 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pilots to Practices: A Scoping Review of GenAI-Enabled Personalization in Computer Science Education
Dec 23, 2025Generative AI enables personalized computer science education at scale, yet questions remain about whether such personalization supports or undermines learning. This scoping review synthesizes 32 studies (2023-2025) purposively sampled from 259 records to map personalization mechanisms and effectiveness signals in higher-education computer science contexts. We identify five application domains: intelligent tutoring, personalized materials, formative feedback, AI-augmented assessment, and code review, and analyze how design choices shape learning outcomes. Designs incorporating explanation-first guidance, solution withholding, graduated hint ladders, and artifact grounding (student code, tests, and rubrics) consistently show more positive learning processes than unconstrained chat interfaces. Successful implementations share four patterns: context-aware tutoring anchored in student artifacts, multi-level hint structures requiring reflection, composition with traditional CS infrastructure (autograders and rubrics), and human-in-the-loop quality assurance. We propose an exploration-first adoption framework emphasizing piloting, instrumentation, learning-preserving defaults, and evidence-based scaling. Recurrent risks include academic integrity, privacy, bias and equity, and over-reliance, and we pair these with operational mitigation. The evidence supports generative AI as a mechanism for precision scaffolding when embedded in audit-ready workflows that preserve productive struggle while scaling personalized support.
* Review article. 23 pages, 7 figures, 8 tables. Published in AI (MDPI), 2026
Optimizing Top Precision Performance Measure of Content-Based Image Retrieval by Learning Similarity Function
Aug 20, 2016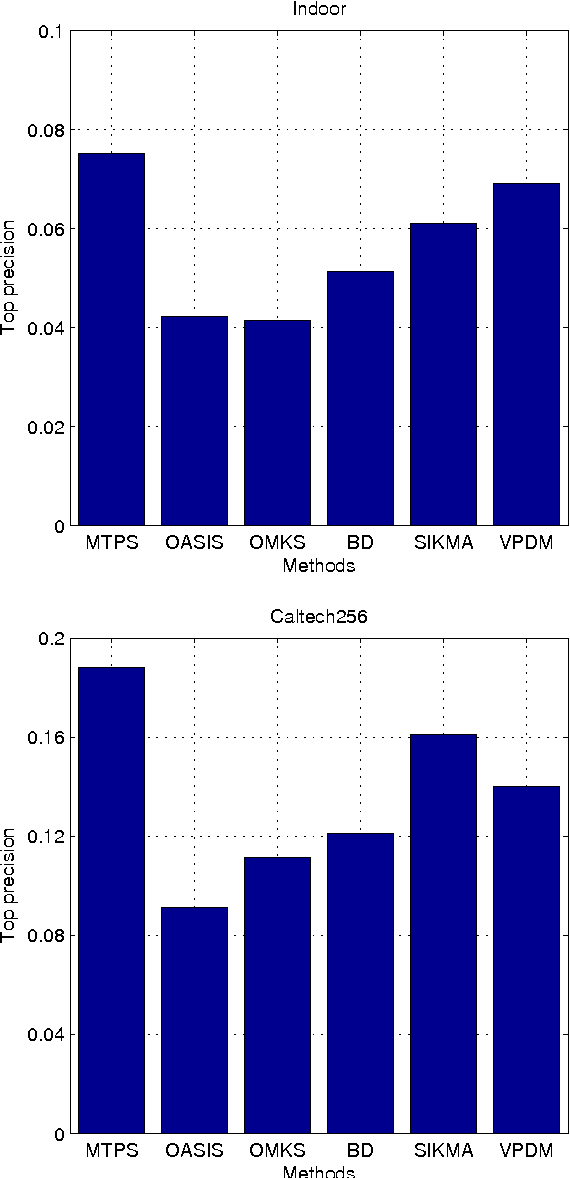
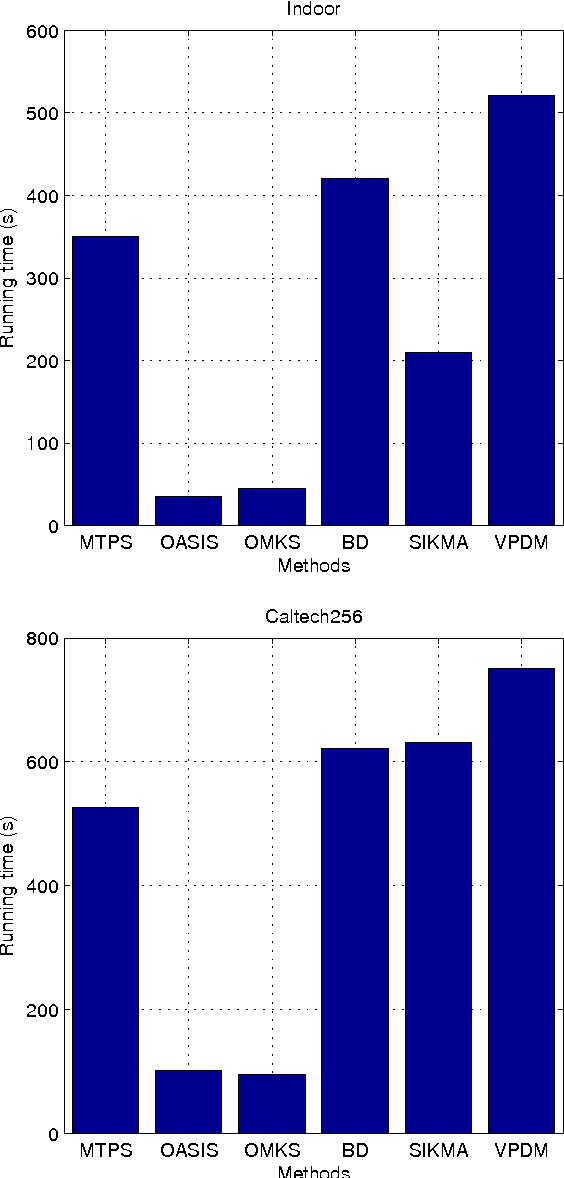
In this paper we study the problem of content-based image retrieval. In this problem, the most popular performance measure is the top precision measure, and the most important component of a retrieval system is the similarity function used to compare a query image against a database image. However, up to now, there is no existing similarity learning method proposed to optimize the top precision measure. To fill this gap, in this paper, we propose a novel similarity learning method to maximize the top precision measure. We model this problem as a minimization problem with an objective function as the combination of the losses of the relevant images ranked behind the top-ranked irrelevant image, and the squared Frobenius norm of the similarity function parameter. This minimization problem is solved as a quadratic programming problem. The experiments over two benchmark data sets show the advantages of the proposed method over other similarity learning methods when the top precision is used as the performance measure.