 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe reinforcement learning with self-improving hard constraints for multi-energy management systems
Apr 18, 2023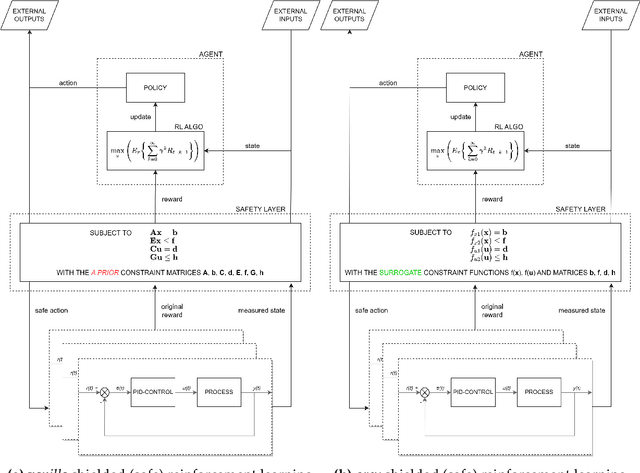
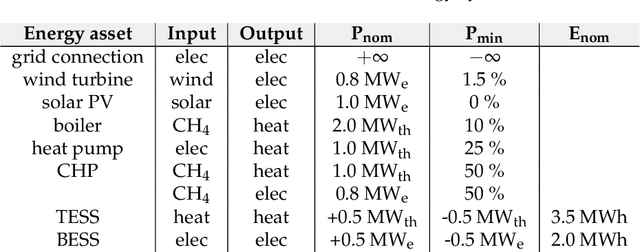


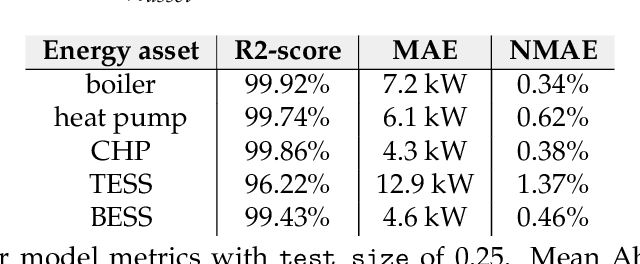
Safe reinforcement learning (RL) with hard constraint guarantees is a promising optimal control direction for multi-energy management systems. It only requires the environment-specific constraint functions itself a prior and not a complete model (i.e. plant, disturbance and noise models, and prediction models for states not included in the plant model - e.g. demand, weather, and price forecasts). The project-specific upfront and ongoing engineering efforts are therefore still reduced, better representations of the underlying system dynamics can still be learned and modeling bias is kept to a minimum (no model-based objective function). However, even the constraint functions alone are not always trivial to accurately provide in advance (e.g. an energy balance constraint requires the detailed determination of all energy inputs and outputs), leading to potentially unsafe behavior. In this paper, we present two novel advancements: (I) combining the Optlayer and SafeFallback method, named OptLayerPolicy, to increase the initial utility while keeping a high sample efficiency. (II) introducing self-improving hard constraints, to increase the accuracy of the constraint functions as more data becomes available so that better policies can be learned. Both advancements keep the constraint formulation decoupled from the RL formulation, so that new (presumably better) RL algorithms can act as drop-in replacements. We have shown that, in a simulated multi-energy system case study, the initial utility is increased to 92.4% (OptLayerPolicy) compared to 86.1% (OptLayer) and that the policy after training is increased to 104.9% (GreyOptLayerPolicy) compared to 103.4% (OptLayer) - all relative to a vanilla RL benchmark. While introducing surrogate functions into the optimization problem requires special attention, we do conclude that the newly presented GreyOptLayerPolicy method is the most advantageous.
Safe reinforcement learning for multi-energy management systems with known constraint functions
Jul 19, 2022
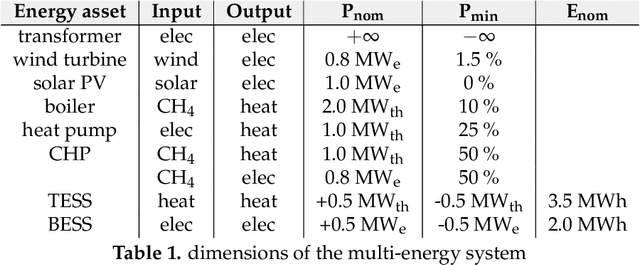

Reinforcement learning (RL) is a promising optimal control technique for multi-energy management systems. It does not require a model a priori - reducing the upfront and ongoing project-specific engineering effort and is capable of learning better representations of the underlying system dynamics. However, vanilla RL does not provide constraint satisfaction guarantees - resulting in various potentially unsafe interactions within its safety-critical environment. In this paper, we present two novel safe RL methods, namely SafeFallback and GiveSafe, where the safety constraint formulation is decoupled from the RL formulation and which provides hard-constraint satisfaction guarantees both during training a (near) optimal policy (which involves exploratory and exploitative, i.e. greedy, steps) as well as during deployment of any policy (e.g. random agents or offline trained RL agents). In a simulated multi-energy systems case study we have shown that both methods start with a significantly higher utility (i.e. useful policy) compared to a vanilla RL benchmark (94,6% and 82,8% compared to 35,5%) and that the proposed SafeFallback method even can outperform the vanilla RL benchmark (102,9% to 100%). We conclude that both methods are viably safety constraint handling techniques applicable beyond RL, as demonstrated with random policies while still providing hard-constraint guarantees. Finally, we propose directions for future work to i.a. improve the constraint functions itself as more data becomes available.
Model-predictive control and reinforcement learning in multi-energy system case studies
Apr 20, 2021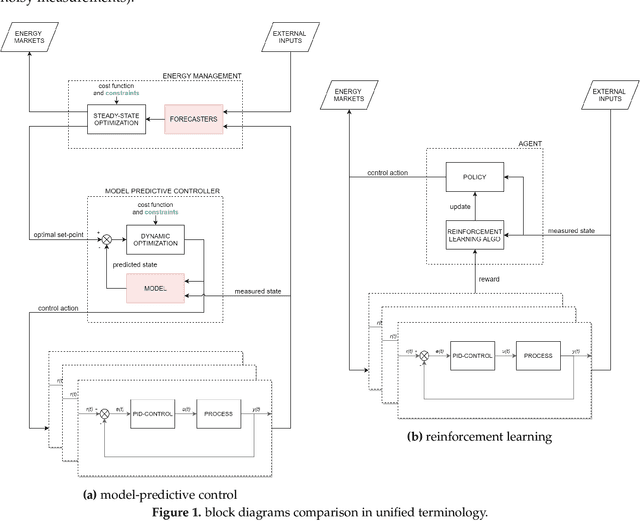

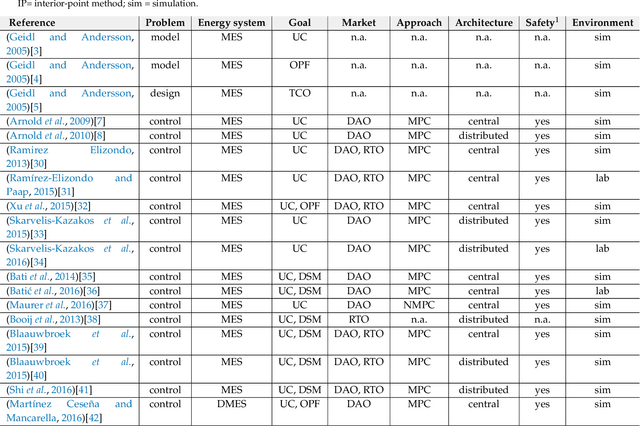
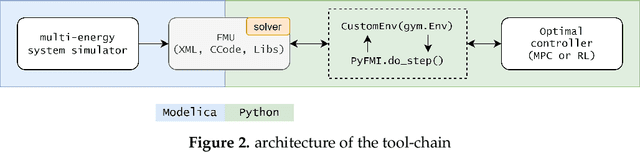
Model-predictive-control (MPC) offers an optimal control technique to establish and ensure that the total operation cost of multi-energy systems remains at a minimum while fulfilling all system constraints. However, this method presumes an adequate model of the underlying system dynamics, which is prone to modelling errors and is not necessarily adaptive. This has an associated initial and ongoing project-specific engineering cost. In this paper, we present an on- and off-policy multi-objective reinforcement learning (RL) approach, that does not assume a model a priori, benchmarking this against a linear MPC (LMPC - to reflect current practice, though non-linear MPC performs better) - both derived from the general optimal control problem, highlighting their differences and similarities. In a simple multi-energy system (MES) configuration case study, we show that a twin delayed deep deterministic policy gradient (TD3) RL agent offers potential to match and outperform the perfect foresight LMPC benchmark (101.5%). This while the realistic LMPC, i.e. imperfect predictions, only achieves 98%. While in a more complex MES system configuration, the RL agent's performance is generally lower (94.6%), yet still better than the realistic LMPC (88.9%). In both case studies, the RL agents outperformed the realistic LMPC after a training period of 2 years using quarterly interactions with the environment. We conclude that reinforcement learning is a viable optimal control technique for multi-energy systems given adequate constraint handling and pre-training, to avoid unsafe interactions and long training periods, as is proposed in fundamental future work.