 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe reinforcement learning for multi-energy management systems with known constraint functions
Paper and Code
Jul 19, 2022
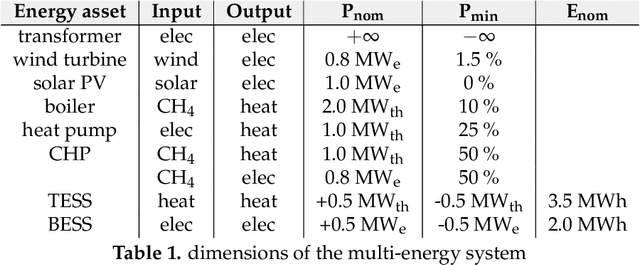

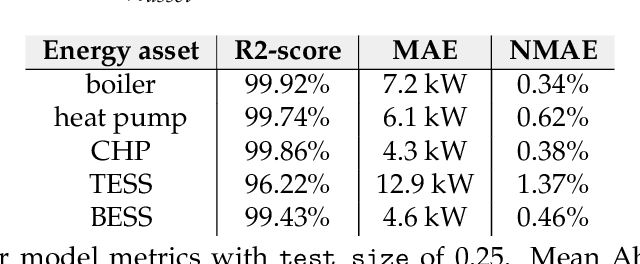
Reinforcement learning (RL) is a promising optimal control technique for multi-energy management systems. It does not require a model a priori - reducing the upfront and ongoing project-specific engineering effort and is capable of learning better representations of the underlying system dynamics. However, vanilla RL does not provide constraint satisfaction guarantees - resulting in various potentially unsafe interactions within its safety-critical environment. In this paper, we present two novel safe RL methods, namely SafeFallback and GiveSafe, where the safety constraint formulation is decoupled from the RL formulation and which provides hard-constraint satisfaction guarantees both during training a (near) optimal policy (which involves exploratory and exploitative, i.e. greedy, steps) as well as during deployment of any policy (e.g. random agents or offline trained RL agents). In a simulated multi-energy systems case study we have shown that both methods start with a significantly higher utility (i.e. useful policy) compared to a vanilla RL benchmark (94,6% and 82,8% compared to 35,5%) and that the proposed SafeFallback method even can outperform the vanilla RL benchmark (102,9% to 100%). We conclude that both methods are viably safety constraint handling techniques applicable beyond RL, as demonstrated with random policies while still providing hard-constraint guarantees. Finally, we propose directions for future work to i.a. improve the constraint functions itself as more data becomes available.