 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Speed/Accuracy Trade-Off for Person Re-identification via Knowledge Distillation
Paper and Code
Dec 07, 2018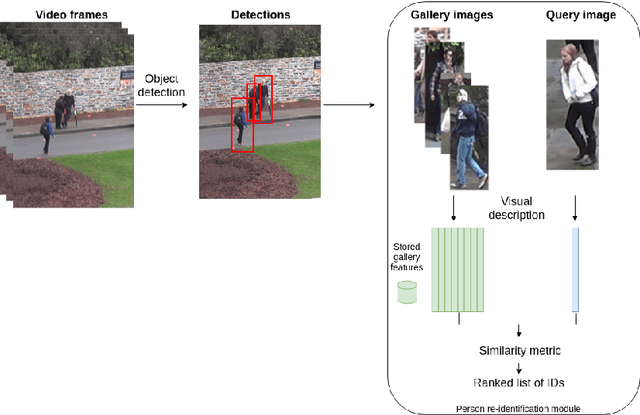

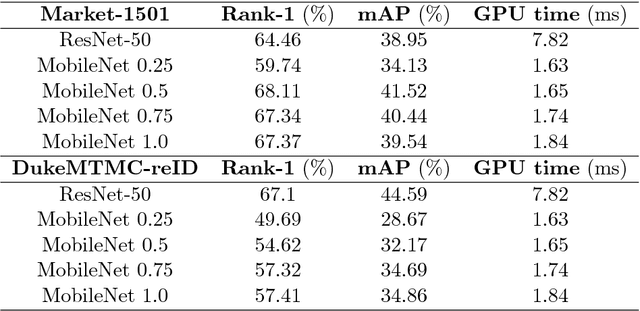
Finding a person across a camera network plays an important role in video surveillance. For a real-world person re-identification application, in order to guarantee an optimal time response, it is crucial to find the balance between accuracy and speed. We analyse this trade-off, comparing a classical method, that comprises hand-crafted feature description and metric learning, in particular, LOMO and XQDA, with state-of-the-art deep learning techniques, using image classification networks, ResNet and MobileNets. Additionally, we propose and analyse network distillation as a learning strategy to reduce the computational cost of the deep learning approach at test time. We evaluate both methods on the Market-1501 and DukeMTMC-reID large-scale datasets.