Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Parameterized Actions
Paper and Code
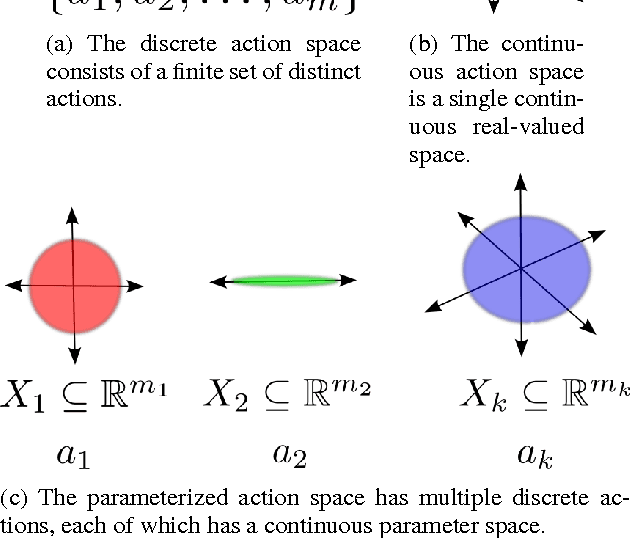



We introduce a model-free algorithm for learning in Markov decision processes with parameterized actions-discrete actions with continuous parameters. At each step the agent must select both which action to use and which parameters to use with that action. We introduce the Q-PAMDP algorithm for learning in these domains, show that it converges to a local optimum, and compare it to direct policy search in the goal-scoring and Platform domains.
* Accepted for AAAI 2016
View paper on