 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-reversibly updating a uniform value for Metropolis accept/reject decisions
Paper and Code
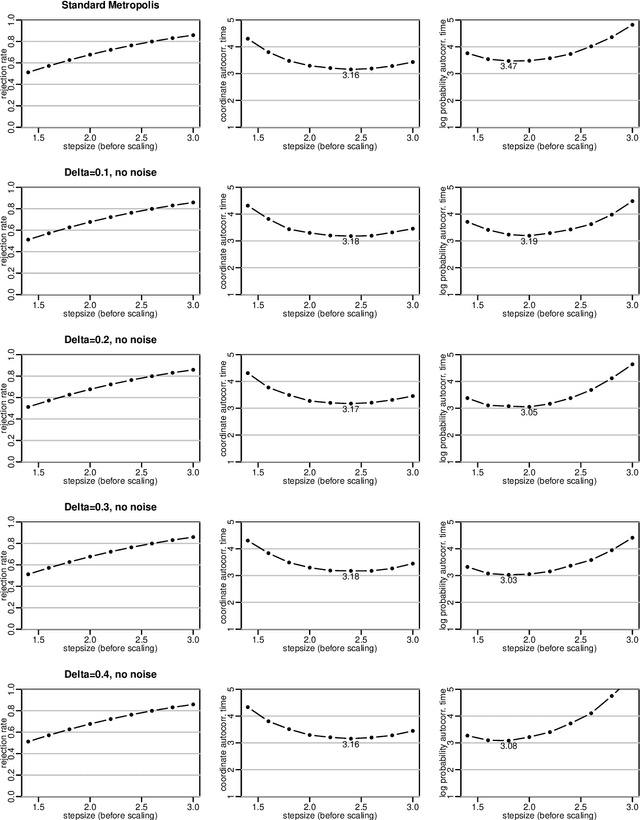

I show how it can be beneficial to express Metropolis accept/reject decisions in terms of comparison with a uniform [0,1] value, u, and to then update u non-reversibly, as part of the Markov chain state, rather than sampling it independently each iteration. This provides a small improvement for random walk Metropolis and Langevin updates in high dimensions. It produces a larger improvement when using Langevin updates with persistent momentum, giving performance comparable to that of Hamiltonian Monte Carlo (HMC) with long trajectories. This is of significance when some variables are updated by other methods, since if HMC is used, these updates can be done only between trajectories, whereas they can be done more often with Langevin updates. I demonstrate that for a problem with some continuous variables, updated by HMC or Langevin updates, and also discrete variables, updated by Gibbs sampling between updates of the continuous variables, Langevin with persistent momentum and non-reversible updates to u samples nearly a factor of two more efficiently than HMC. Benefits are also seen for a Bayesian neural network model in which hyperparameters are updated by Gibbs sampling.