 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor for Debias: Mitigating Model Bias with Backdoor Attack-based Artificial Bias
Mar 01, 2023
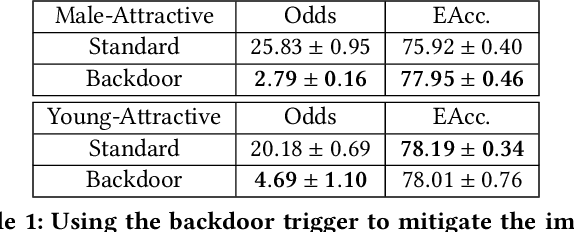
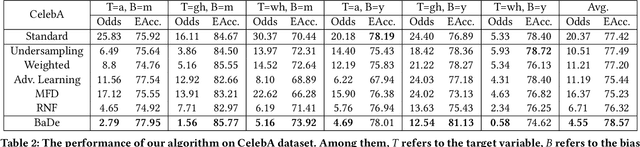
With the swift advancement of deep learning, state-of-the-art algorithms have been utilized in various social situations. Nonetheless, some algorithms have been discovered to exhibit biases and provide unequal results. The current debiasing methods face challenges such as poor utilization of data or intricate training requirements. In this work, we found that the backdoor attack can construct an artificial bias similar to the model bias derived in standard training. Considering the strong adjustability of backdoor triggers, we are motivated to mitigate the model bias by carefully designing reverse artificial bias created from backdoor attack. Based on this, we propose a backdoor debiasing framework based on knowledge distillation, which effectively reduces the model bias from original data and minimizes security risks from the backdoor attack. The proposed solution is validated on both image and structured datasets, showing promising results. This work advances the understanding of backdoor attacks and highlights its potential for beneficial applications. The code for the study can be found at \url{https://anonymous.4open.science/r/DwB-BC07/}.
Debiasing Backdoor Attack: A Benign Application of Backdoor Attack in Eliminating Data Bias
Feb 18, 2022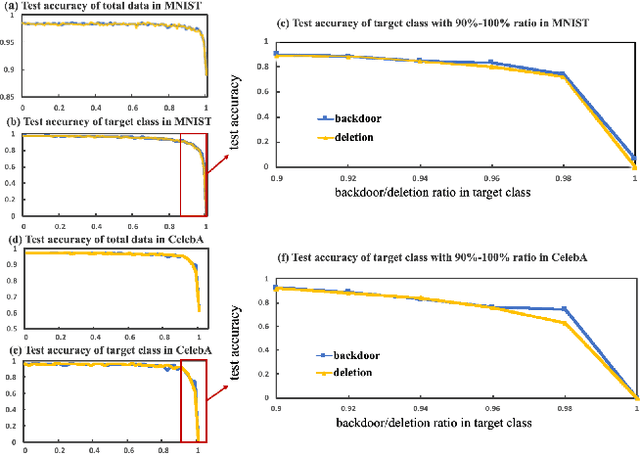
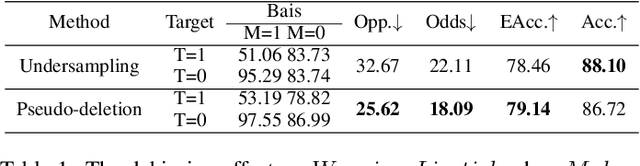
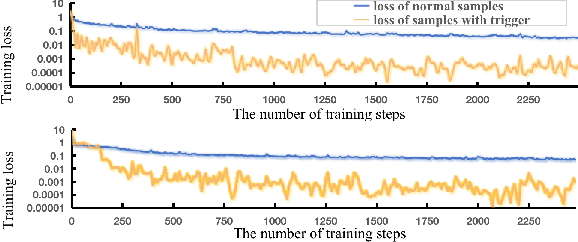
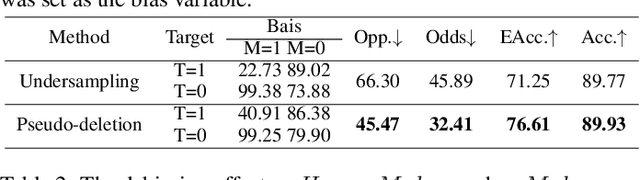
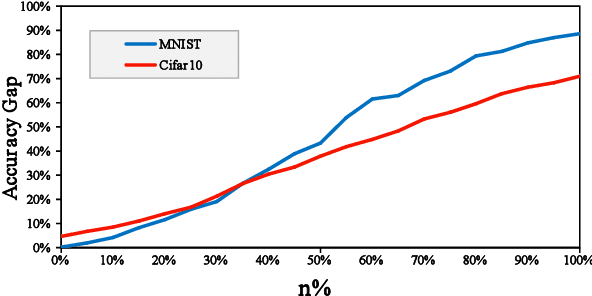
Backdoor attack is a new AI security risk that has emerged in recent years. Drawing on the previous research of adversarial attack, we argue that the backdoor attack has the potential to tap into the model learning process and improve model performance. Based on Clean Accuracy Drop (CAD) in backdoor attack, we found that CAD came out of the effect of pseudo-deletion of data. We provided a preliminary explanation of this phenomenon from the perspective of model classification boundaries and observed that this pseudo-deletion had advantages over direct deletion in the data debiasing problem. Based on the above findings, we proposed Debiasing Backdoor Attack (DBA). It achieves SOTA in the debiasing task and has a broader application scenario than undersampling.