 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Speed/Accuracy Trade-Off for Person Re-identification via Knowledge Distillation
Dec 07, 2018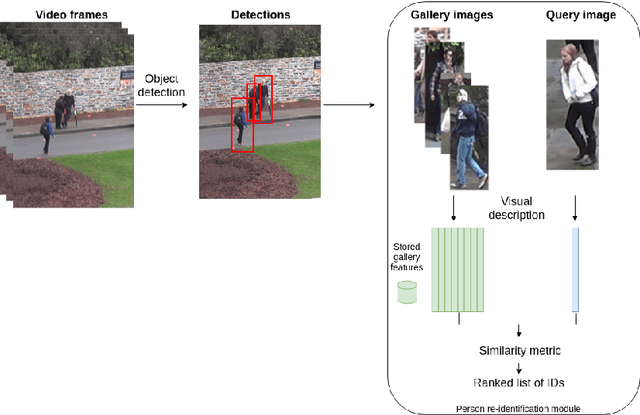

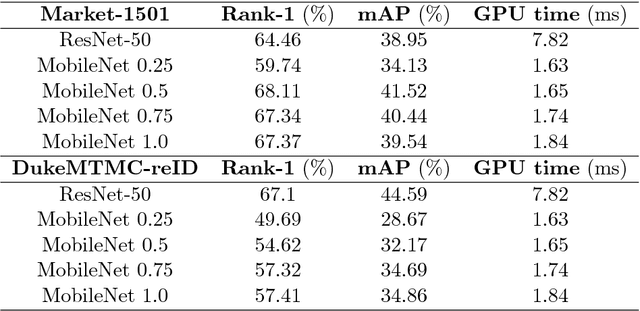
Finding a person across a camera network plays an important role in video surveillance. For a real-world person re-identification application, in order to guarantee an optimal time response, it is crucial to find the balance between accuracy and speed. We analyse this trade-off, comparing a classical method, that comprises hand-crafted feature description and metric learning, in particular, LOMO and XQDA, with state-of-the-art deep learning techniques, using image classification networks, ResNet and MobileNets. Additionally, we propose and analyse network distillation as a learning strategy to reduce the computational cost of the deep learning approach at test time. We evaluate both methods on the Market-1501 and DukeMTMC-reID large-scale datasets.
Object detection at 200 Frames Per Second
May 16, 2018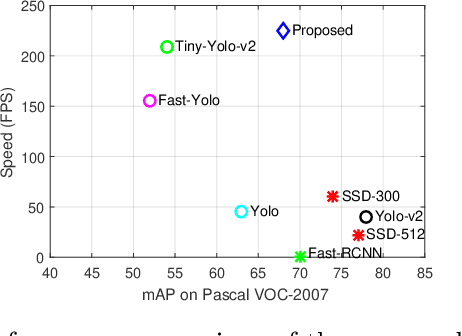
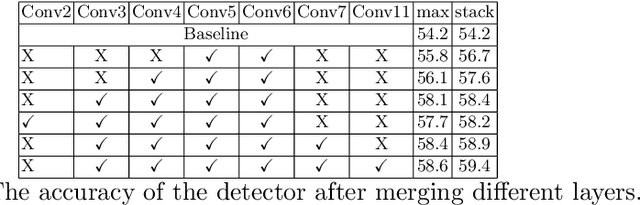
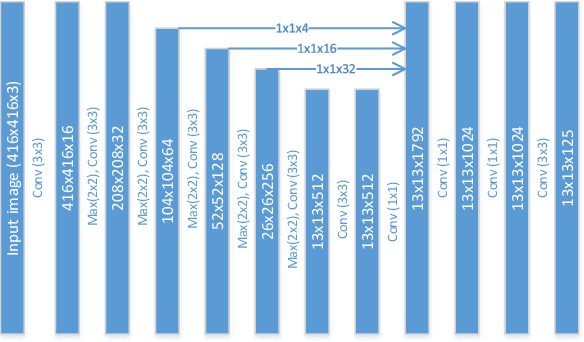
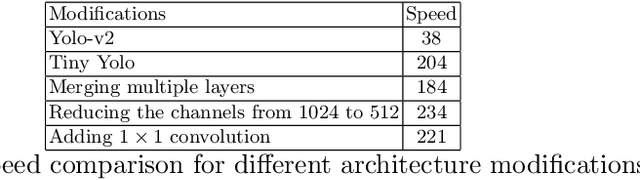
In this paper, we propose an efficient and fast object detector which can process hundreds of frames per second. To achieve this goal we investigate three main aspects of the object detection framework: network architecture, loss function and training data (labeled and unlabeled). In order to obtain compact network architecture, we introduce various improvements, based on recent work, to develop an architecture which is computationally light-weight and achieves a reasonable performance. To further improve the performance, while keeping the complexity same, we utilize distillation loss function. Using distillation loss we transfer the knowledge of a more accurate teacher network to proposed light-weight student network. We propose various innovations to make distillation efficient for the proposed one stage detector pipeline: objectness scaled distillation loss, feature map non-maximal suppression and a single unified distillation loss function for detection. Finally, building upon the distillation loss, we explore how much can we push the performance by utilizing the unlabeled data. We train our model with unlabeled data using the soft labels of the teacher network. Our final network consists of 10x fewer parameters than the VGG based object detection network and it achieves a speed of more than 200 FPS and proposed changes improve the detection accuracy by 14 mAP over the baseline on Pascal dataset.
Single Image Super-Resolution based on Wiener Filter in Similarity Domain
Nov 29, 2017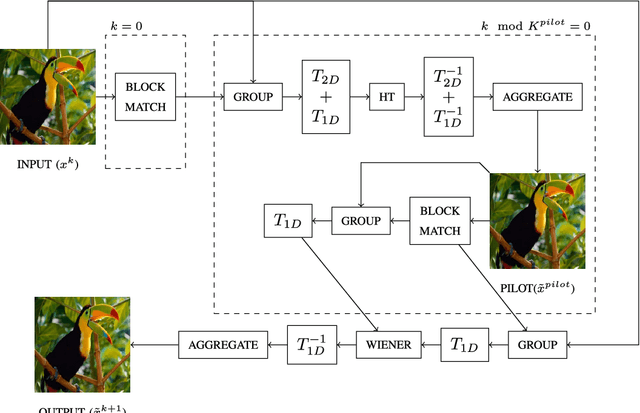

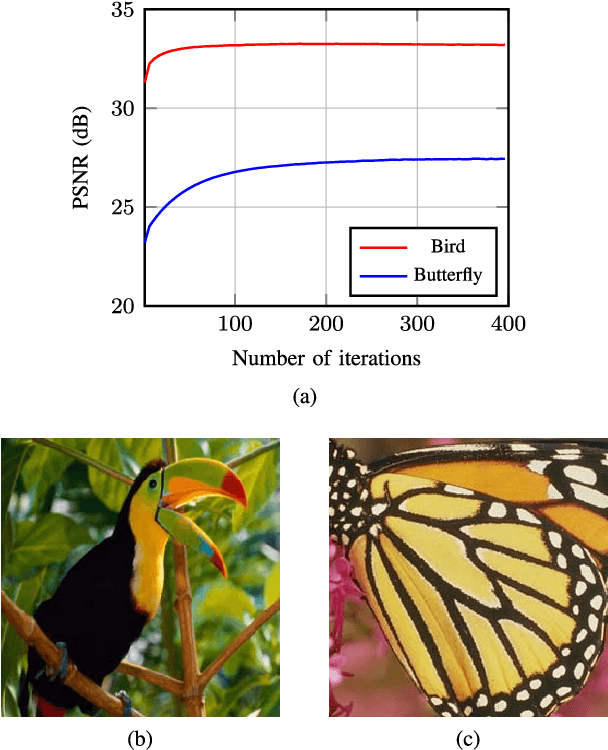

Single image super resolution (SISR) is an ill-posed problem aiming at estimating a plausible high resolution (HR) image from a single low resolution (LR) image. Current state-of-the-art SISR methods are patch-based. They use either external data or internal self-similarity to learn a prior for a HR image. External data based methods utilize large number of patches from the training data, while self-similarity based approaches leverage one or more similar patches from the input image. In this paper we propose a self-similarity based approach that is able to use large groups of similar patches extracted from the input image to solve the SISR problem. We introduce a novel prior leading to collaborative filtering of patch groups in 1D similarity domain and couple it with an iterative back-projection framework. The performance of the proposed algorithm is evaluated on a number of SISR benchmark datasets. Without using any external data, the proposed approach outperforms the current non-CNN based methods on the tested datasets for various scaling factors. On certain datasets, the gain is over 1 dB, when compared to the recent method A+. For high sampling rate (x4) the proposed method performs similarly to very recent state-of-the-art deep convolutional network based approaches.