 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional independence testing: a predictive perspective
Jul 31, 2019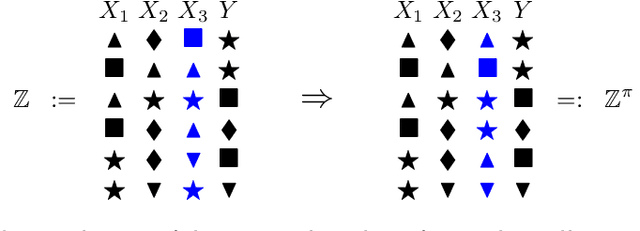

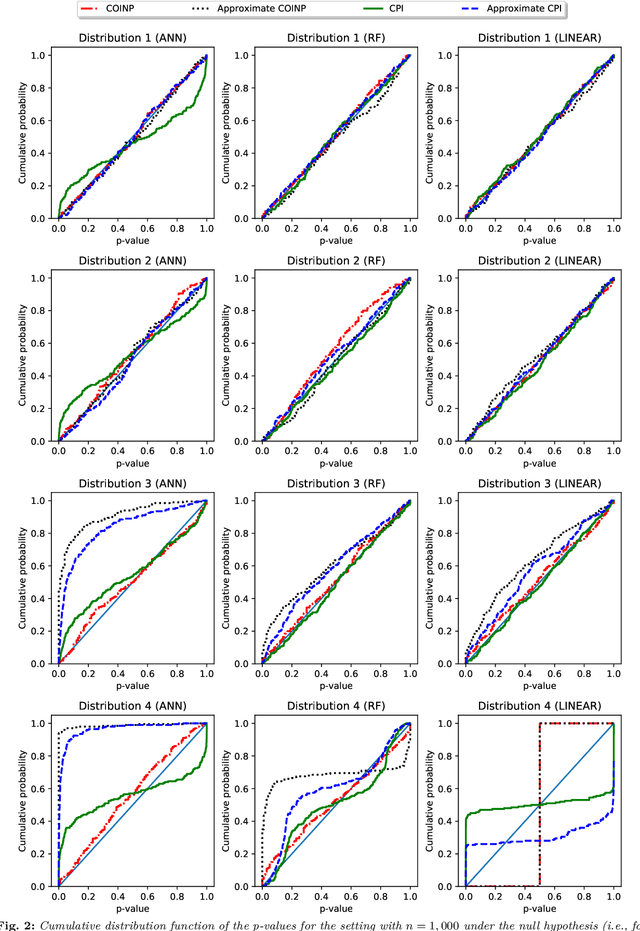
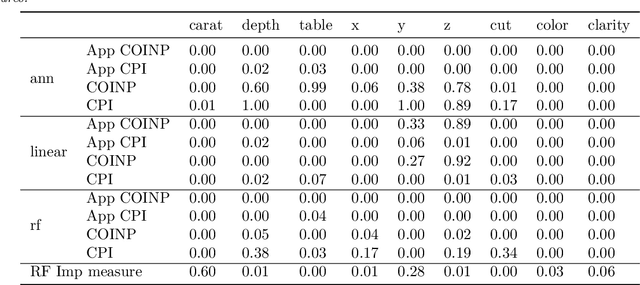
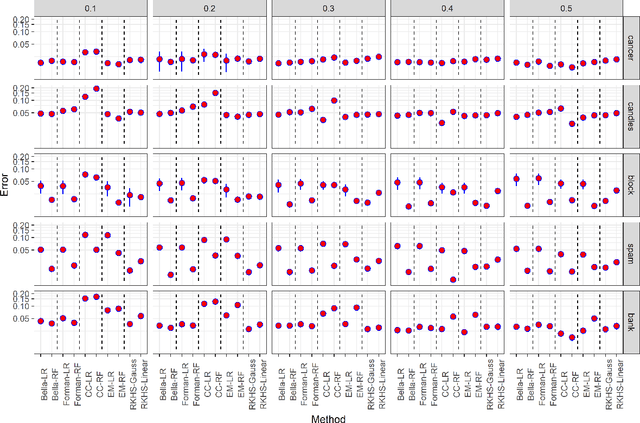
Conditional independence testing is a key problem required by many machine learning and statistics tools. In particular, it is one way of evaluating the usefulness of some features on a supervised prediction problem. We propose a novel conditional independence test in a predictive setting, and show that it achieves better power than competing approaches in several settings. Our approach consists in deriving a p-value using a permutation test where the predictive power using the unpermuted dataset is compared with the predictive power of using dataset where the feature(s) of interest are permuted. We conclude that the method achives sensible results on simulated and real datasets.
Quantification under prior probability shift: the ratio estimator and its extensions
Jul 11, 2018
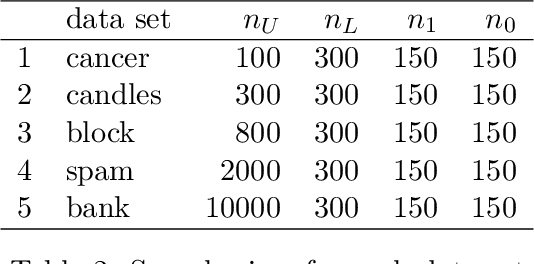
The quantification problem consists of determining the prevalence of a given label in a target population. However, one often has access to the labels in a sample from the training population but not in the target population. A common assumption in this situation is that of prior probability shift, that is, once the labels are known, the distribution of the features is the same in the training and target populations. In this paper, we derive a new lower bound for the risk of the quantification problem under the prior shift assumption. Complementing this lower bound, we present a new approximately minimax class of estimators, ratio estimators, which generalize several previous proposals in the literature. Using a weaker version of the prior shift assumption, which can be tested, we show that ratio estimators can be used to build confidence intervals for the quantification problem. We also extend the ratio estimator so that it can: (i) incorporate labels from the target population, when they are available and (ii) estimate how the prevalence of positive labels varies according to a function of certain covariates.
Learning with many experts: model selection and sparsity
May 13, 2014
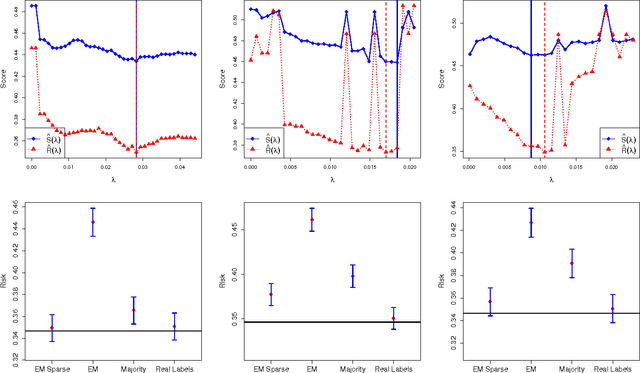
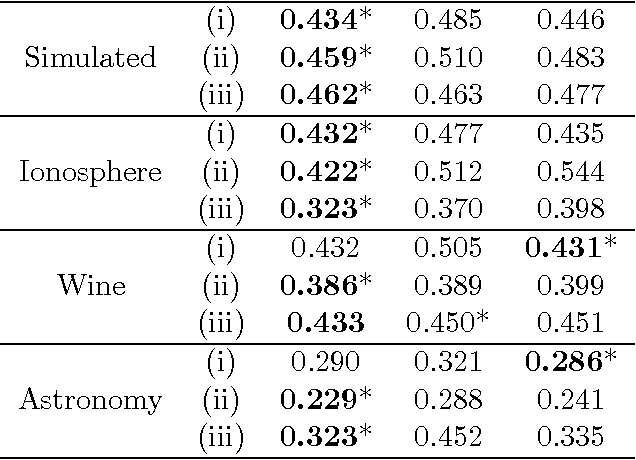
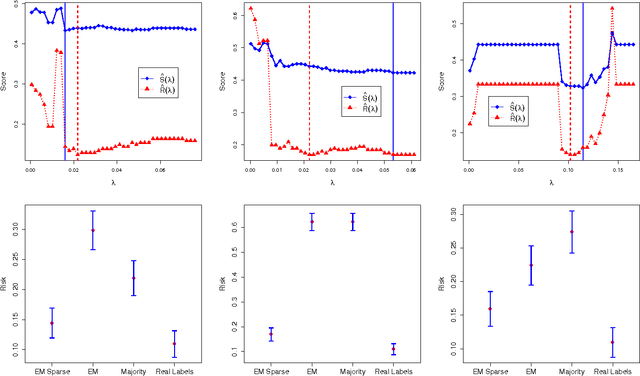
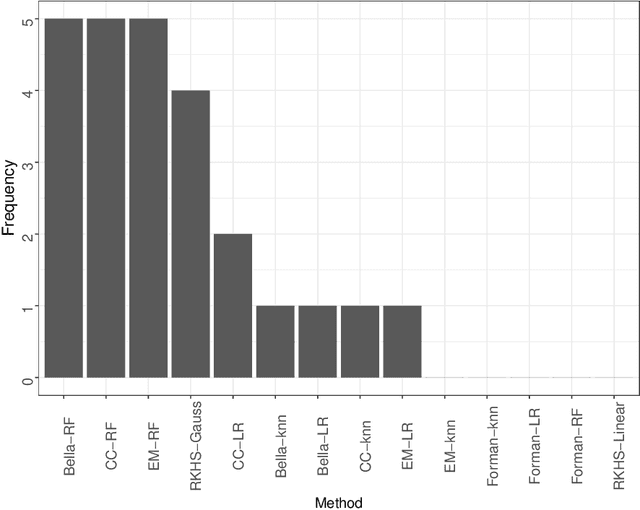
Experts classifying data are often imprecise. Recently, several models have been proposed to train classifiers using the noisy labels generated by these experts. How to choose between these models? In such situations, the true labels are unavailable. Thus, one cannot perform model selection using the standard versions of methods such as empirical risk minimization and cross validation. In order to allow model selection, we present a surrogate loss and provide theoretical guarantees that assure its consistency. Next, we discuss how this loss can be used to tune a penalization which introduces sparsity in the parameters of a traditional class of models. Sparsity provides more parsimonious models and can avoid overfitting. Nevertheless, it has seldom been discussed in the context of noisy labels due to the difficulty in model selection and, therefore, in choosing tuning parameters. We apply these techniques to several sets of simulated and real data.
* This is the pre-peer reviewed version