 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Embeddings based Convolutional Neural Networks for Duplicate Question Identification
Sep 06, 2021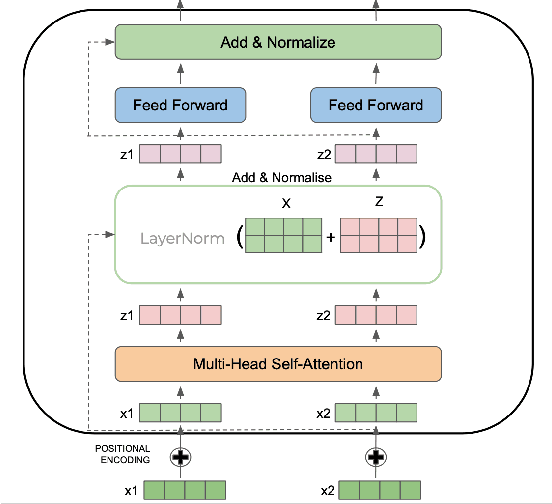

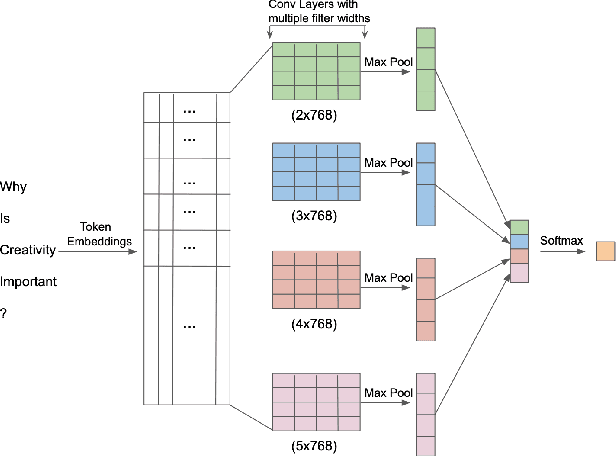
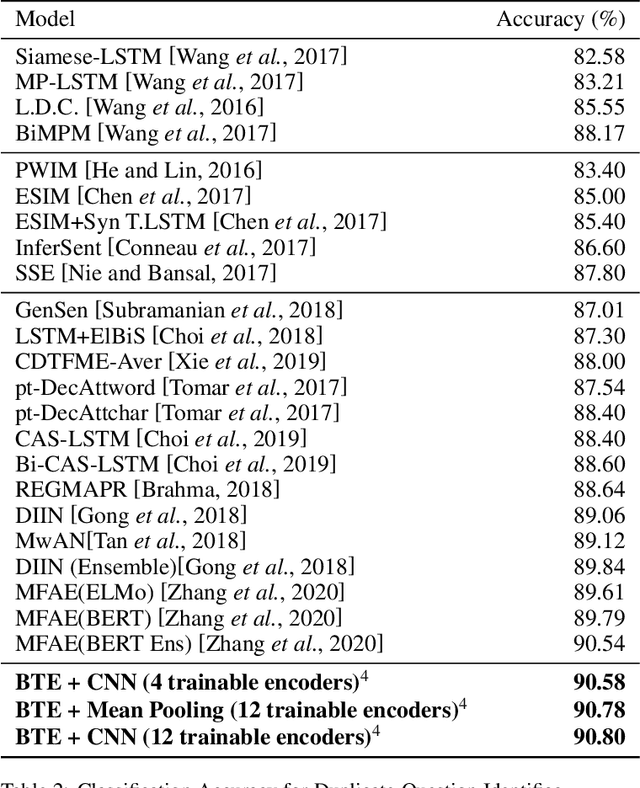
Question Paraphrase Identification (QPI) is a critical task for large-scale Question-Answering forums. The purpose of QPI is to determine whether a given pair of questions are semantically identical or not. Previous approaches for this task have yielded promising results, but have often relied on complex recurrence mechanisms that are expensive and time-consuming in nature. In this paper, we propose a novel architecture combining a Bidirectional Transformer Encoder with Convolutional Neural Networks for the QPI task. We produce the predictions from the proposed architecture using two different inference setups: Siamese and Matched Aggregation. Experimental results demonstrate that our model achieves state-of-the-art performance on the Quora Question Pairs dataset. We empirically prove that the addition of convolution layers to the model architecture improves the results in both inference setups. We also investigate the impact of partial and complete fine-tuning and analyze the trade-off between computational power and accuracy in the process. Based on the obtained results, we conclude that the Matched-Aggregation setup consistently outperforms the Siamese setup. Our work provides insights into what architecture combinations and setups are likely to produce better results for the QPI task.
A decentralized aggregation mechanism for training deep learning models using smart contract system for bank loan prediction
Nov 22, 2020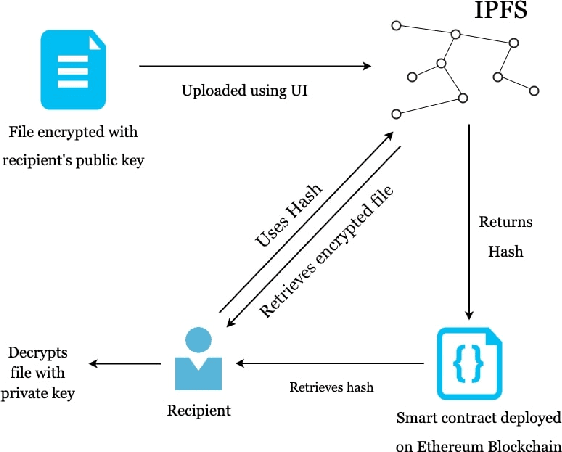
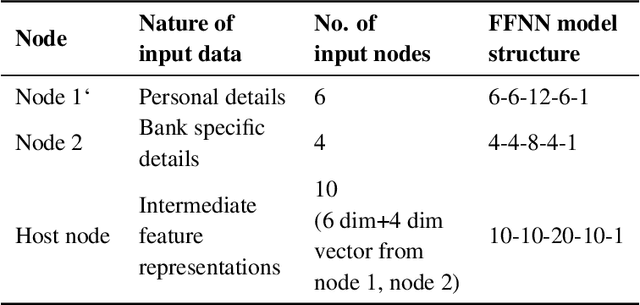
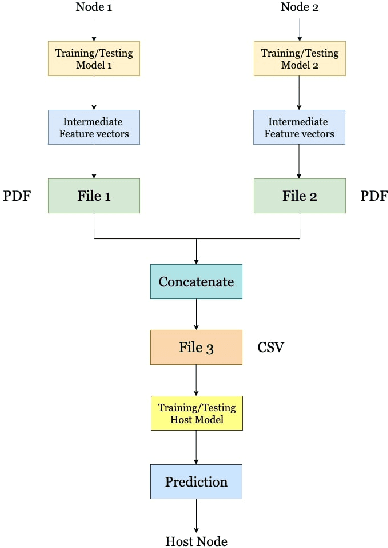

Data privacy and sharing has always been a critical issue when trying to build complex deep learning-based systems to model data. Facilitation of a decentralized approach that could take benefit from data across multiple nodes while not needing to merge their data contents physically has been an area of active research. In this paper, we present a solution to benefit from a distributed data setup in the case of training deep learning architectures by making use of a smart contract system. Specifically, we propose a mechanism that aggregates together the intermediate representations obtained from local ANN models over a blockchain. Training of local models takes place on their respective data. The intermediate representations derived from them, when combined and trained together on the host node, helps to get a more accurate system. While federated learning primarily deals with the same features of data where the number of samples being distributed on multiple nodes, here we are dealing with the same number of samples but with their features being distributed on multiple nodes. We consider the task of bank loan prediction wherein the personal details of an individual and their bank-specific details may not be available at the same place. Our aggregation mechanism helps to train a model on such existing distributed data without having to share and concatenate together the actual data values. The obtained performance, which is better than that of individual nodes, and is at par with that of a centralized data setup makes a strong case for extending our technique across other architectures and tasks. The solution finds its application in organizations that want to train deep learning models on vertically partitioned data.
Evolution of transfer learning in natural language processing
Oct 16, 2019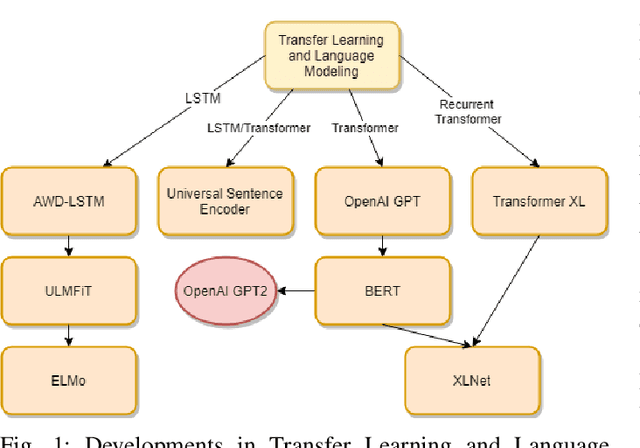
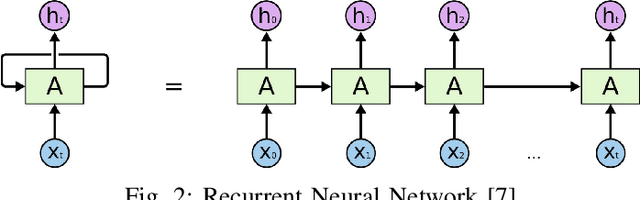
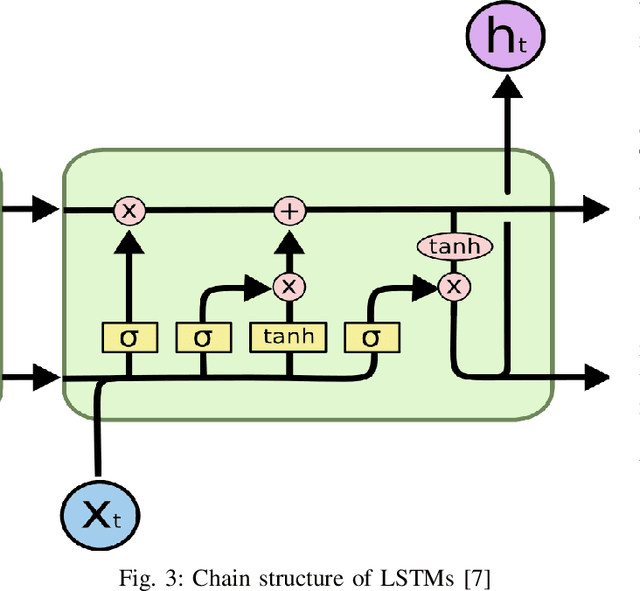
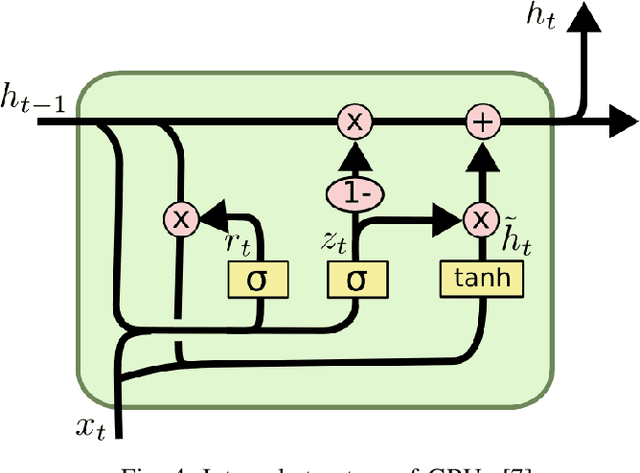
In this paper, we present a study of the recent advancements which have helped bring Transfer Learning to NLP through the use of semi-supervised training. We discuss cutting-edge methods and architectures such as BERT, GPT, ELMo, ULMFit among others. Classically, tasks in natural language processing have been performed through rule-based and statistical methodologies. However, owing to the vast nature of natural languages these methods do not generalise well and failed to learn the nuances of language. Thus machine learning algorithms such as Naive Bayes and decision trees coupled with traditional models such as Bag-of-Words and N-grams were used to usurp this problem. Eventually, with the advent of advanced recurrent neural network architectures such as the LSTM, we were able to achieve state-of-the-art performance in several natural language processing tasks such as text classification and machine translation. We talk about how Transfer Learning has brought about the well-known ImageNet moment for NLP. Several advanced architectures such as the Transformer and its variants have allowed practitioners to leverage knowledge gained from unrelated task to drastically fasten convergence and provide better performance on the target task. This survey represents an effort at providing a succinct yet complete understanding of the recent advances in natural language processing using deep learning in with a special focus on detailing transfer learning and its potential advantages.
Spam filtering on forums: A synthetic oversampling based approach for imbalanced data classification
Sep 10, 2019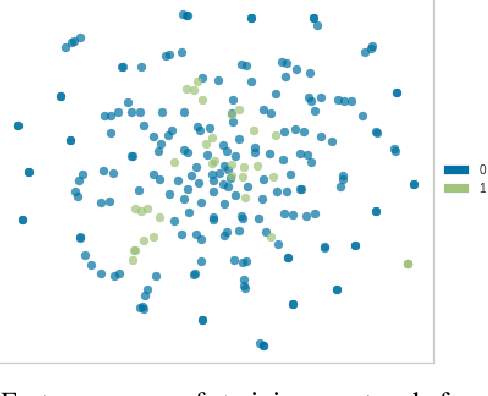
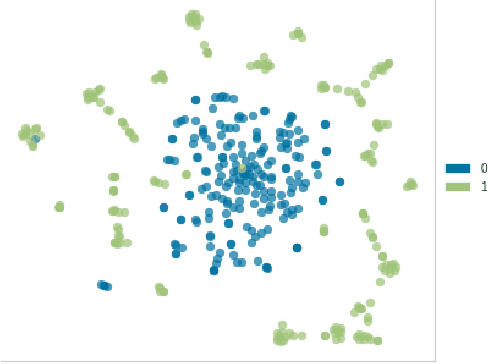
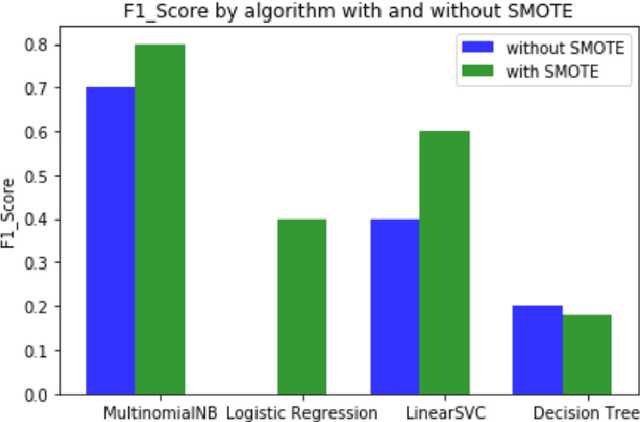
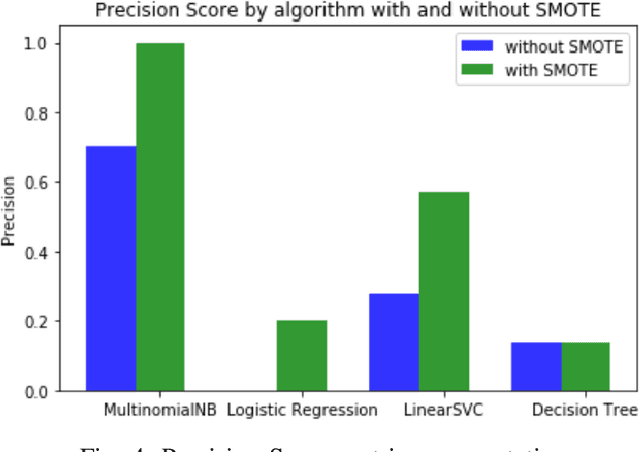
Forums play an important role in providing a platform for community interaction. The introduction of irrelevant content or spam by individuals for commercial and social gains tends to degrade the professional experience presented to the forum users. Automated moderation of the relevancy of posted content is desired. Machine learning is used for text classification and finds applications in spam email detection, fraudulent transaction detection etc. The balance of classes in training data is essential in the case of classification algorithms to make the learning efficient and accurate. However, in the case of forums, the spam content is sparse compared to the relevant content giving rise to a bias towards the latter while training. A model trained on such biased data will fail to classify a spam sample. An approach based on Synthetic Minority Over-sampling Technique(SMOTE) is presented in this paper to tackle imbalanced training data. It involves synthetically creating new minority class samples from the existing ones until balance in data is achieved. The enhanced data is then passed through various classifiers for which the performance is recorded. The results were analyzed on the data of forums of Spoken Tutorial, IIT Bombay over standard performance metrics and revealed that models trained after Synthetic Minority oversampling outperform the ones trained on imbalanced data by substantial margins. An empirical comparison of the results obtained by both SMOTE and without SMOTE for various supervised classification algorithms have been presented in this paper. Synthetic oversampling proves to be a critical technique for achieving uniform class distribution which in turn yields commendable results in text classification. The presented approach can be further extended to content categorization on educational websites thus helping to improve the overall digital learning experience.