 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Health Data Poverty: Generative Approaches versus Resampling for Time-series Clinical Data
Oct 26, 2022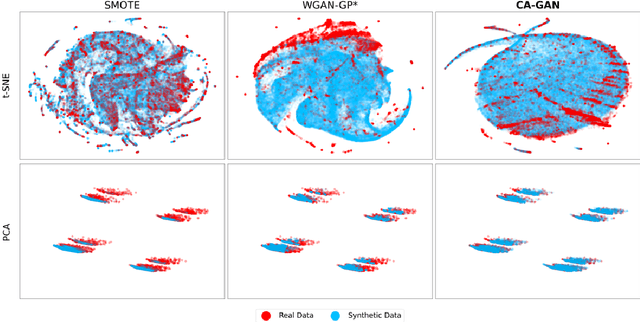
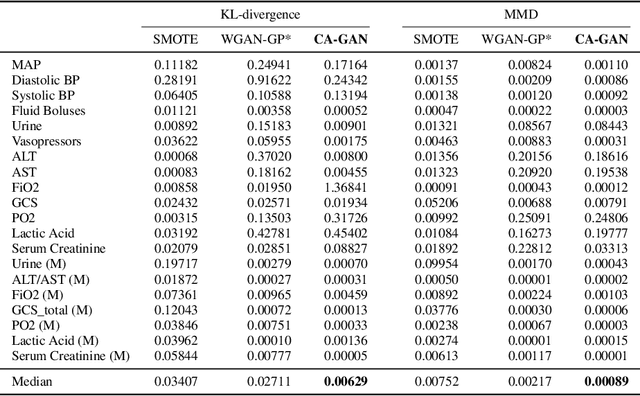
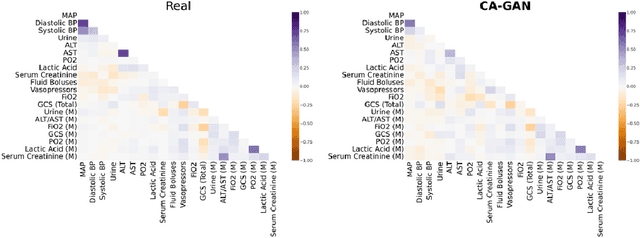
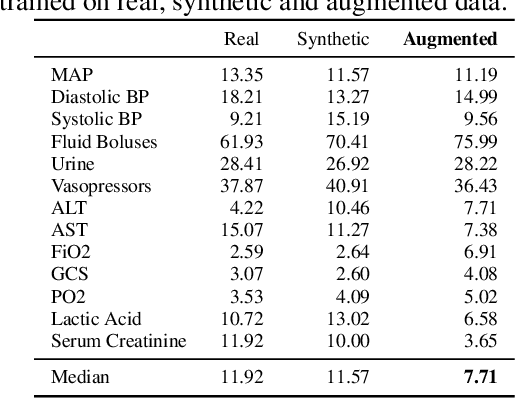
Several approaches have been developed to mitigate algorithmic bias stemming from health data poverty, where minority groups are underrepresented in training datasets. Augmenting the minority class using resampling (such as SMOTE) is a widely used approach due to the simplicity of the algorithms. However, these algorithms decrease data variability and may introduce correlations between samples, giving rise to the use of generative approaches based on GAN. Generation of high-dimensional, time-series, authentic data that provides a wide distribution coverage of the real data, remains a challenging task for both resampling and GAN-based approaches. In this work we propose CA-GAN architecture that addresses some of the shortcomings of the current approaches, where we provide a detailed comparison with both SMOTE and WGAN-GP*, using a high-dimensional, time-series, real dataset of 3343 hypotensive Caucasian and Black patients. We show that our approach is better at both generating authentic data of the minority class and remaining within the original distribution of the real data.