 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Emotion Recognition Based on Multi-feature and Multi-lingual Fusion
Jan 16, 2020



A speech emotion recognition algorithm based on multi-feature and Multi-lingual fusion is proposed in order to resolve low recognition accuracy caused by lack of large speech dataset and low robustness of acoustic features in the recognition of speech emotion. First, handcrafted and deep automatic features are extracted from existing data in Chinese and English speech emotions. Then, the various features are fused respectively. Finally, the fused features of different languages are fused again and trained in a classification model. Distinguishing the fused features with the unfused ones, the results manifest that the fused features significantly enhance the accuracy of speech emotion recognition algorithm. The proposed solution is evaluated on the two Chinese corpus and two English corpus, and is shown to provide more accurate predictions compared to original solution. As a result of this study, the multi-feature and Multi-lingual fusion algorithm can significantly improve the speech emotion recognition accuracy when the dataset is small.
Gaussian Process Regression with Heteroscedastic or Non-Gaussian Residuals
Dec 26, 2012

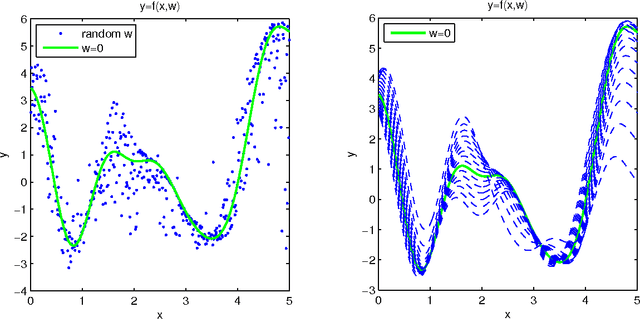

Gaussian Process (GP) regression models typically assume that residuals are Gaussian and have the same variance for all observations. However, applications with input-dependent noise (heteroscedastic residuals) frequently arise in practice, as do applications in which the residuals do not have a Gaussian distribution. In this paper, we propose a GP Regression model with a latent variable that serves as an additional unobserved covariate for the regression. This model (which we call GPLC) allows for heteroscedasticity since it allows the function to have a changing partial derivative with respect to this unobserved covariate. With a suitable covariance function, our GPLC model can handle (a) Gaussian residuals with input-dependent variance, or (b) non-Gaussian residuals with input-dependent variance, or (c) Gaussian residuals with constant variance. We compare our model, using synthetic datasets, with a model proposed by Goldberg, Williams and Bishop (1998), which we refer to as GPLV, which only deals with case (a), as well as a standard GP model which can handle only case (c). Markov Chain Monte Carlo methods are developed for both modelsl. Experiments show that when the data is heteroscedastic, both GPLC and GPLV give better results (smaller mean squared error and negative log-probability density) than standard GP regression. In addition, when the residual are Gaussian, our GPLC model is generally nearly as good as GPLV, while when the residuals are non-Gaussian, our GPLC model is better than GPLV.