 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
Inverse IFEval: Can LLMs Unlearn Stubborn Training Conventions to Follow Real Instructions?
Sep 04, 2025Large Language Models (LLMs) achieve strong performance on diverse tasks but often exhibit cognitive inertia, struggling to follow instructions that conflict with the standardized patterns learned during supervised fine-tuning (SFT). To evaluate this limitation, we propose Inverse IFEval, a benchmark that measures models Counter-intuitive Abilitytheir capacity to override training-induced biases and comply with adversarial instructions. Inverse IFEval introduces eight types of such challenges, including Question Correction, Intentional Textual Flaws, Code without Comments, and Counterfactual Answering. Using a human-in-the-loop pipeline, we construct a dataset of 1012 high-quality Chinese and English questions across 23 domains, evaluated under an optimized LLM-as-a-Judge framework. Experiments on existing leading LLMs demonstrate the necessity of our proposed Inverse IFEval benchmark. Our findings emphasize that future alignment efforts should not only pursue fluency and factual correctness but also account for adaptability under unconventional contexts. We hope that Inverse IFEval serves as both a diagnostic tool and a foundation for developing methods that mitigate cognitive inertia, reduce overfitting to narrow patterns, and ultimately enhance the instruction-following reliability of LLMs in diverse and unpredictable real-world scenarios.
CMR motion artifact correction using generative adversarial nets
Feb 21, 2019
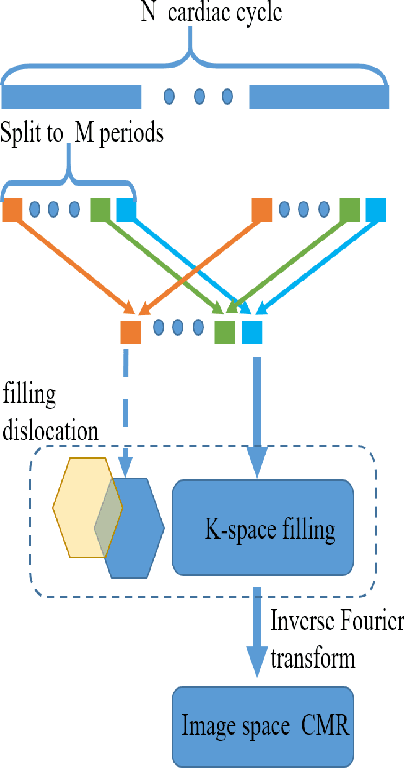

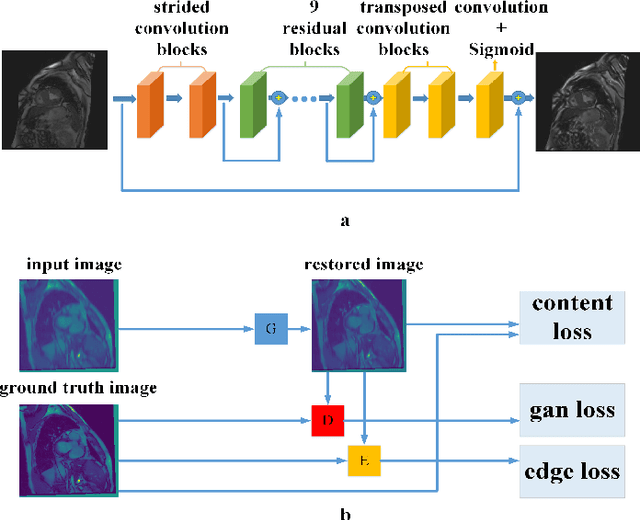
Cardiovascular Magnetic Resonance (CMR) plays an important role in the diagnoses and treatment of cardiovascular diseases while motion artifacts which are formed during the scanning process of CMR seriously affects doctors to find the exact focus. The current correction methods mainly focus on the K-space which is a grid of raw data obtained from the MR signal directly and then transfer to CMR image by inverse Fourier transform. They are neither effective nor efficient and can not be utilized in clinic. In this paper, we propose a novel approach for CMR motion artifact correction using deep learning. Specially, we use deep residual network (ResNet) as net framework and train our model in adversarial manner. Our approach is motivated by the connection between image motion blur and CMR motion artifact, so we can transfer methods from motion-deblur where deep learning has made great progress to CMR motion-correction successfully. To evaluate motion artifact correction methods, we propose a novel algorithm on how edge detection results are improved by deblurred algorithm. Boosted by deep learning and adversarial training algorithm, our model is trainable in an end-to-end manner, can be tested in real-time and achieves the state-of-art results for CMR correction.