 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Attention Weights as Explanations from an Information Theoretic Perspective
Oct 31, 2022



Attention mechanisms have recently demonstrated impressive performance on a range of NLP tasks, and attention scores are often used as a proxy for model explainability. However, there is a debate on whether attention weights can, in fact, be used to identify the most important inputs to a model. We approach this question from an information theoretic perspective by measuring the mutual information between the model output and the hidden states. From extensive experiments, we draw the following conclusions: (i) Additive and Deep attention mechanisms are likely to be better at preserving the information between the hidden states and the model output (compared to Scaled Dot-product); (ii) ablation studies indicate that Additive attention can actively learn to explain the importance of its input hidden representations; (iii) when attention values are nearly the same, the rank order of attention values is not consistent with the rank order of the mutual information(iv) Using Gumbel-Softmax with a temperature lower than one, tends to produce a more skewed attention score distribution compared to softmax and hence is a better choice for explainable design; (v) some building blocks are better at preserving the correlation between the ordered list of mutual information and attention weights order (for e.g., the combination of BiLSTM encoder and Additive attention). Our findings indicate that attention mechanisms do have the potential to function as a shortcut to model explanations when they are carefully combined with other model elements.
Causal-TGAN: Generating Tabular Data Using Causal Generative Adversarial Networks
Apr 21, 2021
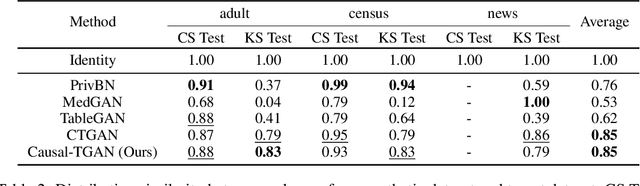
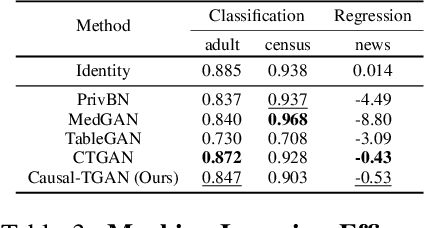
Synthetic data generation becomes prevalent as a solution to privacy leakage and data shortage. Generative models are designed to generate a realistic synthetic dataset, which can precisely express the data distribution for the real dataset. The generative adversarial networks (GAN), which gain great success in the computer vision fields, are doubtlessly used for synthetic data generation. Though there are prior works that have demonstrated great progress, most of them learn the correlations in the data distributions rather than the true processes in which the datasets are naturally generated. Correlation is not reliable for it is a statistical technique that only tells linear dependencies and is easily affected by the dataset's bias. Causality, which encodes all underlying factors of how the real data be naturally generated, is more reliable than correlation. In this work, we propose a causal model named Causal Tabular Generative Neural Network (Causal-TGAN) to generate synthetic tabular data using the tabular data's causal information. Extensive experiments on both simulated datasets and real datasets demonstrate the better performance of our method when given the true causal graph and a comparable performance when using the estimated causal graph.
ROMark: A Robust Watermarking System Using Adversarial Training
Oct 02, 2019
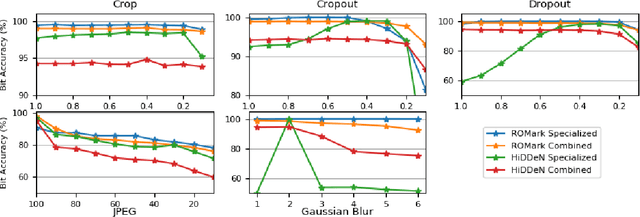

The availability and easy access to digital communication increase the risk of copyrighted material piracy. In order to detect illegal use or distribution of data, digital watermarking has been proposed as a suitable tool. It protects the copyright of digital content by embedding imperceptible information into the data in the presence of an adversary. The goal of the adversary is to remove the copyrighted content of the data. Therefore, an efficient watermarking framework must be robust to multiple image-processing operations known as attacks that can alter embedded copyright information. Another line of research \textit{adversarial machine learning} also tackles with similar problems to guarantee robustness to imperceptible perturbations of the input. In this work, we propose to apply robust optimization from adversarial machine learning to improve the robustness of a CNN-based watermarking framework. Our experimental results on the COCO dataset show that the robustness of a watermarking framework can be improved by utilizing robust optimization in training.