 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtlas Urban Index: A VLM-Based Approach for Spatially and Temporally Calibrated Urban Development Monitoring
Oct 26, 2025We introduce the {\em Atlas Urban Index} (AUI), a metric for measuring urban development computed using Sentinel-2 \citep{spoto2012sentinel2} satellite imagery. Existing approaches, such as the {\em Normalized Difference Built-up Index} (NDBI), often struggle to accurately capture urban development due to factors like atmospheric noise, seasonal variation, and cloud cover. These limitations hinder large-scale monitoring of human development and urbanization. To address these challenges, we propose an approach that leverages {\em Vision-Language Models }(VLMs) to provide a development score for regions. Specifically, we collect a time series of Sentinel-2 images for each region. Then, we further process the images within fixed time windows to get an image with minimal cloud cover, which serves as the representative image for that time window. To ensure consistent scoring, we adopt two strategies: (i) providing the VLM with a curated set of reference images representing different levels of urbanization, and (ii) supplying the most recent past image to both anchor temporal consistency and mitigate cloud-related noise in the current image. Together, these components enable AUI to overcome the challenges of traditional urbanization indices and produce more reliable and stable development scores. Our qualitative experiments on Bangalore suggest that AUI outperforms standard indices such as NDBI.
Communication-Constrained Bandits under Additive Gaussian Noise
Apr 25, 2023We study a distributed stochastic multi-armed bandit where a client supplies the learner with communication-constrained feedback based on the rewards for the corresponding arm pulls. In our setup, the client must encode the rewards such that the second moment of the encoded rewards is no more than $P$, and this encoded reward is further corrupted by additive Gaussian noise of variance $\sigma^2$; the learner only has access to this corrupted reward. For this setting, we derive an information-theoretic lower bound of $\Omega\left(\sqrt{\frac{KT}{\mathtt{SNR} \wedge1}} \right)$ on the minimax regret of any scheme, where $ \mathtt{SNR} := \frac{P}{\sigma^2}$, and $K$ and $T$ are the number of arms and time horizon, respectively. Furthermore, we propose a multi-phase bandit algorithm, $\mathtt{UE\text{-}UCB++}$, which matches this lower bound to a minor additive factor. $\mathtt{UE\text{-}UCB++}$ performs uniform exploration in its initial phases and then utilizes the {\em upper confidence bound }(UCB) bandit algorithm in its final phase. An interesting feature of $\mathtt{UE\text{-}UCB++}$ is that the coarser estimates of the mean rewards formed during a uniform exploration phase help to refine the encoding protocol in the next phase, leading to more accurate mean estimates of the rewards in the subsequent phase. This positive reinforcement cycle is critical to reducing the number of uniform exploration rounds and closely matching our lower bound.
Fundamental limits of over-the-air optimization: Are analog schemes optimal?
Sep 15, 2021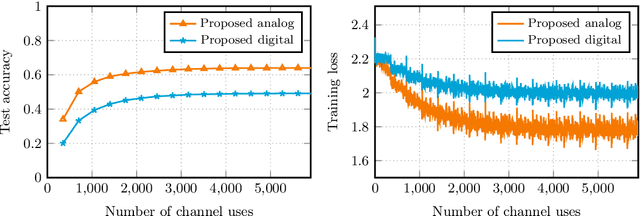
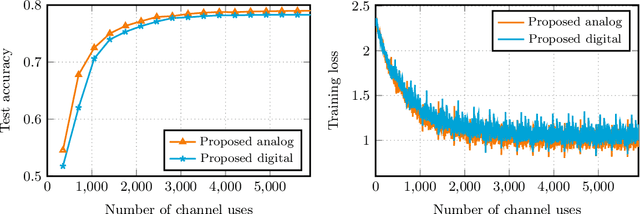
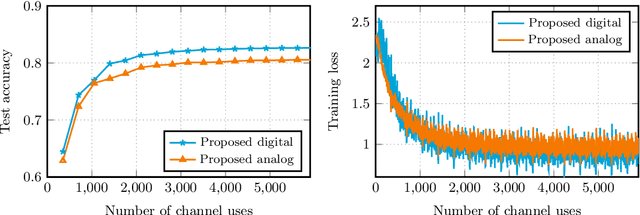
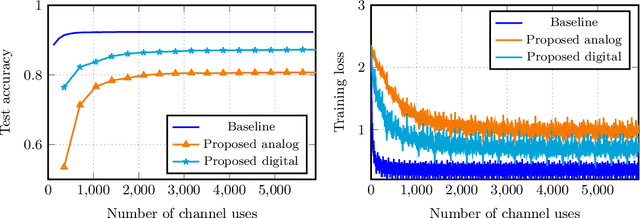
We consider over-the-air convex optimization on a $d-$dimensional space where coded gradients are sent over an additive Gaussian noise channel with variance $\sigma^2$. The codewords satisfy an average power constraint $P$, resulting in the signal-to-noise ratio (SNR) of $P/\sigma^2$. We derive bounds for the convergence rates for over-the-air optimization. Our first result is a lower bound for the convergence rate showing that any code must slowdown the convergence rate by a factor of roughly $\sqrt{d/\log(1+\mathtt{SNR})}$. Next, we consider a popular class of schemes called $analog$ $coding$, where a linear function of the gradient is sent. We show that a simple scaled transmission analog coding scheme results in a slowdown in convergence rate by a factor of $\sqrt{d(1+1/\mathtt{SNR})}$. This matches the previous lower bound up to constant factors for low SNR, making the scaled transmission scheme optimal at low SNR. However, we show that this slowdown is necessary for any analog coding scheme. In particular, a slowdown in convergence by a factor of $\sqrt{d}$ for analog coding remains even when SNR tends to infinity. Remarkably, we present a simple quantize-and-modulate scheme that uses $Amplitude$ $Shift$ $Keying$ and almost attains the optimal convergence rate at all SNRs.
Wyner-Ziv Estimators: Efficient Distributed Mean Estimation with Side Information
Nov 24, 2020
Communication efficient distributed mean estimation is an important primitive that arises in many distributed learning and optimization scenarios such as federated learning. Without any probabilistic assumptions on the underlying data, we study the problem of distributed mean estimation where the server has access to side information. We propose \emph{Wyner-Ziv estimators}, which are communication and computationally efficient and near-optimal when an upper bound for the distance between the side information and the data is known. As a corollary, we also show that our algorithms provide efficient schemes for the classic Wyner-Ziv problem in information theory. In a different direction, when there is no knowledge assumed about the distance between side information and the data, we present an alternative Wyner-Ziv estimator that uses correlated sampling. This latter setting offers {\em universal recovery guarantees}, and perhaps will be of interest in practice when the number of users is large and keeping track of the distances between the data and the side information may not be possible.
Finite Precision Stochastic Optimization -- Accounting for the Bias
Aug 26, 2019
We consider first order stochastic optimization where the oracle must quantize each subgradient estimate to $r$ bits. We treat two oracle models: the first where the Euclidean norm of the oracle output is almost surely bounded and the second where it is mean square bounded. Prior work in this setting assumes the availability of unbiased quantizers. While this assumption is valid in the case of almost surely bounded oracles, it does not hold true for the standard setting of mean square bounded oracles, and the bias can dramatically affect the convergence rate. We analyze the performance of standard quantizers from prior work in combination with projected stochastic gradient descent for both these oracle models and present two new adaptive quantizers that outperform the existing ones. Specifically, for almost surely bounded oracles, we establish first a lower bound for the precision needed to attain the standard convergence rate of $T^{-\frac 12}$ for optimizing convex functions over a $d$-dimentional domain. Our proposed Rotated Adaptive Tetra-iterated Quantizer (RATQ) is merely a factor $O(\log \log \log^\ast d)$ far from this lower bound. For mean square bounded oracles, we show that a state-of-the-art Rotated Uniform Quantizer (RUQ) from prior work would need atleast $\Omega(d\log T)$ bits to achieve the convergence rate of $T^{-\frac 12}$, using any optimization protocol. However, our proposed Rotated Adaptive Quantizer (RAQ) outperforms RUQ in this setting and attains a convergence rate of $T^{-\frac 12}$ using a precision of only $O(d\log\log T)$. For mean square bounded oracles, in the communication-starved regime where the precision $r$ is fixed to a constant independent of $T$, we show that RUQ cannot attain a convergence rate better than $T^{-\frac 14}$ for any $r$, while RAQ can attain convergence at rates arbitrarily close to $T^{-\frac 12}$ as $r$ increases.