 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Models for Suicide Prediction from Social Media Posts
Apr 29, 2021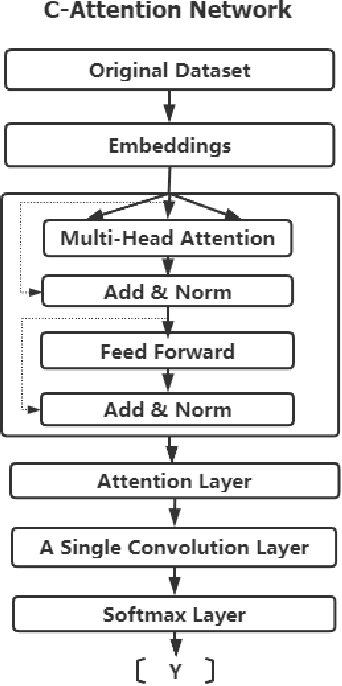
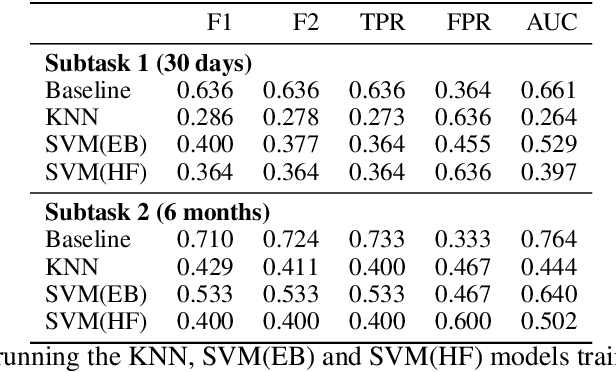

We propose a deep learning architecture and test three other machine learning models to automatically detect individuals that will attempt suicide within (1) 30 days and (2) six months, using their social media post data provided in the CLPsych 2021 shared task. Additionally, we create and extract three sets of handcrafted features for suicide risk detection based on the three-stage theory of suicide and prior work on emotions and the use of pronouns among persons exhibiting suicidal ideations. Extensive experimentations show that some of the traditional machine learning methods outperform the baseline with an F1 score of 0.741 and F2 score of 0.833 on subtask 1 (prediction of a suicide attempt 30 days prior). However, the proposed deep learning method outperforms the baseline with F1 score of 0.737 and F2 score of 0.843 on subtask 2 (prediction of suicide 6 months prior).
Causal-TGAN: Generating Tabular Data Using Causal Generative Adversarial Networks
Apr 21, 2021
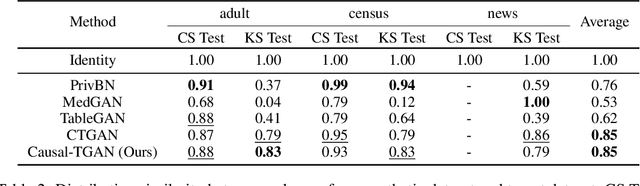
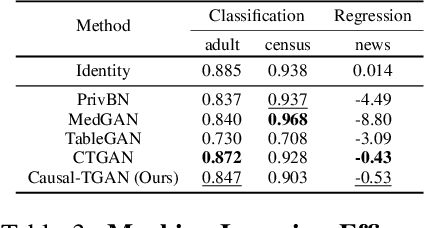
Synthetic data generation becomes prevalent as a solution to privacy leakage and data shortage. Generative models are designed to generate a realistic synthetic dataset, which can precisely express the data distribution for the real dataset. The generative adversarial networks (GAN), which gain great success in the computer vision fields, are doubtlessly used for synthetic data generation. Though there are prior works that have demonstrated great progress, most of them learn the correlations in the data distributions rather than the true processes in which the datasets are naturally generated. Correlation is not reliable for it is a statistical technique that only tells linear dependencies and is easily affected by the dataset's bias. Causality, which encodes all underlying factors of how the real data be naturally generated, is more reliable than correlation. In this work, we propose a causal model named Causal Tabular Generative Neural Network (Causal-TGAN) to generate synthetic tabular data using the tabular data's causal information. Extensive experiments on both simulated datasets and real datasets demonstrate the better performance of our method when given the true causal graph and a comparable performance when using the estimated causal graph.
Personalized Early Stage Alzheimer's Disease Detection: A Case Study of President Reagan's Speeches
May 08, 2020Alzheimer`s disease (AD)-related global healthcare cost is estimated to be $1 trillion by 2050. Currently, there is no cure for this disease; however, clinical studies show that early diagnosis and intervention helps to extend the quality of life and inform technologies for personalized mental healthcare. Clinical research indicates that the onset and progression of Alzheimer`s disease lead to dementia and other mental health issues. As a result, the language capabilities of patient start to decline. In this paper, we show that machine learning-based unsupervised clustering of and anomaly detection with linguistic biomarkers are promising approaches for intuitive visualization and personalized early stage detection of Alzheimer`s disease. We demonstrate this approach on 10 year`s (1980 to 1989) of President Ronald Reagan`s speech data set. Key linguistic biomarkers that indicate early-stage AD are identified. Experimental results show that Reagan had early onset of Alzheimer`s sometime between 1983 and 1987. This finding is corroborated by prior work that analyzed his interviews using a statistical technique. The proposed technique also identifies the exact speeches that reflect linguistic biomarkers for early stage AD.