 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Passive Aggregation: Active Auditing and Topology-Aware Defense in Decentralized Federated Learning
Mar 19, 2026Decentralized Federated Learning (DFL) remains highly vulnerable to adaptive backdoor attacks designed to bypass traditional passive defense metrics. To address this limitation, we shift the defensive paradigm toward a novel active, interventional auditing framework. First, we establish a dynamical model to characterize the spatiotemporal diffusion of adversarial updates across complex graph topologies. Second, we introduce a suite of proactive auditing metrics, stochastic entropy anomaly, randomized smoothing Kullback-Leibler divergence, and activation kurtosis. These metrics utilize private probes to stress-test local models, effectively exposing latent backdoors that remain invisible to conventional static detection. Furthermore, we implement a topology-aware defense placement strategy to maximize global aggregation resilience. We provide theoretical property for the system's convergence under co-evolving attack and defense dynamics. Numeric empirical evaluations across diverse architectures demonstrate that our active framework is highly competitive with state-of-the-art defenses in mitigating stealthy, adaptive backdoors while preserving primary task utility.
An Analysis of Switchback Designs in Reinforcement Learning
Mar 26, 2024
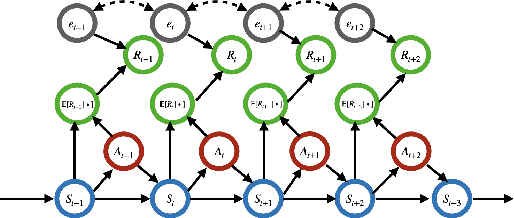
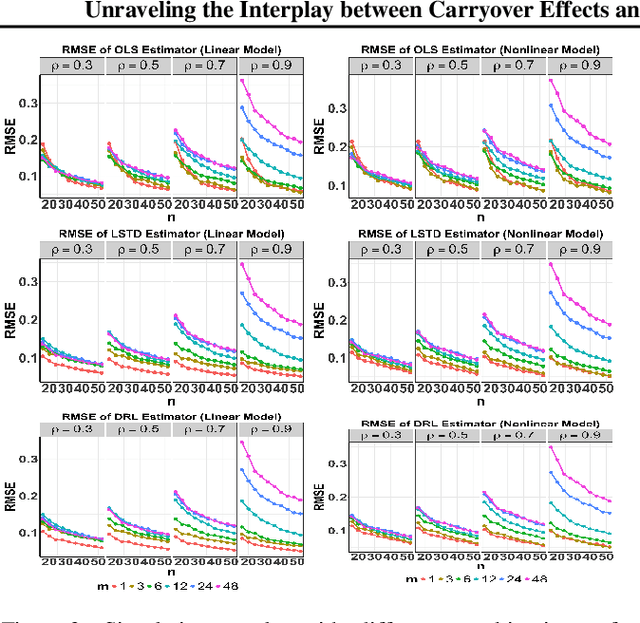
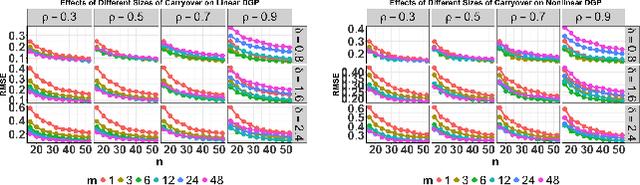
This paper offers a detailed investigation of switchback designs in A/B testing, which alternate between baseline and new policies over time. Our aim is to thoroughly evaluate the effects of these designs on the accuracy of their resulting average treatment effect (ATE) estimators. We propose a novel "weak signal analysis" framework, which substantially simplifies the calculations of the mean squared errors (MSEs) of these ATEs in Markov decision process environments. Our findings suggest that (i) when the majority of reward errors are positively correlated, the switchback design is more efficient than the alternating-day design which switches policies in a daily basis. Additionally, increasing the frequency of policy switches tends to reduce the MSE of the ATE estimator. (ii) When the errors are uncorrelated, however, all these designs become asymptotically equivalent. (iii) In cases where the majority of errors are negative correlated, the alternating-day design becomes the optimal choice. These insights are crucial, offering guidelines for practitioners on designing experiments in A/B testing. Our analysis accommodates a variety of policy value estimators, including model-based estimators, least squares temporal difference learning estimators, and double reinforcement learning estimators, thereby offering a comprehensive understanding of optimal design strategies for policy evaluation in reinforcement learning.