Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Strikes Back
Paper and Code
Dec 19, 2020
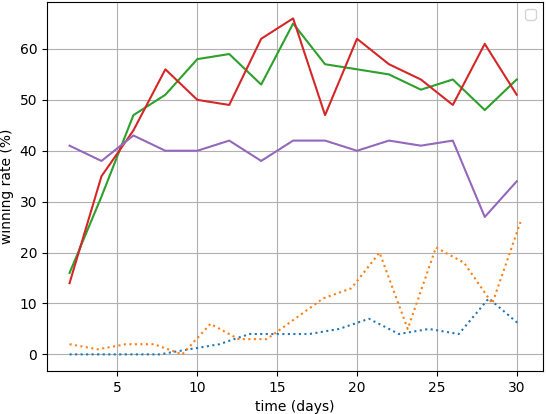
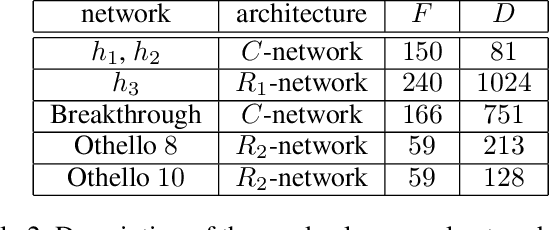
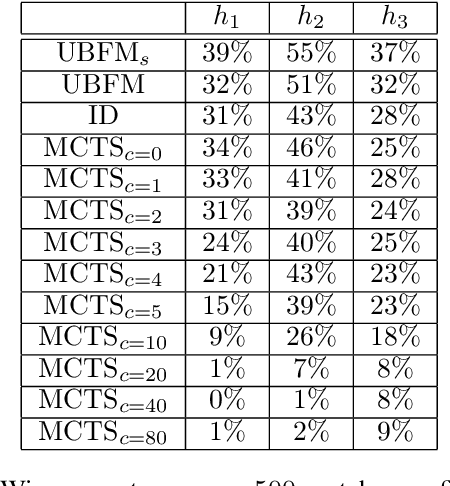
Deep Reinforcement Learning (DRL) reaches a superhuman level of play in many complete information games. The state of the art search algorithm used in combination with DRL is Monte Carlo Tree Search (MCTS). We take another approach to DRL using a Minimax algorithm instead of MCTS and learning only the evaluation of states, not the policy. We show that for multiple games it is competitive with the state of the art DRL for the learning performances and for the confrontations.
View paper on