 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-reversibly updating a uniform value for Metropolis accept/reject decisions
Jan 31, 2020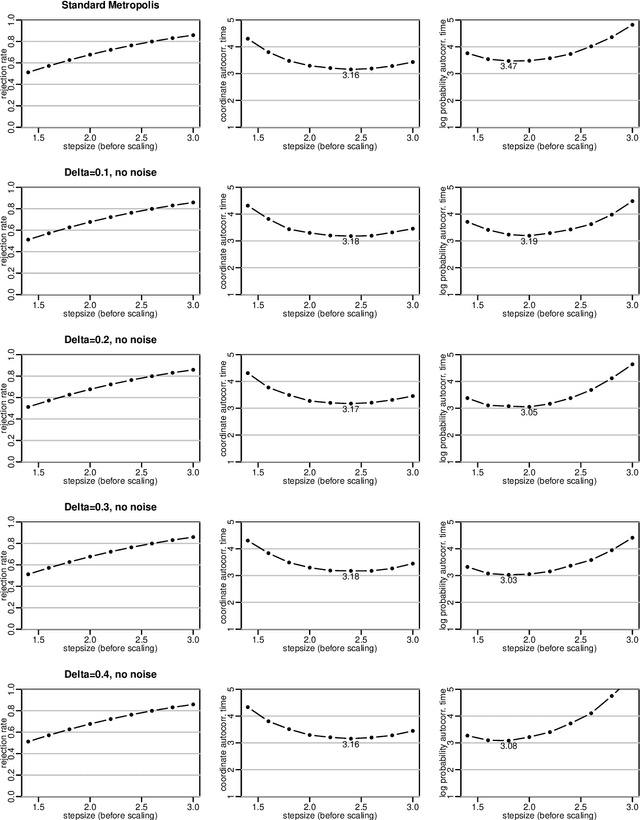

I show how it can be beneficial to express Metropolis accept/reject decisions in terms of comparison with a uniform [0,1] value, u, and to then update u non-reversibly, as part of the Markov chain state, rather than sampling it independently each iteration. This provides a small improvement for random walk Metropolis and Langevin updates in high dimensions. It produces a larger improvement when using Langevin updates with persistent momentum, giving performance comparable to that of Hamiltonian Monte Carlo (HMC) with long trajectories. This is of significance when some variables are updated by other methods, since if HMC is used, these updates can be done only between trajectories, whereas they can be done more often with Langevin updates. I demonstrate that for a problem with some continuous variables, updated by HMC or Langevin updates, and also discrete variables, updated by Gibbs sampling between updates of the continuous variables, Langevin with persistent momentum and non-reversible updates to u samples nearly a factor of two more efficiently than HMC. Benefits are also seen for a Bayesian neural network model in which hyperparameters are updated by Gibbs sampling.
Inference for Belief Networks Using Coupling From the Past
Jan 16, 2013



Inference for belief networks using Gibbs sampling produces a distribution for unobserved variables that differs from the correct distribution by a (usually) unknown error, since convergence to the right distribution occurs only asymptotically. The method of "coupling from the past" samples from exactly the correct distribution by (conceptually) running dependent Gibbs sampling simulations from every possible starting state from a time far enough in the past that all runs reach the same state at time t=0. Explicitly considering every possible state is intractable for large networks, however. We propose a method for layered noisy-or networks that uses a compact, but often imprecise, summary of a set of states. This method samples from exactly the correct distribution, and requires only about twice the time per step as ordinary Gibbs sampling, but it may require more simulation steps than would be needed if chains were tracked exactly.
Gaussian Process Regression with Heteroscedastic or Non-Gaussian Residuals
Dec 26, 2012


Gaussian Process (GP) regression models typically assume that residuals are Gaussian and have the same variance for all observations. However, applications with input-dependent noise (heteroscedastic residuals) frequently arise in practice, as do applications in which the residuals do not have a Gaussian distribution. In this paper, we propose a GP Regression model with a latent variable that serves as an additional unobserved covariate for the regression. This model (which we call GPLC) allows for heteroscedasticity since it allows the function to have a changing partial derivative with respect to this unobserved covariate. With a suitable covariance function, our GPLC model can handle (a) Gaussian residuals with input-dependent variance, or (b) non-Gaussian residuals with input-dependent variance, or (c) Gaussian residuals with constant variance. We compare our model, using synthetic datasets, with a model proposed by Goldberg, Williams and Bishop (1998), which we refer to as GPLV, which only deals with case (a), as well as a standard GP model which can handle only case (c). Markov Chain Monte Carlo methods are developed for both modelsl. Experiments show that when the data is heteroscedastic, both GPLC and GPLV give better results (smaller mean squared error and negative log-probability density) than standard GP regression. In addition, when the residual are Gaussian, our GPLC model is generally nearly as good as GPLV, while when the residuals are non-Gaussian, our GPLC model is better than GPLV.
A Method for Compressing Parameters in Bayesian Models with Application to Logistic Sequence Prediction Models
Nov 30, 2007



Bayesian classification and regression with high order interactions is largely infeasible because Markov chain Monte Carlo (MCMC) would need to be applied with a great many parameters, whose number increases rapidly with the order. In this paper we show how to make it feasible by effectively reducing the number of parameters, exploiting the fact that many interactions have the same values for all training cases. Our method uses a single ``compressed'' parameter to represent the sum of all parameters associated with a set of patterns that have the same value for all training cases. Using symmetric stable distributions as the priors of the original parameters, we can easily find the priors of these compressed parameters. We therefore need to deal only with a much smaller number of compressed parameters when training the model with MCMC. The number of compressed parameters may have converged before considering the highest possible order. After training the model, we can split these compressed parameters into the original ones as needed to make predictions for test cases. We show in detail how to compress parameters for logistic sequence prediction models. Experiments on both simulated and real data demonstrate that a huge number of parameters can indeed be reduced by our compression method.
* 29 pages