 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Options from Demonstration using Skill Segmentation
Jan 19, 2020



We present a method for learning options from segmented demonstration trajectories. The trajectories are first segmented into skills using nonparametric Bayesian clustering and a reward function for each segment is then learned using inverse reinforcement learning. From this, a set of inferred trajectories for the demonstration are generated. Option initiation sets and termination conditions are learned from these trajectories using the one-class support vector machine clustering algorithm. We demonstrate our method in the four rooms domain, where an agent is able to autonomously discover usable options from human demonstration. Our results show that these inferred options can then be used to improve learning and planning.
Reinforcement Learning with Parameterized Actions
Nov 26, 2015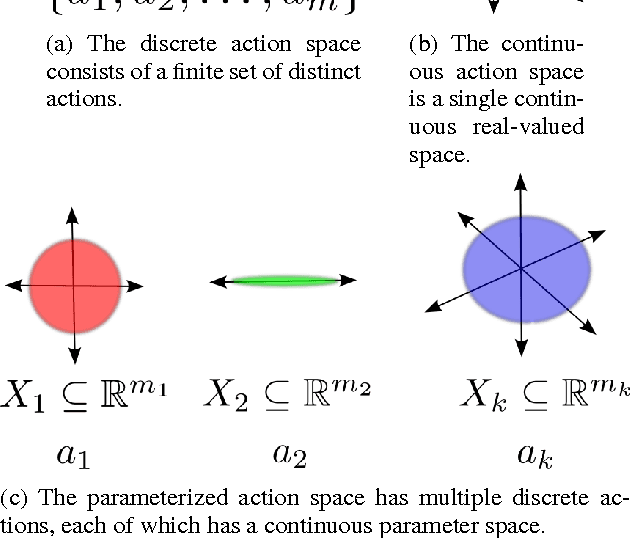



We introduce a model-free algorithm for learning in Markov decision processes with parameterized actions-discrete actions with continuous parameters. At each step the agent must select both which action to use and which parameters to use with that action. We introduce the Q-PAMDP algorithm for learning in these domains, show that it converges to a local optimum, and compare it to direct policy search in the goal-scoring and Platform domains.