 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable Vision-Tactile Robotic Grasping Strategy for Deformable Objects via Transformer
Dec 20, 2021

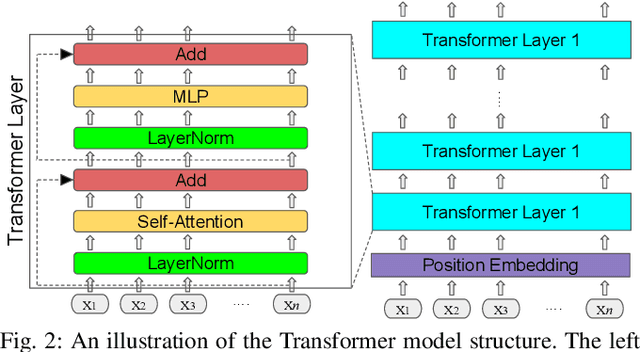

Reliable robotic grasping, especially with deformable objects such as fruits, remains a challenging task due to underactuated contact interactions with a gripper, unknown object dynamics and geometries. In this study, we propose a Transformer-based robotic grasping framework for rigid grippers that leverage tactile and visual information for safe object grasping. Specifically, the Transformer models learn physical feature embeddings with sensor feedback through performing two pre-defined explorative actions (pinching and sliding) and predict a grasping outcome through a multilayer perceptron (MLP) with a given grasping strength. Using these predictions, the gripper predicts a safe grasping strength via inference. Compared with convolutional recurrent networks (CNN), the Transformer models can capture the long-term dependencies across the image sequences and process spatial-temporal features simultaneously. We first benchmark the Transformer models on a public dataset for slip detection. Following that, we show that the Transformer models outperform a CNN+LSTM model in terms of grasping accuracy and computational efficiency. We also collect our fruit grasping dataset and conduct online grasping experiments using the proposed framework for both seen and unseen fruits. Our codes and dataset are public on GitHub.