 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Embeddings for Natural Language Inference and Semantic Similarity tasks
Paper and Code
Dec 01, 2020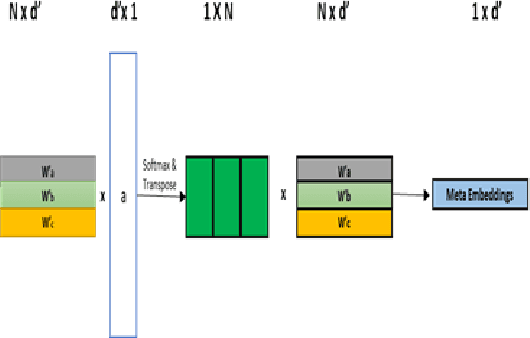
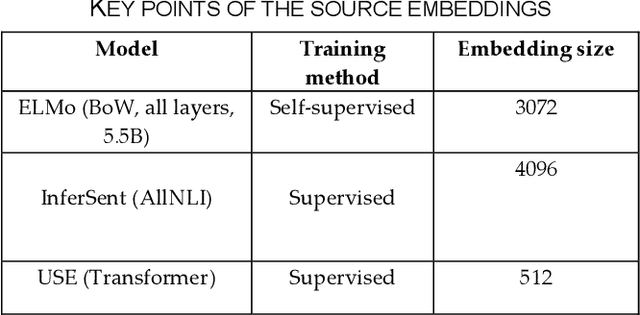
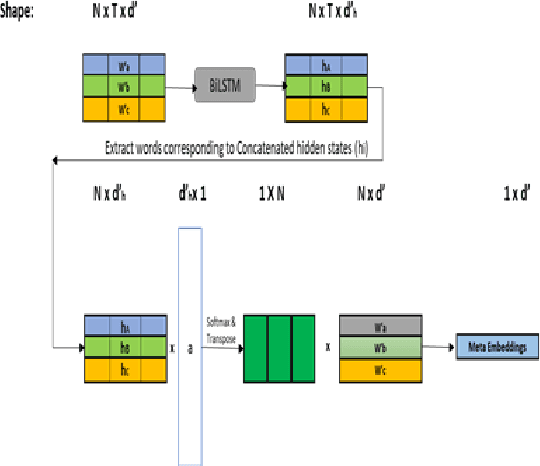
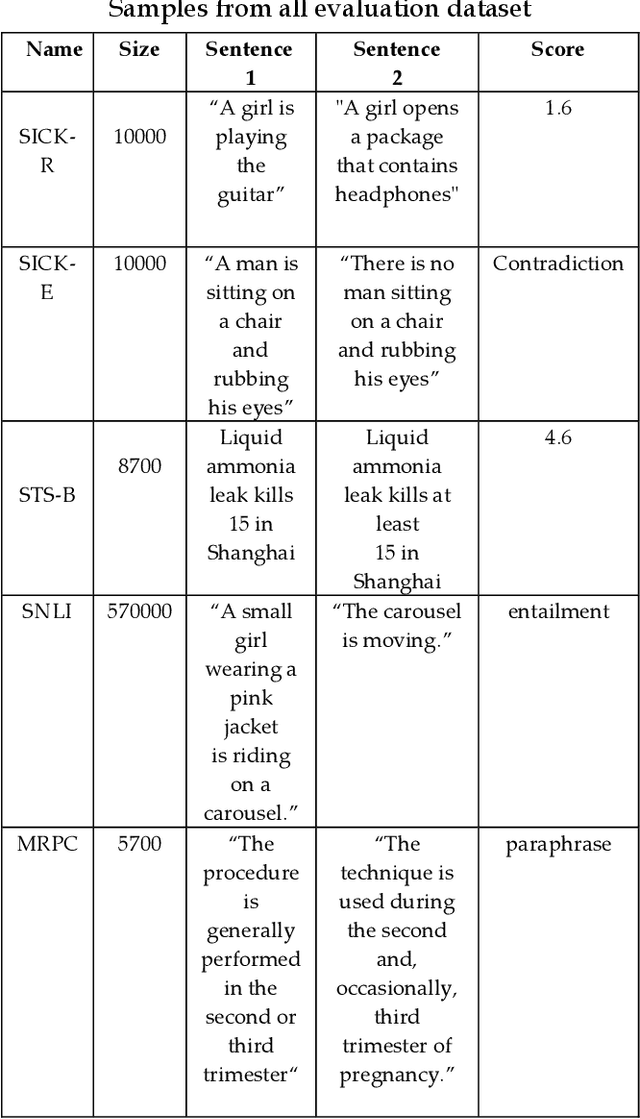
Word Representations form the core component for almost all advanced Natural Language Processing (NLP) applications such as text mining, question-answering, and text summarization, etc. Over the last two decades, immense research is conducted to come up with one single model to solve all major NLP tasks. The major problem currently is that there are a plethora of choices for different NLP tasks. Thus for NLP practitioners, the task of choosing the right model to be used itself becomes a challenge. Thus combining multiple pre-trained word embeddings and forming meta embeddings has become a viable approach to improve tackle NLP tasks. Meta embedding learning is a process of producing a single word embedding from a given set of pre-trained input word embeddings. In this paper, we propose to use Meta Embedding derived from few State-of-the-Art (SOTA) models to efficiently tackle mainstream NLP tasks like classification, semantic relatedness, and text similarity. We have compared both ensemble and dynamic variants to identify an efficient approach. The results obtained show that even the best State-of-the-Art models can be bettered. Thus showing us that meta-embeddings can be used for several NLP tasks by harnessing the power of several individual representations.