 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Sequential Experimental Design for A/B Testing
May 13, 2026Experimental design has emerged as a powerful approach for improving the sample efficiency of A/B testing, yet existing designs rely critically on correctly specified models. We study robust sequential experimental design under model misspecification and develop a unified framework that covers both contextual bandit and dynamic settings. Theoretically, we prove that our design bounds the worst-case mean squared error of the estimated treatment effect. Empirically, we demonstrate the effectiveness of the proposed approach using synthetic and real-world datasets from a leading technology company.
Designing Time Series Experiments in A/B Testing with Transformer Reinforcement Learning
Feb 02, 2026A/B testing has become a gold standard for modern technological companies to conduct policy evaluation. Yet, its application to time series experiments, where policies are sequentially assigned over time, remains challenging. Existing designs suffer from two limitations: (i) they do not fully leverage the entire history for treatment allocation; (ii) they rely on strong assumptions to approximate the objective function (e.g., the mean squared error of the estimated treatment effect) for optimizing the design. We first establish an impossibility theorem showing that failure to condition on the full history leads to suboptimal designs, due to the dynamic dependencies in time series experiments. To address both limitations simultaneously, we next propose a transformer reinforcement learning (RL) approach which leverages transformers to condition allocation on the entire history and employs RL to directly optimize the MSE without relying on restrictive assumptions. Empirical evaluations on synthetic data, a publicly available dispatch simulator, and a real-world ridesharing dataset demonstrate that our proposal consistently outperforms existing designs.
Combining Experimental and Historical Data for Policy Evaluation
Jun 01, 2024



This paper studies policy evaluation with multiple data sources, especially in scenarios that involve one experimental dataset with two arms, complemented by a historical dataset generated under a single control arm. We propose novel data integration methods that linearly integrate base policy value estimators constructed based on the experimental and historical data, with weights optimized to minimize the mean square error (MSE) of the resulting combined estimator. We further apply the pessimistic principle to obtain more robust estimators, and extend these developments to sequential decision making. Theoretically, we establish non-asymptotic error bounds for the MSEs of our proposed estimators, and derive their oracle, efficiency and robustness properties across a broad spectrum of reward shift scenarios. Numerical experiments and real-data-based analyses from a ridesharing company demonstrate the superior performance of the proposed estimators.
An Analysis of Switchback Designs in Reinforcement Learning
Mar 26, 2024
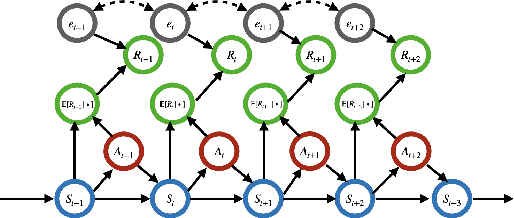
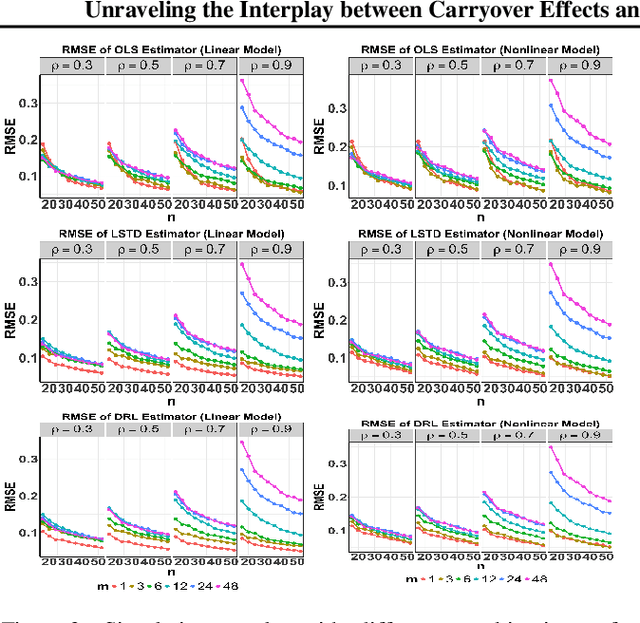
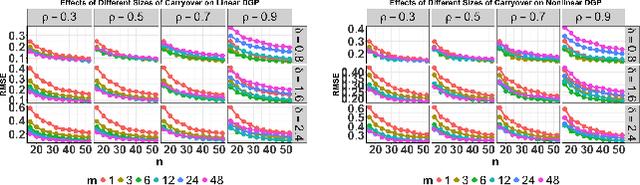
This paper offers a detailed investigation of switchback designs in A/B testing, which alternate between baseline and new policies over time. Our aim is to thoroughly evaluate the effects of these designs on the accuracy of their resulting average treatment effect (ATE) estimators. We propose a novel "weak signal analysis" framework, which substantially simplifies the calculations of the mean squared errors (MSEs) of these ATEs in Markov decision process environments. Our findings suggest that (i) when the majority of reward errors are positively correlated, the switchback design is more efficient than the alternating-day design which switches policies in a daily basis. Additionally, increasing the frequency of policy switches tends to reduce the MSE of the ATE estimator. (ii) When the errors are uncorrelated, however, all these designs become asymptotically equivalent. (iii) In cases where the majority of errors are negative correlated, the alternating-day design becomes the optimal choice. These insights are crucial, offering guidelines for practitioners on designing experiments in A/B testing. Our analysis accommodates a variety of policy value estimators, including model-based estimators, least squares temporal difference learning estimators, and double reinforcement learning estimators, thereby offering a comprehensive understanding of optimal design strategies for policy evaluation in reinforcement learning.