 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Knowledge Embedding Based on Recursive Neural Network for Multi-Disease Diagnosis
Sep 22, 2018
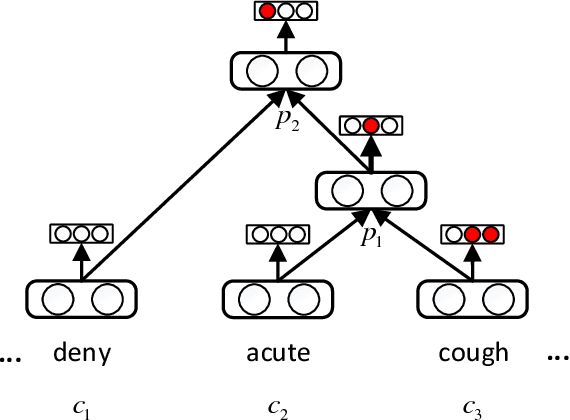

The representation of knowledge based on first-order logic captures the richness of natural language and supports multiple probabilistic inference models. Although symbolic representation enables quantitative reasoning with statistical probability, it is difficult to utilize with machine learning models as they perform numerical operations. In contrast, knowledge embedding (i.e., high-dimensional and continuous vectors) is a feasible approach to complex reasoning that can not only retain the semantic information of knowledge but also establish the quantifiable relationship among them. In this paper, we propose recursive neural knowledge network (RNKN), which combines medical knowledge based on first-order logic with recursive neural network for multi-disease diagnosis. After RNKN is efficiently trained from manually annotated Chinese Electronic Medical Records (CEMRs), diagnosis-oriented knowledge embeddings and weight matrixes are learned. Experimental results verify that the diagnostic accuracy of RNKN is superior to that of some classical machine learning models and Markov logic network (MLN). The results also demonstrate that the more explicit the evidence extracted from CEMRs is, the better is the performance achieved. RNKN gradually exhibits the interpretation of knowledge embeddings as the number of training epochs increases.
Learning and inference in knowledge-based probabilistic model for medical diagnosis
Mar 28, 2017


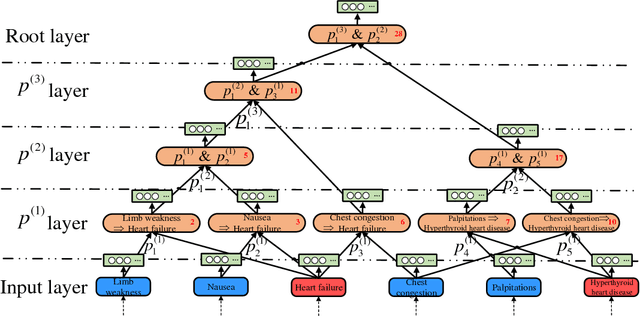
Based on a weighted knowledge graph to represent first-order knowledge and combining it with a probabilistic model, we propose a methodology for the creation of a medical knowledge network (MKN) in medical diagnosis. When a set of symptoms is activated for a specific patient, we can generate a ground medical knowledge network composed of symptom nodes and potential disease nodes. By Incorporating a Boltzmann machine into the potential function of a Markov network, we investigated the joint probability distribution of the MKN. In order to deal with numerical symptoms, a multivariate inference model is presented that uses conditional probability. In addition, the weights for the knowledge graph were efficiently learned from manually annotated Chinese Electronic Medical Records (CEMRs). In our experiments, we found numerically that the optimum choice of the quality of disease node and the expression of symptom variable can improve the effectiveness of medical diagnosis. Our experimental results comparing a Markov logic network and the logistic regression algorithm on an actual CEMR database indicate that our method holds promise and that MKN can facilitate studies of intelligent diagnosis.
Building a comprehensive syntactic and semantic corpus of Chinese clinical texts
Nov 08, 2016
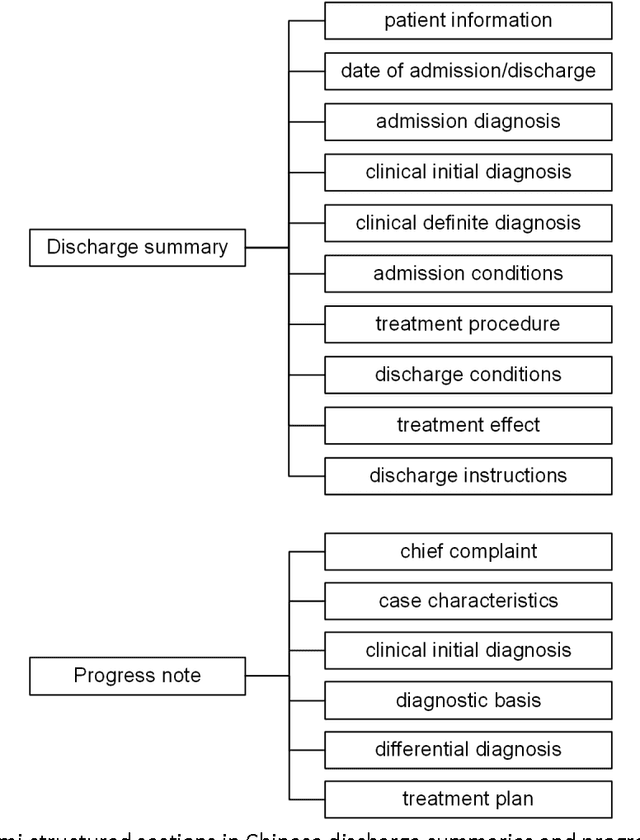
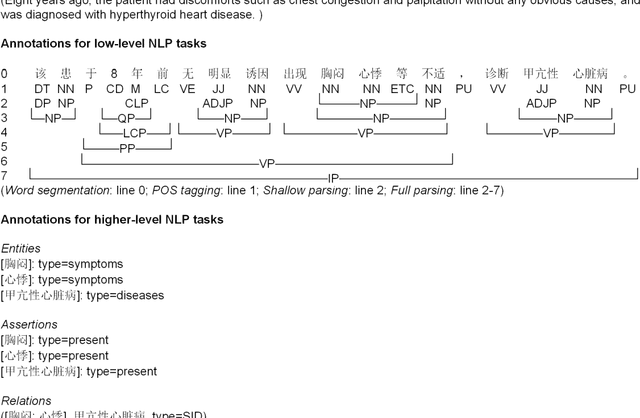
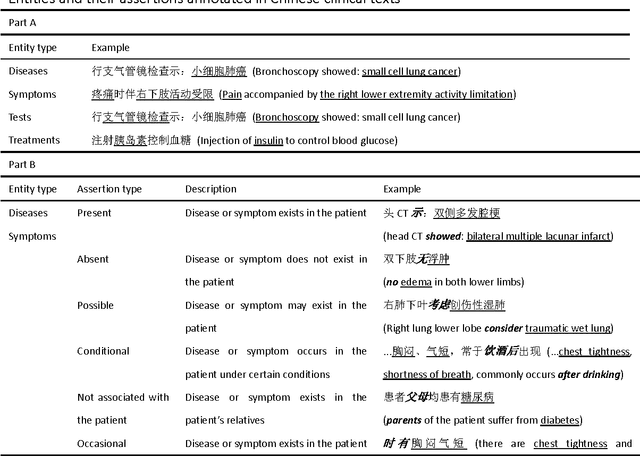
Objective: To build a comprehensive corpus covering syntactic and semantic annotations of Chinese clinical texts with corresponding annotation guidelines and methods as well as to develop tools trained on the annotated corpus, which supplies baselines for research on Chinese texts in the clinical domain. Materials and methods: An iterative annotation method was proposed to train annotators and to develop annotation guidelines. Then, by using annotation quality assurance measures, a comprehensive corpus was built, containing annotations of part-of-speech (POS) tags, syntactic tags, entities, assertions, and relations. Inter-annotator agreement (IAA) was calculated to evaluate the annotation quality and a Chinese clinical text processing and information extraction system (CCTPIES) was developed based on our annotated corpus. Results: The syntactic corpus consists of 138 Chinese clinical documents with 47,424 tokens and 2553 full parsing trees, while the semantic corpus includes 992 documents that annotated 39,511 entities with their assertions and 7695 relations. IAA evaluation shows that this comprehensive corpus is of good quality, and the system modules are effective. Discussion: The annotated corpus makes a considerable contribution to natural language processing (NLP) research into Chinese texts in the clinical domain. However, this corpus has a number of limitations. Some additional types of clinical text should be introduced to improve corpus coverage and active learning methods should be utilized to promote annotation efficiency. Conclusions: In this study, several annotation guidelines and an annotation method for Chinese clinical texts were proposed, and a comprehensive corpus with its NLP modules were constructed, providing a foundation for further study of applying NLP techniques to Chinese texts in the clinical domain.