 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Hate Intensity of Twitter Conversation Threads
Jun 20, 2022
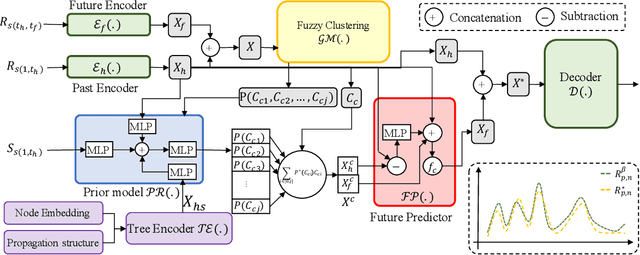

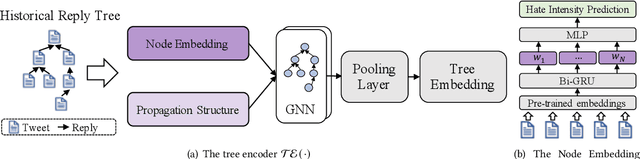
Tweets are the most concise form of communication in online social media, wherein a single tweet has the potential to make or break the discourse of the conversation. Online hate speech is more accessible than ever, and stifling its propagation is of utmost importance for social media companies and users for congenial communication. Most of the research barring a recent few has focused on classifying an individual tweet regardless of the tweet thread/context leading up to that point. One of the classical approaches to curb hate speech is to adopt a reactive strategy after the hate speech postage. The ex-post facto strategy results in neglecting subtle posts that do not show the potential to instigate hate speech on their own but may portend in the subsequent discussion ensuing in the post's replies. In this paper, we propose DRAGNET++, which aims to predict the intensity of hatred that a tweet can bring in through its reply chain in the future. It uses the semantic and propagating structure of the tweet threads to maximize the contextual information leading up to and the fall of hate intensity at each subsequent tweet. We explore three publicly available Twitter datasets -- Anti-Racism contains the reply tweets of a collection of social media discourse on racist remarks during US political and Covid-19 background; Anti-Social presents a dataset of 40 million tweets amidst the COVID-19 pandemic on anti-social behaviours; and Anti-Asian presents Twitter datasets collated based on anti-Asian behaviours during COVID-19 pandemic. All the curated datasets consist of structural graph information of the Tweet threads. We show that DRAGNET++ outperforms all the state-of-the-art baselines significantly. It beats the best baseline by an 11% margin on the Person correlation coefficient and a decrease of 25% on RMSE for the Anti-Racism dataset with a similar performance on the other two datasets.