 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtractive Summarization: Limits, Compression, Generalized Model and Heuristics
Paper and Code
Apr 18, 2017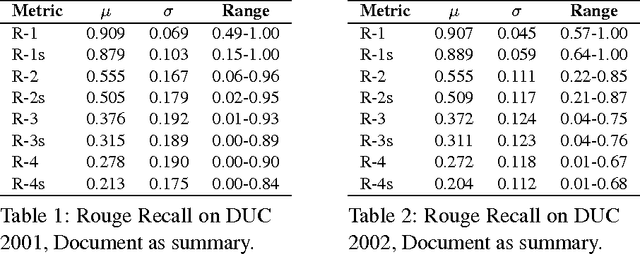
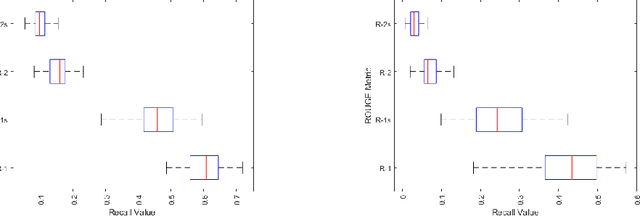
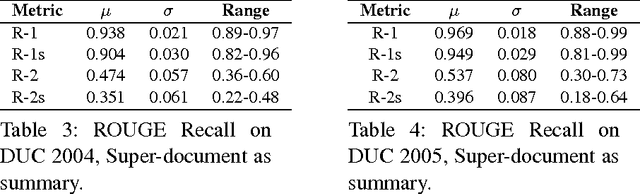
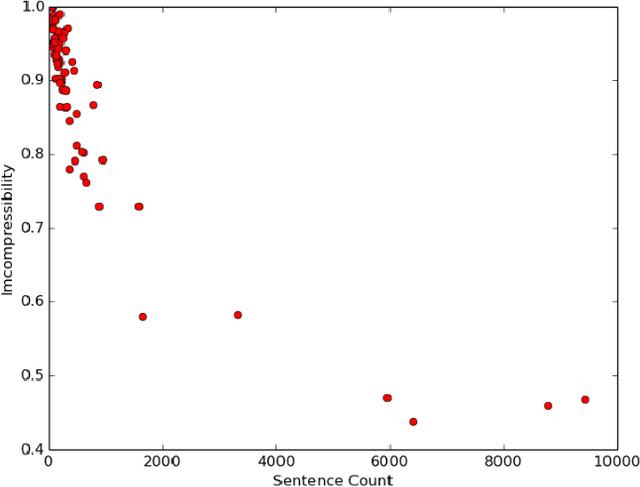
Due to its promise to alleviate information overload, text summarization has attracted the attention of many researchers. However, it has remained a serious challenge. Here, we first prove empirical limits on the recall (and F1-scores) of extractive summarizers on the DUC datasets under ROUGE evaluation for both the single-document and multi-document summarization tasks. Next we define the concept of compressibility of a document and present a new model of summarization, which generalizes existing models in the literature and integrates several dimensions of the summarization, viz., abstractive versus extractive, single versus multi-document, and syntactic versus semantic. Finally, we examine some new and existing single-document summarization algorithms in a single framework and compare with state of the art summarizers on DUC data.