 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Transfers Required: Integrating Last Mile with Public Transit Using Opti-Mile
Jun 28, 2023Public transit is a popular mode of transit due to its affordability, despite the inconveniences due to the necessity of transfers required to reach most areas. For example, in the bus and metro network of New Delhi, only 30\% of stops can be directly accessed from any starting point, thus requiring transfers for most commutes. Additionally, last-mile services like rickshaws, tuk-tuks or shuttles are commonly used as feeders to the nearest public transit access points, which further adds to the complexity and inefficiency of a journey. Ultimately, users often face a tradeoff between coverage and transfers to reach their destination, regardless of the mode of transit or the use of last-mile services. To address the problem of limited accessibility and inefficiency due to transfers in public transit systems, we propose ``opti-mile," a novel trip planning approach that combines last-mile services with public transit such that no transfers are required. Opti-mile allows users to customise trip parameters such as maximum walking distance, and acceptable fare range. We analyse the transit network of New Delhi, evaluating the efficiency, feasibility and advantages of opti-mile for optimal multi-modal trips between randomly selected source-destination pairs. We demonstrate that opti-mile trips lead to a 10% reduction in distance travelled for 18% increase in price compared to traditional shortest paths. We also show that opti-mile trips provide better coverage of the city than public transit, without a significant fare increase.
Dense Air Quality Maps Using Regressive Facility Location Based Drive By Sensing
Jan 20, 2022Currently, fixed static sensing is a primary way to monitor environmental data like air quality in cities. However, to obtain a dense spatial coverage, a large number of static monitors are required, thereby making it a costly option. Dense spatiotemporal coverage can be achieved using only a fraction of static sensors by deploying them on the moving vehicles, known as the drive by sensing paradigm. The redundancy present in the air quality data can be exploited by processing the sparsely sampled data to impute the remaining unobserved data points using the matrix completion techniques. However, the accuracy of imputation is dependent on the extent to which the moving sensors capture the inherent structure of the air quality matrix. Therefore, the challenge is to pick those set of paths (using vehicles) that perform representative sampling in space and time. Most works in the literature for vehicle subset selection focus on maximizing the spatiotemporal coverage by maximizing the number of samples for different locations and time stamps which is not an effective representative sampling strategy. We present regressive facility location-based drive by sensing, an efficient vehicle selection framework that incorporates the smoothness in neighboring locations and autoregressive time correlation while selecting the optimal set of vehicles for effective spatiotemporal sampling. We show that the proposed drive by sensing problem is submodular, thereby lending itself to a greedy algorithm but with performance guarantees. We evaluate our framework on selecting a subset from the fleet of public transport in Delhi, India. We illustrate that the proposed method samples the representative spatiotemporal data against the baseline methods, reducing the extrapolation error on the simulated air quality data. Our method, therefore, has the potential to provide cost effective dense air quality maps.
Variational Bayesian Filtering with Subspace Information for Extreme Spatio-Temporal Matrix Completion
Jan 20, 2022Missing data is a common problem in real-world sensor data collection. The performance of various approaches to impute data degrade rapidly in the extreme scenarios of low data sampling and noisy sampling, a case present in many real-world problems in the field of traffic sensing and environment monitoring, etc. However, jointly exploiting the spatiotemporal and periodic structure, which is generally not captured by classical matrix completion approaches, can improve the imputation performance of sensor data in such real-world conditions. We present a Bayesian approach towards spatiotemporal matrix completion wherein we estimate the underlying temporarily varying subspace using a Variational Bayesian technique. We jointly couple the low-rank matrix completion with the state space autoregressive framework along with a penalty function on the slowly varying subspace to model the temporal and periodic evolution in the data. A major advantage of our method is that a critical parameter like the rank of the model is automatically tuned using the automatic relevance determination (ARD) approach, unlike most matrix/tensor completion techniques. We also propose a robust version of the above formulation, which improves the performance of imputation in the presence of outliers. We evaluate the proposed Variational Bayesian Filtering with Subspace Information (VBFSI) method to impute matrices in real-world traffic and air pollution data. Simulation results demonstrate that the proposed method outperforms the recent state-of-the-art methods and provides a sufficiently accurate imputation for different sampling rates. In particular, we demonstrate that fusing the subspace evolution over days can improve the imputation performance with even 15% of the data sampling.
Benchmark Dataset for Timetable Optimization of Bus Routes in the City of New Delhi
Oct 20, 2019



Public transport is one of the major forms of transportation in the world. This makes it vital to ensure that public transport is efficient. This research presents a novel real-time GPS bus transit data for over 500 routes of buses operating in New Delhi. The data can be used for modeling various timetable optimization tasks as well as in other domains such as traffic management, travel time estimation, etc. The paper also presents an approach to reduce the waiting time of Delhi buses by analyzing the traffic behavior and proposing a timetable. This algorithm serves as a benchmark for the dataset. The algorithm uses a constrained clustering algorithm for classification of trips. It further analyses the data statistically to provide a timetable which is efficient in learning the inter- and intra-month variations.
To each route its own ETA: A generative modeling framework for ETA prediction
Jun 24, 2019
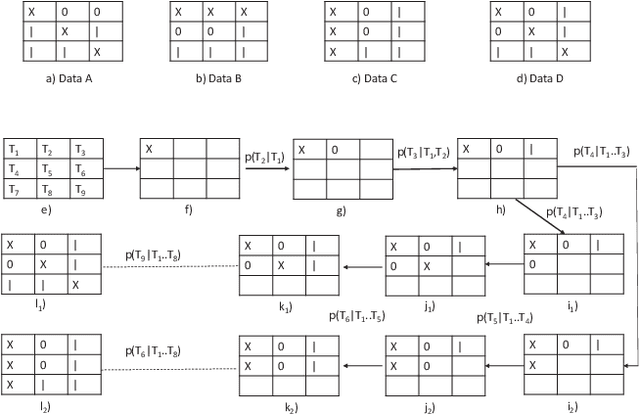
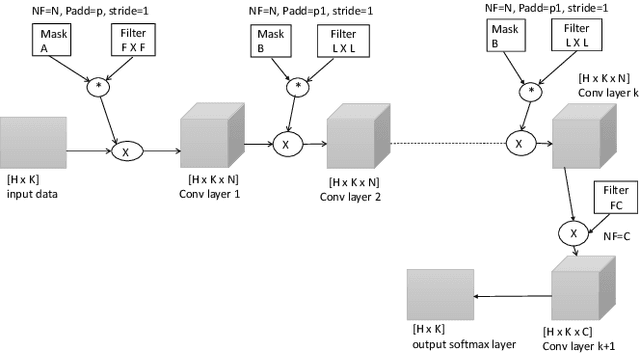
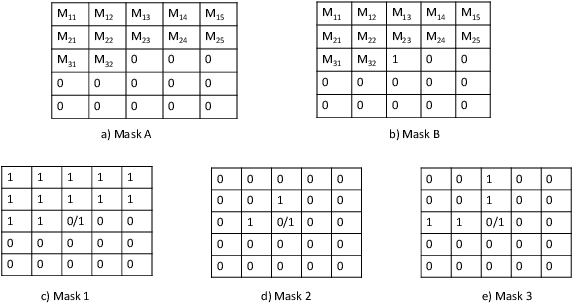
Accurate expected time of arrival (ETA) information is crucial in maintaining the quality of service of public transit. Recent advances in artificial intelligence (AI) has led to more effective models for ETA estimation that rely heavily on a large GPS datasets. More importantly, these are mainly cabs based datasets which may not be fit for bus-based public transport. Consequently, the latest methods may not be applicable for ETA estimation in cities with the absence of large training data set. On the other hand, the ETA estimation problem in many cities needs to be solved in the absence of big datasets that also contains outliers, anomalies and may be incomplete. This work presents a simple but robust model for ETA estimation for a bus route that only relies on the historical data of the particular route. We propose a system that generates ETA information for a trip and updates it as the trip progresses based on the real-time information. We train a deep learning based generative model that learns the probability distribution of ETA data across trips and conditional on the current trip information updates the ETA information on the go. Our plug and play model not only captures the non-linearity of the task well but that any transit agency can use without needing any other external data source. The experiments run over three routes, data collected in the city of Delhi illustrates the promise of our approach.
Distributed Representations for Biological Sequence Analysis
Sep 12, 2016
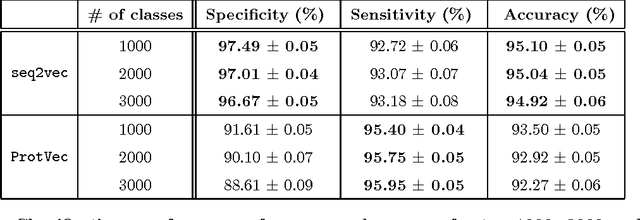
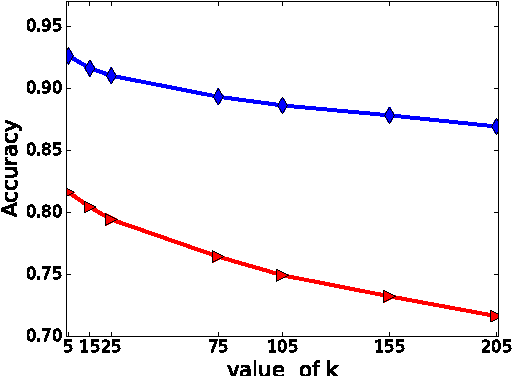

Biological sequence comparison is a key step in inferring the relatedness of various organisms and the functional similarity of their components. Thanks to the Next Generation Sequencing efforts, an abundance of sequence data is now available to be processed for a range of bioinformatics applications. Embedding a biological sequence over a nucleotide or amino acid alphabet in a lower dimensional vector space makes the data more amenable for use by current machine learning tools, provided the quality of embedding is high and it captures the most meaningful information of the original sequences. Motivated by recent advances in the text document embedding literature, we present a new method, called seq2vec, to represent a complete biological sequence in an Euclidean space. The new representation has the potential to capture the contextual information of the original sequence necessary for sequence comparison tasks. We test our embeddings with protein sequence classification and retrieval tasks and demonstrate encouraging outcomes.