 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Dynamics of Gradient Descent for Overparametrized Neural Networks
May 13, 2021
We consider the dynamics of gradient descent (GD) in overparameterized single hidden layer neural networks with a squared loss function. Recently, it has been shown that, under some conditions, the parameter values obtained using GD achieve zero training error and generalize well if the initial conditions are chosen appropriately. Here, through a Lyapunov analysis, we show that the dynamics of neural network weights under GD converge to a point which is close to the minimum norm solution subject to the condition that there is no training error when using the linear approximation to the neural network. To illustrate the application of this result, we show that the GD converges to a prediction function that generalizes well, thereby providing an alternative proof of the generalization results in Arora et al. (2019).
The Global Landscape of Neural Networks: An Overview
Jul 02, 2020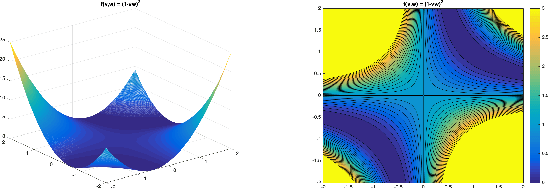
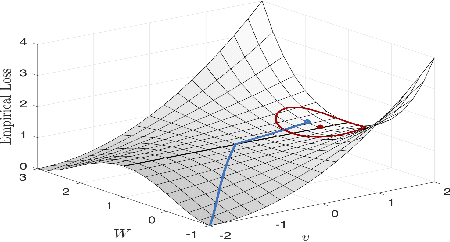
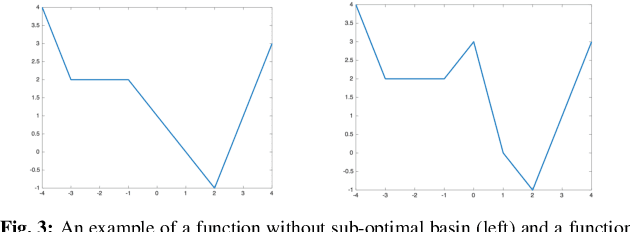
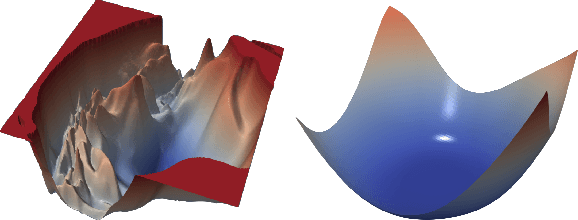
One of the major concerns for neural network training is that the non-convexity of the associated loss functions may cause bad landscape. The recent success of neural networks suggests that their loss landscape is not too bad, but what specific results do we know about the landscape? In this article, we review recent findings and results on the global landscape of neural networks. First, we point out that wide neural nets may have sub-optimal local minima under certain assumptions. Second, we discuss a few rigorous results on the geometric properties of wide networks such as "no bad basin", and some modifications that eliminate sub-optimal local minima and/or decreasing paths to infinity. Third, we discuss visualization and empirical explorations of the landscape for practical neural nets. Finally, we briefly discuss some convergence results and their relation to landscape results.
Learning Latent Events from Network Message Logs: A Decomposition Based Approach
Apr 10, 2018
In this communication, we describe a novel technique for event mining using a decomposition based approach that combines non-parametric change-point detection with LDA. We prove theoretical guarantees about sample-complexity and consistency of the approach. In a companion paper, we will perform a thorough evaluation of our approach with detailed experiments.