 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopy Move Source-Target Disambiguation through Multi-Branch CNNs
Dec 29, 2019



We propose a method to identify the source and target regions of a copy-move forgery so allow a correct localisation of the tampered area. First, we cast the problem into a hypothesis testing framework whose goal is to decide which region between the two nearly-duplicate regions detected by a generic copy-move detector is the original one. Then we design a multi-branch CNN architecture that solves the hypothesis testing problem by learning a set of features capable to reveal the presence of interpolation artefacts and boundary inconsistencies in the copy-moved area. The proposed architecture, trained on a synthetic dataset explicitly built for this purpose, achieves good results on copy-move forgeries from both synthetic and realistic datasets. Based on our tests, the proposed disambiguation method can reliably reveal the target region even in realistic cases where an approximate version of the copy-move localization mask is provided by a state-of-the-art copy-move detection algorithm.
Hue Modification Localization By Pair Matching
Mar 05, 2019



Hue modification is the adjustment of hue property on color images. Conducting hue modification on an image is trivial, and it can be abused to falsify opinions of viewers. Since shapes, edges or textural information remains unchanged after hue modification, this type of manipulation is relatively hard to be detected and localized. Since small patches inherit the same Color Filter Array (CFA) configuration and demosaicing, any distortion made by local hue modification can be detected by patch matching within the same image. In this paper, we propose to localize hue modification by means of a Siamese neural network specifically designed for matching two inputs. By crafting the network outputs, we are able to form a heatmap which potentially highlights malicious regions. Our proposed method deals well not only with uncompressed images but also with the presence of JPEG compression, an operation usually hindering the exploitation of CFA and demosaicing artifacts. Experimental evidences corroborate the effectiveness of the proposed method.
Coulomb Autoencoders
Oct 19, 2018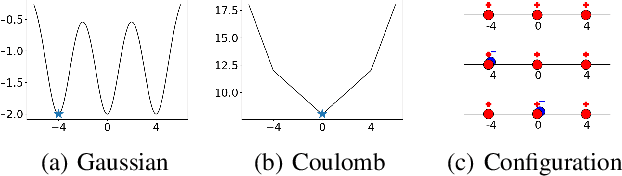
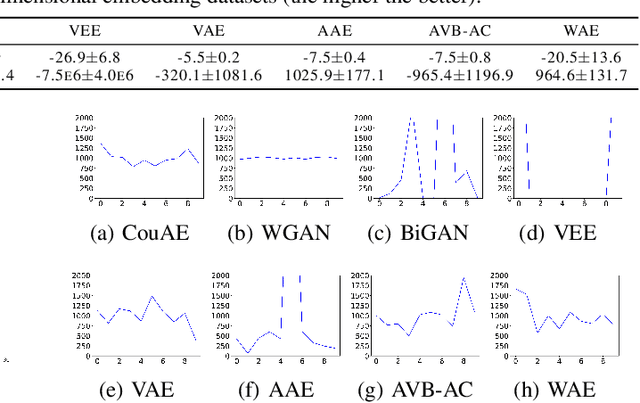
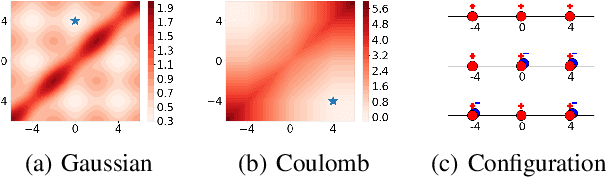
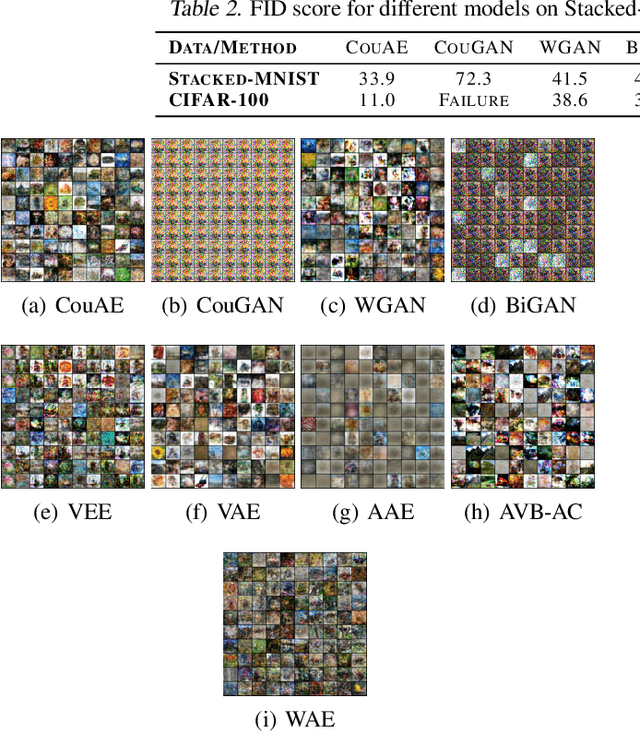
Estimating the true density in high-dimensional feature spaces is a well-known problem in machine learning. We propose a new implicit generative model based on autoencoders, whose training is guaranteed to converge to the global minimum of the objective function. This is achieved by using an appropriate family of kernel functions in the regularizer. Furthermore, we analyze the behaviour of the proposed model in the case of finite number of samples and provide an upper bound on the generalization error achieved by this global minimum. The theory is corroborated by extensive experimental comparisons on synthetic and real-world datasets against several approaches from the families of generative adversarial networks and autoencoder-based models.
Accurate and Scalable Image Clustering Based On Sparse Representation of Camera Fingerprint
Oct 18, 2018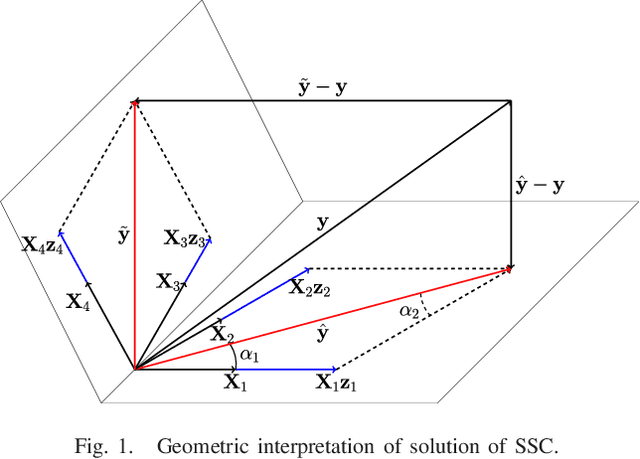
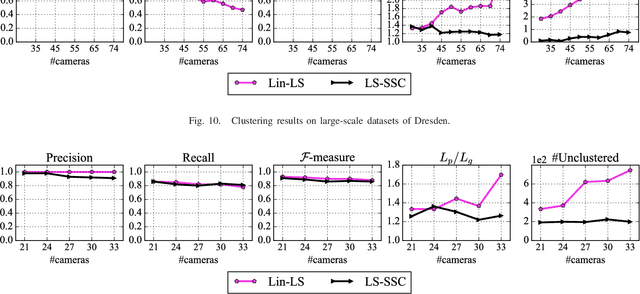
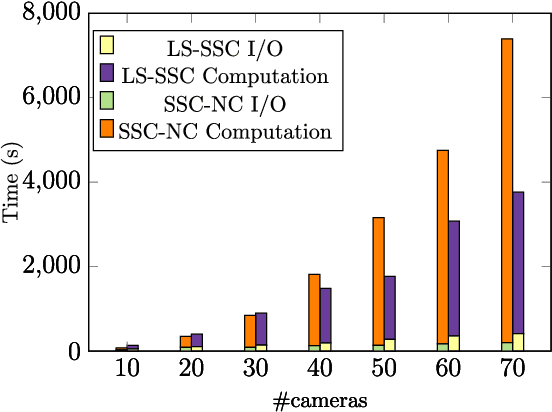
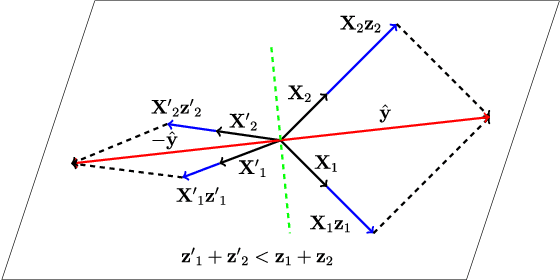
Clustering images according to their acquisition devices is a well-known problem in multimedia forensics, which is typically faced by means of camera Sensor Pattern Noise (SPN). Such an issue is challenging since SPN is a noise-like signal, hard to be estimated and easy to be attenuated or destroyed by many factors. Moreover, the high dimensionality of SPN hinders large-scale applications. Existing approaches are typically based on the correlation among SPNs in the pixel domain, which might not be able to capture intrinsic data structure in union of vector subspaces. In this paper, we propose an accurate clustering framework, which exploits linear dependencies among SPNs in their intrinsic vector subspaces. Such dependencies are encoded under sparse representations which are obtained by solving a Lasso problem with non-negativity constraint. The proposed framework is highly accurate in number of clusters estimation and fingerprint association. Moreover, our framework is scalable to the number of images and robust against double JPEG compression as well as the presence of outliers, owning big potential for real-world applications. Experimental results on Dresden and Vision database show that our proposed framework can adapt well to both medium-scale and large-scale contexts, and outperforms state-of-the-art methods.