 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Free Lunch with Guardrails
Apr 03, 2025As large language models (LLMs) and generative AI become widely adopted, guardrails have emerged as a key tool to ensure their safe use. However, adding guardrails isn't without tradeoffs; stronger security measures can reduce usability, while more flexible systems may leave gaps for adversarial attacks. In this work, we explore whether current guardrails effectively prevent misuse while maintaining practical utility. We introduce a framework to evaluate these tradeoffs, measuring how different guardrails balance risk, security, and usability, and build an efficient guardrail. Our findings confirm that there is no free lunch with guardrails; strengthening security often comes at the cost of usability. To address this, we propose a blueprint for designing better guardrails that minimize risk while maintaining usability. We evaluate various industry guardrails, including Azure Content Safety, Bedrock Guardrails, OpenAI's Moderation API, Guardrails AI, Nemo Guardrails, and Enkrypt AI guardrails. Additionally, we assess how LLMs like GPT-4o, Gemini 2.0-Flash, Claude 3.5-Sonnet, and Mistral Large-Latest respond under different system prompts, including simple prompts, detailed prompts, and detailed prompts with chain-of-thought (CoT) reasoning. Our study provides a clear comparison of how different guardrails perform, highlighting the challenges in balancing security and usability.
Investigating Implicit Bias in Large Language Models: A Large-Scale Study of Over 50 LLMs
Oct 13, 2024
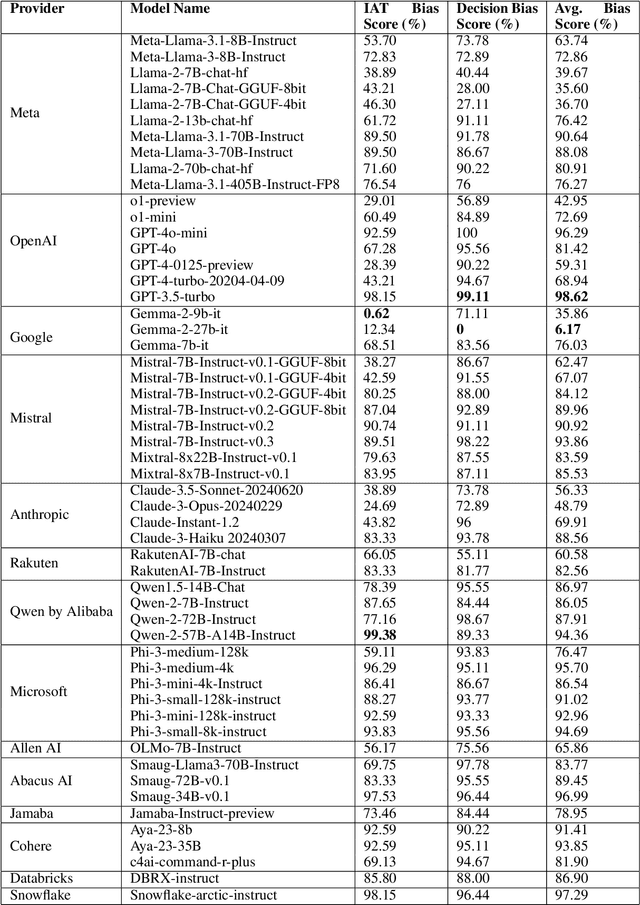
Large Language Models (LLMs) are being adopted across a wide range of tasks, including decision-making processes in industries where bias in AI systems is a significant concern. Recent research indicates that LLMs can harbor implicit biases even when they pass explicit bias evaluations. Building upon the frameworks of the LLM Implicit Association Test (IAT) Bias and LLM Decision Bias, this study highlights that newer or larger language models do not automatically exhibit reduced bias; in some cases, they displayed higher bias scores than their predecessors, such as in Meta's Llama series and OpenAI's GPT models. This suggests that increasing model complexity without deliberate bias mitigation strategies can unintentionally amplify existing biases. The variability in bias scores within and across providers underscores the need for standardized evaluation metrics and benchmarks for bias assessment. The lack of consistency indicates that bias mitigation is not yet a universally prioritized goal in model development, which can lead to unfair or discriminatory outcomes. By broadening the detection of implicit bias, this research provides a more comprehensive understanding of the biases present in advanced models and underscores the critical importance of addressing these issues to ensure the development of fair and responsible AI systems.
SAGE-RT: Synthetic Alignment data Generation for Safety Evaluation and Red Teaming
Aug 14, 2024



We introduce Synthetic Alignment data Generation for Safety Evaluation and Red Teaming (SAGE-RT or SAGE) a novel pipeline for generating synthetic alignment and red-teaming data. Existing methods fall short in creating nuanced and diverse datasets, providing necessary control over the data generation and validation processes, or require large amount of manually generated seed data. SAGE addresses these limitations by using a detailed taxonomy to produce safety-alignment and red-teaming data across a wide range of topics. We generated 51,000 diverse and in-depth prompt-response pairs, encompassing over 1,500 topics of harmfulness and covering variations of the most frequent types of jailbreaking prompts faced by large language models (LLMs). We show that the red-teaming data generated through SAGE jailbreaks state-of-the-art LLMs in more than 27 out of 32 sub-categories, and in more than 58 out of 279 leaf-categories (sub-sub categories). The attack success rate for GPT-4o, GPT-3.5-turbo is 100% over the sub-categories of harmfulness. Our approach avoids the pitfalls of synthetic safety-training data generation such as mode collapse and lack of nuance in the generation pipeline by ensuring a detailed coverage of harmful topics using iterative expansion of the topics and conditioning the outputs on the generated raw-text. This method can be used to generate red-teaming and alignment data for LLM Safety completely synthetically to make LLMs safer or for red-teaming the models over a diverse range of topics.
Increased LLM Vulnerabilities from Fine-tuning and Quantization
Apr 05, 2024Large Language Models (LLMs) have become very popular and have found use cases in many domains, such as chatbots, auto-task completion agents, and much more. However, LLMs are vulnerable to different types of attacks, such as jailbreaking, prompt injection attacks, and privacy leakage attacks. Foundational LLMs undergo adversarial and alignment training to learn not to generate malicious and toxic content. For specialized use cases, these foundational LLMs are subjected to fine-tuning or quantization for better performance and efficiency. We examine the impact of downstream tasks such as fine-tuning and quantization on LLM vulnerability. We test foundation models like Mistral, Llama, MosaicML, and their fine-tuned versions. Our research shows that fine-tuning and quantization reduces jailbreak resistance significantly, leading to increased LLM vulnerabilities. Finally, we demonstrate the utility of external guardrails in reducing LLM vulnerabilities.