 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA decentralized aggregation mechanism for training deep learning models using smart contract system for bank loan prediction
Paper and Code
Nov 22, 2020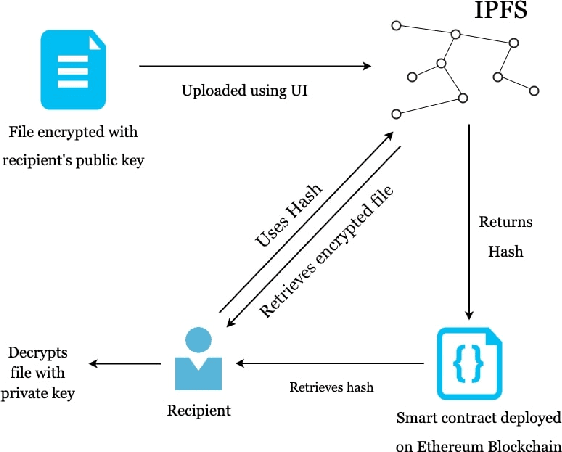
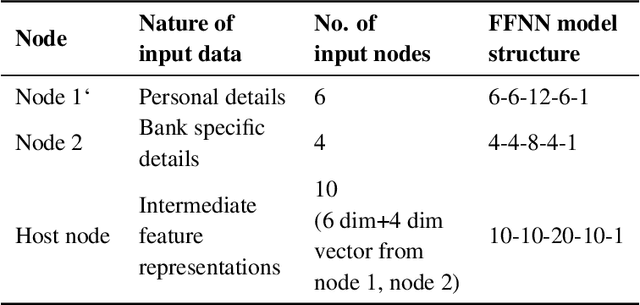
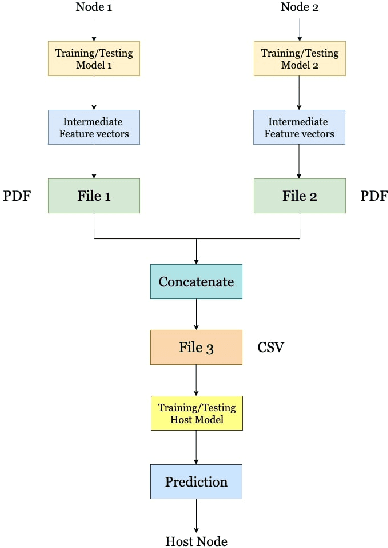

Data privacy and sharing has always been a critical issue when trying to build complex deep learning-based systems to model data. Facilitation of a decentralized approach that could take benefit from data across multiple nodes while not needing to merge their data contents physically has been an area of active research. In this paper, we present a solution to benefit from a distributed data setup in the case of training deep learning architectures by making use of a smart contract system. Specifically, we propose a mechanism that aggregates together the intermediate representations obtained from local ANN models over a blockchain. Training of local models takes place on their respective data. The intermediate representations derived from them, when combined and trained together on the host node, helps to get a more accurate system. While federated learning primarily deals with the same features of data where the number of samples being distributed on multiple nodes, here we are dealing with the same number of samples but with their features being distributed on multiple nodes. We consider the task of bank loan prediction wherein the personal details of an individual and their bank-specific details may not be available at the same place. Our aggregation mechanism helps to train a model on such existing distributed data without having to share and concatenate together the actual data values. The obtained performance, which is better than that of individual nodes, and is at par with that of a centralized data setup makes a strong case for extending our technique across other architectures and tasks. The solution finds its application in organizations that want to train deep learning models on vertically partitioned data.