 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompleteness of Unbounded Best-First Minimax and Descent Minimax
Mar 25, 2026In this article, we focus on search algorithms for two-player perfect information games, whose objective is to determine the best possible strategy, and ideally a winning strategy. Unfortunately, some search algorithms for games in the literature are not able to always determine a winning strategy, even with an infinite search time. This is the case, for example, of the following algorithms: Unbounded Best-First Minimax and Descent Minimax, which are core algorithms in state-of-the-art knowledge-free reinforcement learning. They were then improved with the so-called completion technique. However, whether this technique sufficiently improves these algorithms to allow them to always determine a winning strategy remained an open question until now. To answer this question, we generalize the two algorithms (their versions using the completion technique), and we show that any algorithm of this class of algorithms computes the best strategy. Finally, we experimentally show that the completion technique improves winning performance.
Minibal: Balanced Game-Playing Without Opponent Modeling
Mar 24, 2026Recent advances in game AI, such as AlphaZero and Athénan, have achieved superhuman performance across a wide range of board games. While highly powerful, these agents are ill-suited for human-AI interaction, as they consistently overwhelm human players, offering little enjoyment and limited educational value. This paper addresses the problem of balanced play, in which an agent challenges its opponent without either dominating or conceding. We introduce Minibal (Minimize & Balance), a variant of Minimax specifically designed for balanced play. Building on this concept, we propose several modifications of the Unbounded Minimax algorithm explicitly aimed at discovering balanced strategies. Experiments conducted across seven board games demonstrate that one variant consistently achieves the most balanced play, with average outcomes close to perfect balance. These results establish Minibal as a promising foundation for designing AI agents that are both challenging and engaging, suitable for both entertainment and serious games.
Deciding the Satisfiability of Combined Qualitative Constraint Networks
Feb 09, 2026Among the various forms of reasoning studied in the context of artificial intelligence, qualitative reasoning makes it possible to infer new knowledge in the context of imprecise, incomplete information without numerical values. In this paper, we propose a formal framework unifying several forms of extensions and combinations of qualitative formalisms, including multi-scale reasoning, temporal sequences, and loose integrations. This framework makes it possible to reason in the context of each of these combinations and extensions, but also to study in a unified way the satisfiability decision and its complexity. In particular, we establish two complementary theorems guaranteeing that the satisfiability decision is polynomial, and we use them to recover the known results of the size-topology combination. We also generalize the main definition of qualitative formalism to include qualitative formalisms excluded from the definitions of the literature, important in the context of combinations.
On some improvements to Unbounded Minimax
May 07, 2025This paper presents the first experimental evaluation of four previously untested modifications of Unbounded Best-First Minimax algorithm. This algorithm explores the game tree by iteratively expanding the most promising sequences of actions based on the current partial game tree. We first evaluate the use of transposition tables, which convert the game tree into a directed acyclic graph by merging duplicate states. Second, we compare the original algorithm by Korf & Chickering with the variant proposed by Cohen-Solal, which differs in its backpropagation strategy: instead of stopping when a stable value is encountered, it updates values up to the root. This change slightly improves performance when value ties or transposition tables are involved. Third, we assess replacing the exact terminal evaluation function with the learned heuristic function. While beneficial when exact evaluations are costly, this modification reduces performance in inexpensive settings. Finally, we examine the impact of the completion technique that prioritizes resolved winning states and avoids resolved losing states. This technique also improves performance. Overall, our findings highlight how targeted modifications can enhance the efficiency of Unbounded Best-First Minimax.
Study and improvement of search algorithms in two-players perfect information games
May 06, 2025Games, in their mathematical sense, are everywhere (game industries, economics, defense, education, chemistry, biology, ...).Search algorithms in games are artificial intelligence methods for playing such games. Unfortunately, there is no study on these algorithms that evaluates the generality of their performance. We propose to address this gap in the case of two-player zero-sum games with perfect information. Furthermore, we propose a new search algorithm and we show that, for a short search time, it outperforms all studied algorithms on all games in this large experiment and that, for a medium search time, it outperforms all studied algorithms on 17 of the 22 studied games.
The Mathematical Game
Sep 22, 2023



Monte Carlo Tree Search can be used for automated theorem proving. Holophrasm is a neural theorem prover using MCTS combined with neural networks for the policy and the evaluation. In this paper we propose to improve the performance of the Holophrasm theorem prover using other game tree search algorithms.
Learning to Play Stochastic Two-player Perfect-Information Games without Knowledge
Feb 08, 2023In this paper, we extend the Descent framework, which enables learning and planning in the context of two-player games with perfect information, to the framework of stochastic games. We propose two ways of doing this, the first way generalizes the search algorithm, i.e. Descent, to stochastic games and the second way approximates stochastic games by deterministic games. We then evaluate them on the game EinStein wurfelt nicht! against state-of-the-art algorithms: Expectiminimax and Polygames (i.e. the Alpha Zero algorithm). It is our generalization of Descent which obtains the best results. The approximation by deterministic games nevertheless obtains good results, presaging that it could give better results in particular contexts.
Completeness of Unbounded Best-First Game Algorithms
Sep 11, 2021In this article, we prove the completeness of the following game search algorithms: unbounded best-first minimax with completion and descent with completion, i.e. we show that, with enough time, they find the best game strategy. We then generalize these two algorithms in the context of perfect information multiplayer games. We show that these generalizations are also complete: they find one of the equilibrium points.
Minimax Strikes Back
Dec 19, 2020
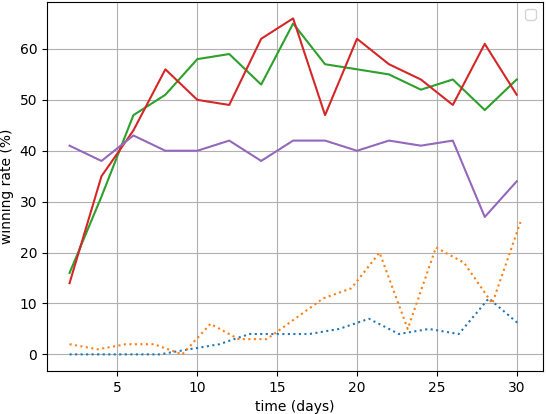
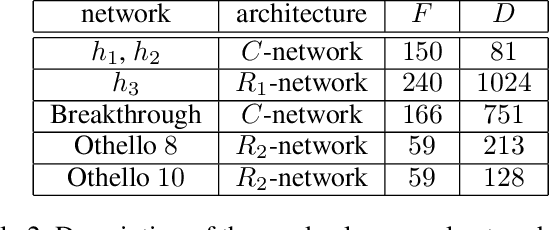
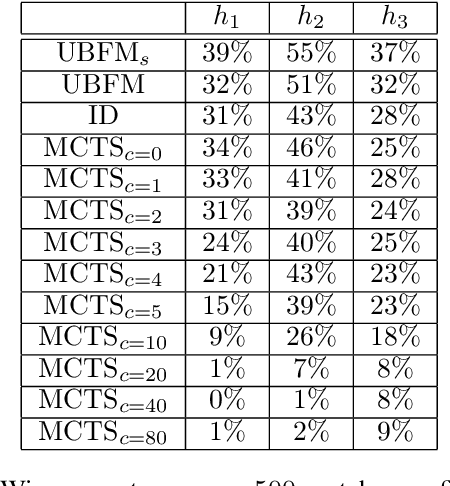
Deep Reinforcement Learning (DRL) reaches a superhuman level of play in many complete information games. The state of the art search algorithm used in combination with DRL is Monte Carlo Tree Search (MCTS). We take another approach to DRL using a Minimax algorithm instead of MCTS and learning only the evaluation of states, not the policy. We show that for multiple games it is competitive with the state of the art DRL for the learning performances and for the confrontations.
Learning to Play Two-Player Perfect-Information Games without Knowledge
Aug 03, 2020
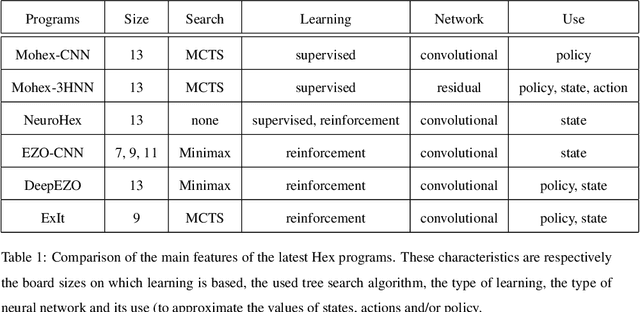
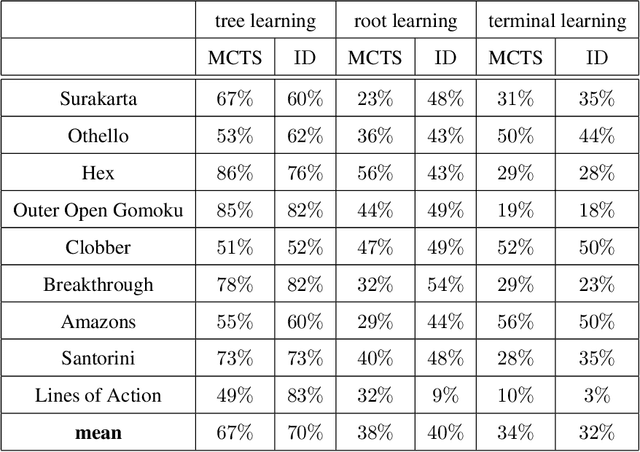
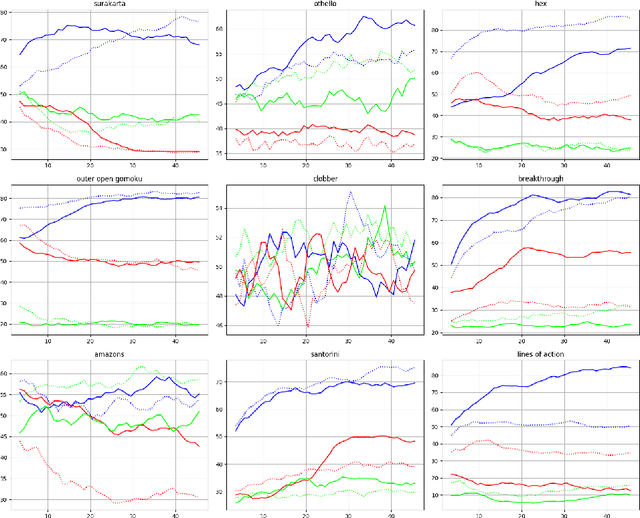
In this paper, several techniques for learning game state evaluation functions by reinforcement are proposed. The first is a generalization of tree bootstrapping (tree learning): it is adapted to the context of reinforcement learning without knowledge based on non-linear functions. With this technique, no information is lost during the reinforcement learning process. The second is a modification of minimax with unbounded depth extending the best sequences of actions to the terminal states. This modified search is intended to be used during the learning process. The third is to replace the classic gain of a game (+1 / -1) with a reinforcement heuristic. We study particular reinforcement heuristics such as: quick wins and slow defeats ; scoring ; mobility or presence. The four is another variant of unbounded minimax, which plays the safest action instead of playing the best action. This modified search is intended to be used after the learning process. The five is a new action selection distribution. The conducted experiments suggest that these techniques improve the level of play. Finally, we apply these different techniques to design program-players to the game of Hex (size 11 and 13) surpassing the level of Mohex 2.0 with reinforcement learning from self-play without knowledge. At Hex size 11 (without swap), the program-player reaches the level of Mohex 3HNN.