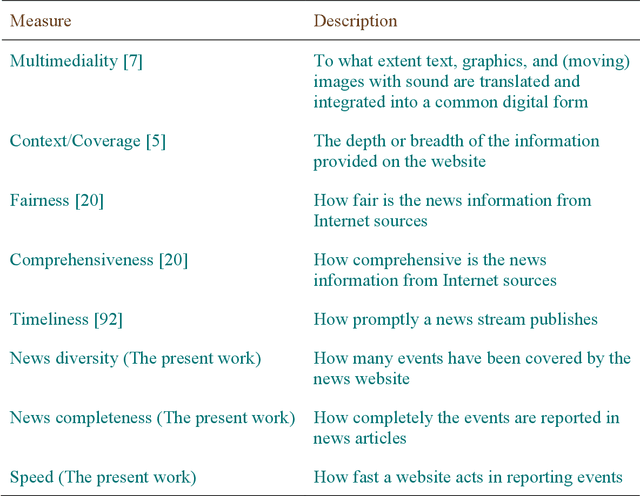
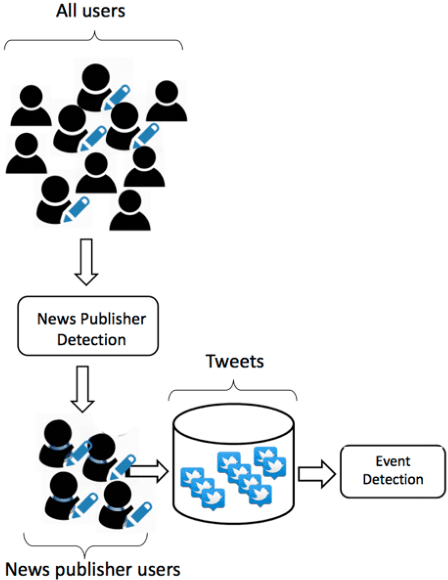
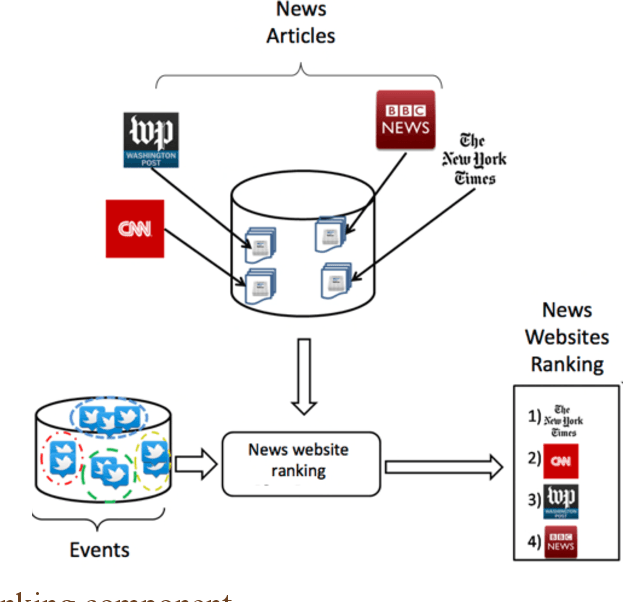
News media websites are important online resources that have drawn great attention of text mining researchers. The main aim of this study is to propose a framework for ranking online news websites from different viewpoints. The ranking of news websites is useful information, which can benefit many news-related tasks such as news retrieval and news recommendation. In the proposed framework, the ranking of news websites is obtained by calculating three measures introduced in the paper and based on user-generated content. Each proposed measure is concerned with the performance of news websites from a particular viewpoint including the completeness of news reports, the diversity of events being covered by the website and its speed. The use of user-generated content in this framework, as a partly-unbiased, real-time and low cost content on the web distinguishes the proposed news website ranking framework from the literature. The results obtained for three prominent news websites, BBC, CNN, NYTimes, show that BBC has the best performance in terms of news completeness and speed, and NYTimes has the best diversity in comparison with the other two websites.
Automated email Generation for Targeted Attacks using Natural Language
Aug 19, 2019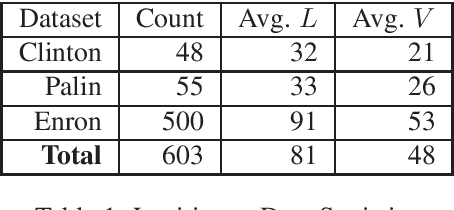
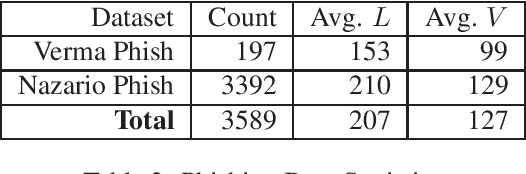

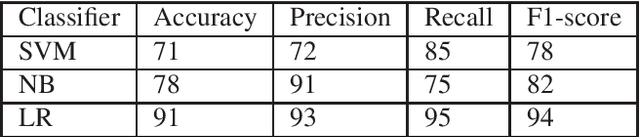
With an increasing number of malicious attacks, the number of people and organizations falling prey to social engineering attacks is proliferating. Despite considerable research in mitigation systems, attackers continually improve their modus operandi by using sophisticated machine learning, natural language processing techniques with an intent to launch successful targeted attacks aimed at deceiving detection mechanisms as well as the victims. We propose a system for advanced email masquerading attacks using Natural Language Generation (NLG) techniques. Using legitimate as well as an influx of varying malicious content, the proposed deep learning system generates \textit{fake} emails with malicious content, customized depending on the attacker's intent. The system leverages Recurrent Neural Networks (RNNs) for automated text generation. We also focus on the performance of the generated emails in defeating statistical detectors, and compare and analyze the emails using a proposed baseline.
Newswire versus Social Media for Disaster Response and Recovery
Jun 25, 2019



In a disaster situation, first responders need to quickly acquire situational awareness and prioritize response based on the need, resources available and impact. Can they do this based on digital media such as Twitter alone, or newswire alone, or some combination of the two? We examine this question in the context of the 2015 Nepal Earthquakes. Because newswire articles are longer, effective summaries can be helpful in saving time yet giving key content. We evaluate the effectiveness of several unsupervised summarization techniques in capturing key content. We propose a method to link tweets written by the public and newswire articles, so that we can compare their key characteristics: timeliness, whether tweets appear earlier than their corresponding news articles, and content. A novel idea is to view relevant tweets as a summary of the matching news article and evaluate these summaries. Whenever possible, we present both quantitative and qualitative evaluations. One of our main findings is that tweets and newswire articles provide complementary perspectives that form a holistic view of the disaster situation.
Identifying Reference Spans: Topic Modeling and Word Embeddings help IR
Aug 09, 2017



The CL-SciSumm 2016 shared task introduced an interesting problem: given a document D and a piece of text that cites D, how do we identify the text spans of D being referenced by the piece of text? The shared task provided the first annotated dataset for studying this problem. We present an analysis of our continued work in improving our system's performance on this task. We demonstrate how topic models and word embeddings can be used to surpass the previously best performing system.
Extractive Summarization: Limits, Compression, Generalized Model and Heuristics
Apr 18, 2017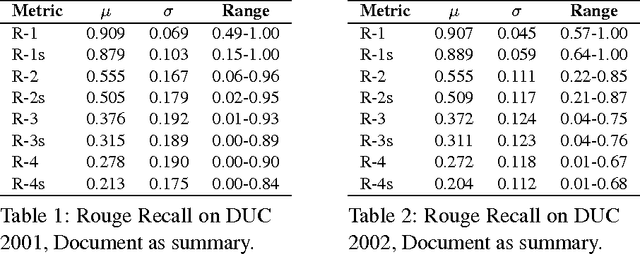
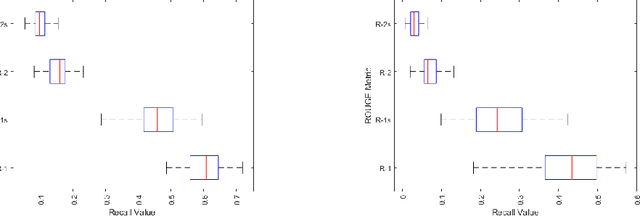
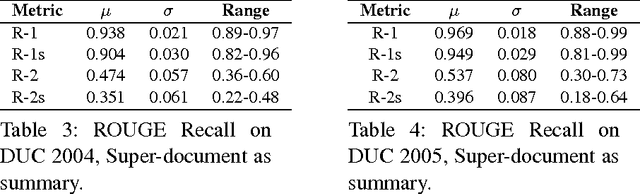
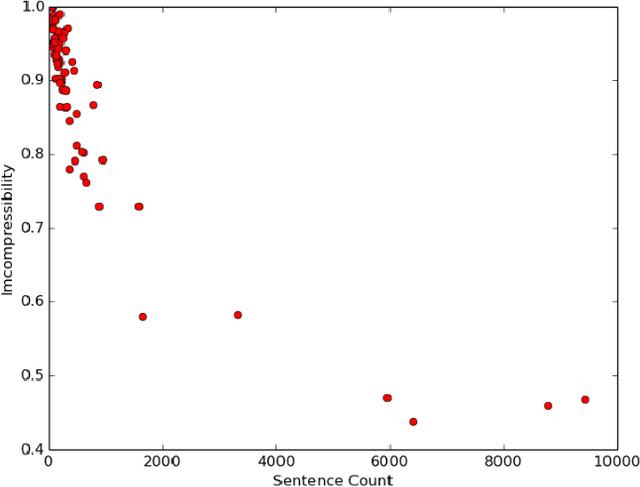
Due to its promise to alleviate information overload, text summarization has attracted the attention of many researchers. However, it has remained a serious challenge. Here, we first prove empirical limits on the recall (and F1-scores) of extractive summarizers on the DUC datasets under ROUGE evaluation for both the single-document and multi-document summarization tasks. Next we define the concept of compressibility of a document and present a new model of summarization, which generalizes existing models in the literature and integrates several dimensions of the summarization, viz., abstractive versus extractive, single versus multi-document, and syntactic versus semantic. Finally, we examine some new and existing single-document summarization algorithms in a single framework and compare with state of the art summarizers on DUC data.