 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Quality Event Recognition and Classification Using an Online Sequential Extreme Learning Machine Network based on Wavelets
Dec 27, 2022Reduced system dependability and higher maintenance costs may be the consequence of poor electric power quality, which can disturb normal equipment performance, speed up aging, and even cause outright failures. This study implements and tests a prototype of an Online Sequential Extreme Learning Machine (OS-ELM) classifier based on wavelets for detecting power quality problems under transient conditions. In order to create the classifier, the OSELM-network model and the discrete wavelet transform (DWT) method are combined. First, discrete wavelet transform (DWT) multi-resolution analysis (MRA) was used to extract characteristics of the distorted signal at various resolutions. The OSELM then sorts the retrieved data by transient duration and energy features to determine the kind of disturbance. The suggested approach requires less memory space and processing time since it can minimize a large quantity of the distorted signal's characteristics without changing the signal's original quality. Several types of transient events were used to demonstrate the classifier's ability to detect and categorize various types of power disturbances, including sags, swells, momentary interruptions, oscillatory transients, harmonics, notches, spikes, flickers, sag swell, sag mi, sag harm, swell trans, sag spike, and swell spike.
Meta-Embeddings for Natural Language Inference and Semantic Similarity tasks
Dec 01, 2020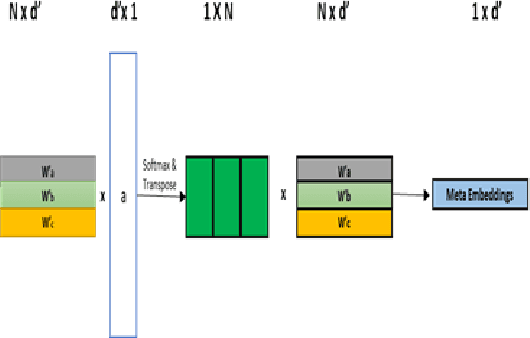
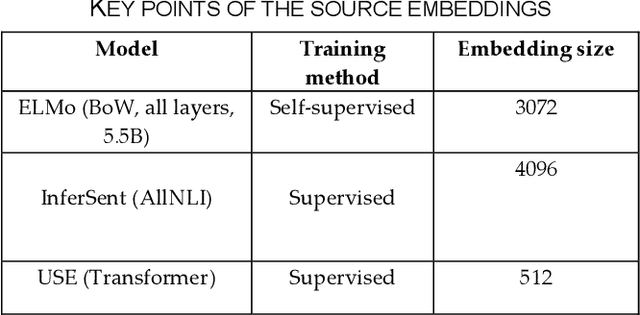
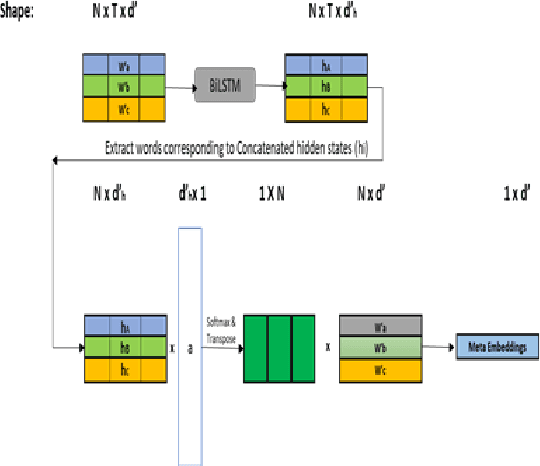
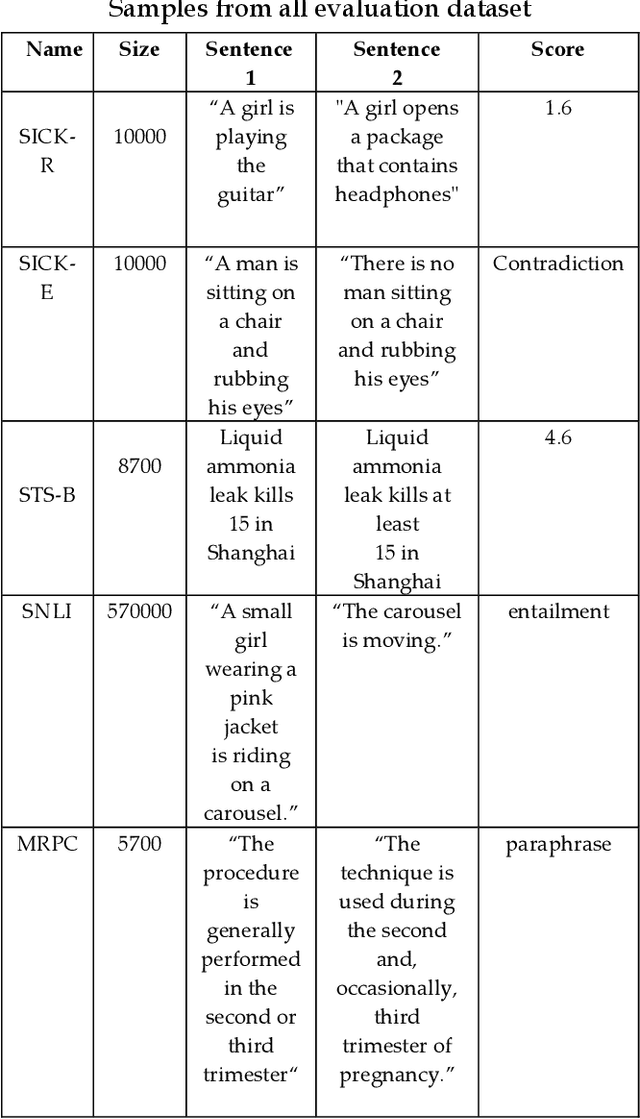
Word Representations form the core component for almost all advanced Natural Language Processing (NLP) applications such as text mining, question-answering, and text summarization, etc. Over the last two decades, immense research is conducted to come up with one single model to solve all major NLP tasks. The major problem currently is that there are a plethora of choices for different NLP tasks. Thus for NLP practitioners, the task of choosing the right model to be used itself becomes a challenge. Thus combining multiple pre-trained word embeddings and forming meta embeddings has become a viable approach to improve tackle NLP tasks. Meta embedding learning is a process of producing a single word embedding from a given set of pre-trained input word embeddings. In this paper, we propose to use Meta Embedding derived from few State-of-the-Art (SOTA) models to efficiently tackle mainstream NLP tasks like classification, semantic relatedness, and text similarity. We have compared both ensemble and dynamic variants to identify an efficient approach. The results obtained show that even the best State-of-the-Art models can be bettered. Thus showing us that meta-embeddings can be used for several NLP tasks by harnessing the power of several individual representations.
The Integrity of Machine Learning Algorithms against Software Defect Prediction
Sep 05, 2020The increased computerization in recent years has resulted in the production of a variety of different software, however measures need to be taken to ensure that the produced software isn't defective. Many researchers have worked in this area and have developed different Machine Learning-based approaches that predict whether the software is defective or not. This issue can't be resolved simply by using different conventional classifiers because the dataset is highly imbalanced i.e the number of defective samples detected is extremely less as compared to the number of non-defective samples. Therefore, to address this issue, certain sophisticated methods are required. The different methods developed by the researchers can be broadly classified into Resampling based methods, Cost-sensitive learning-based methods, and Ensemble Learning. Among these methods. This report analyses the performance of the Online Sequential Extreme Learning Machine (OS-ELM) proposed by Liang et.al. against several classifiers such as Logistic Regression, Support Vector Machine, Random Forest, and Na\"ive Bayes after oversampling the data. OS-ELM trains faster than conventional deep neural networks and it always converges to the globally optimal solution. A comparison is performed on the original dataset as well as the over-sampled data set. The oversampling technique used is Cluster-based Over-Sampling with Noise Filtering. This technique is better than several state-of-the-art techniques for oversampling. The analysis is carried out on 3 projects KC1, PC4 and PC3 carried out by the NASA group. The metrics used for measurement are recall and balanced accuracy. The results are higher for OS-ELM as compared to other classifiers in both scenarios.
Characterizing the Weight Space for Different Learning Models
Jun 04, 2020
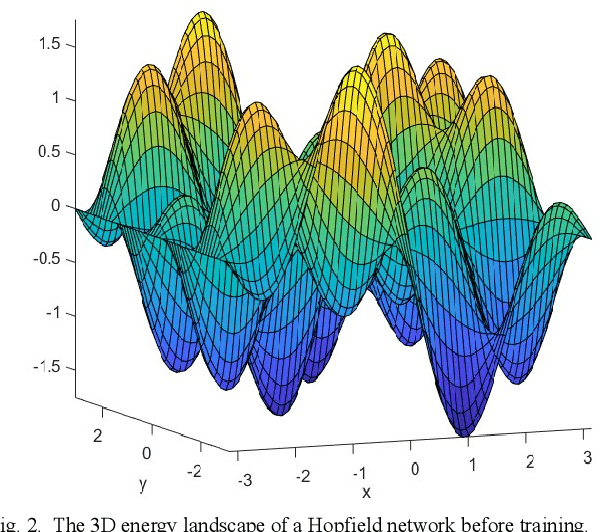
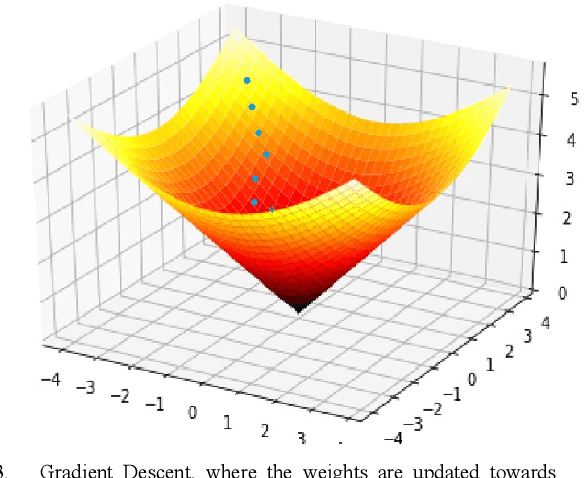
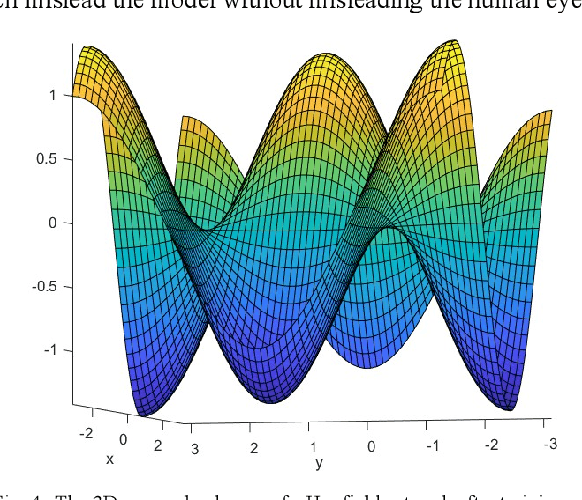
Deep Learning has become one of the primary research areas in developing intelligent machines. Most of the well-known applications (such as Speech Recognition, Image Processing and NLP) of AI are driven by Deep Learning. Deep Learning algorithms mimic human brain using artificial neural networks and progressively learn to accurately solve a given problem. But there are significant challenges in Deep Learning systems. There have been many attempts to make deep learning models imitate the biological neural network. However, many deep learning models have performed poorly in the presence of adversarial examples. Poor performance in adversarial examples leads to adversarial attacks and in turn leads to safety and security in most of the applications. In this paper we make an attempt to characterize the solution space of a deep neural network in terms of three different subsets viz. weights belonging to exact trained patterns, weights belonging to generalized pattern set and weights belonging to adversarial pattern sets. We attempt to characterize the solution space with two seemingly different learning paradigms viz. the Deep Neural Networks and the Dense Associative Memory Model, which try to achieve learning via quite different mechanisms. We also show that adversarial attacks are generally less successful against Associative Memory Models than Deep Neural Networks.
Exploring the role of Input and Output Layers of a Deep Neural Network in Adversarial Defense
Jun 02, 2020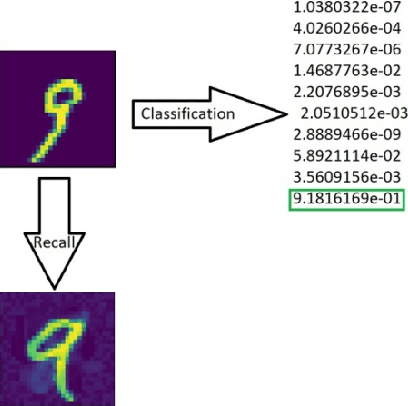
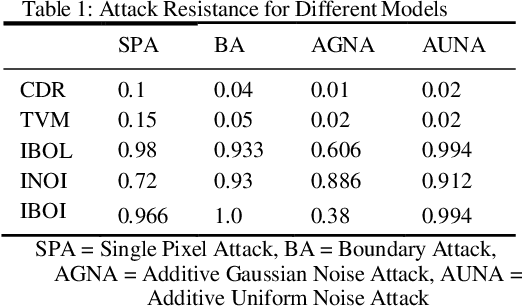
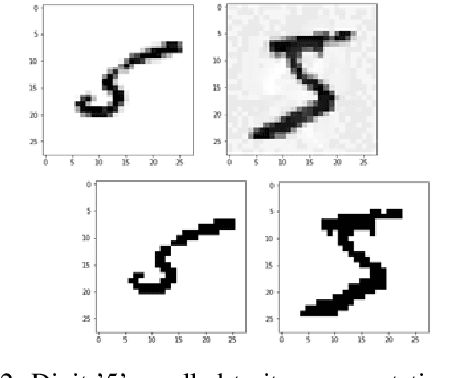

Deep neural networks are learning models having achieved state of the art performance in many fields like prediction, computer vision, language processing and so on. However, it has been shown that certain inputs exist which would not trick a human normally, but may mislead the model completely. These inputs are known as adversarial inputs. These inputs pose a high security threat when such models are used in real world applications. In this work, we have analyzed the resistance of three different classes of fully connected dense networks against the rarely tested non-gradient based adversarial attacks. These classes are created by manipulating the input and output layers. We have proven empirically that owing to certain characteristics of the network, they provide a high robustness against these attacks, and can be used in fine tuning other models to increase defense against adversarial attacks.