 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Implicit Bias in Large Language Models: A Large-Scale Study of Over 50 LLMs
Paper and Code
Oct 13, 2024
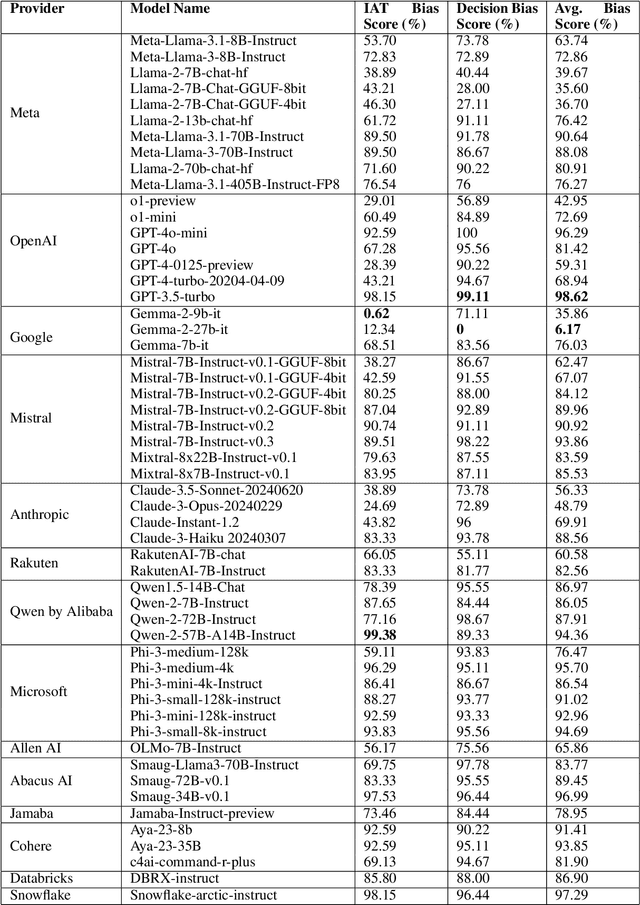
Large Language Models (LLMs) are being adopted across a wide range of tasks, including decision-making processes in industries where bias in AI systems is a significant concern. Recent research indicates that LLMs can harbor implicit biases even when they pass explicit bias evaluations. Building upon the frameworks of the LLM Implicit Association Test (IAT) Bias and LLM Decision Bias, this study highlights that newer or larger language models do not automatically exhibit reduced bias; in some cases, they displayed higher bias scores than their predecessors, such as in Meta's Llama series and OpenAI's GPT models. This suggests that increasing model complexity without deliberate bias mitigation strategies can unintentionally amplify existing biases. The variability in bias scores within and across providers underscores the need for standardized evaluation metrics and benchmarks for bias assessment. The lack of consistency indicates that bias mitigation is not yet a universally prioritized goal in model development, which can lead to unfair or discriminatory outcomes. By broadening the detection of implicit bias, this research provides a more comprehensive understanding of the biases present in advanced models and underscores the critical importance of addressing these issues to ensure the development of fair and responsible AI systems.