 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalsesum: Generating Document-level NLI Examples for Recognizing Factual Inconsistency in Summarization
May 12, 2022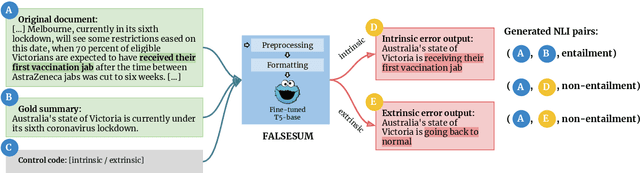

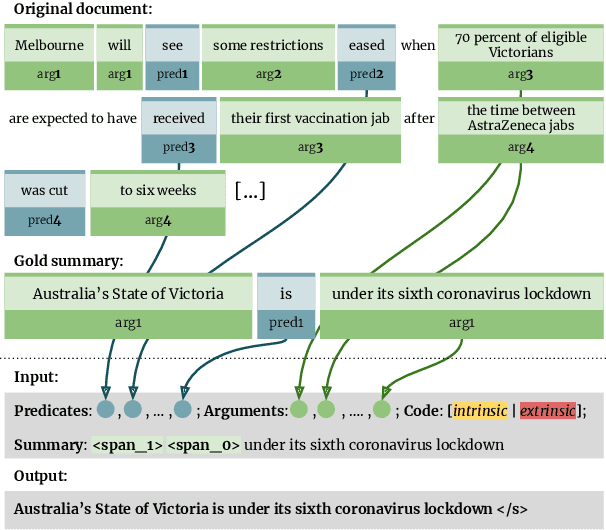
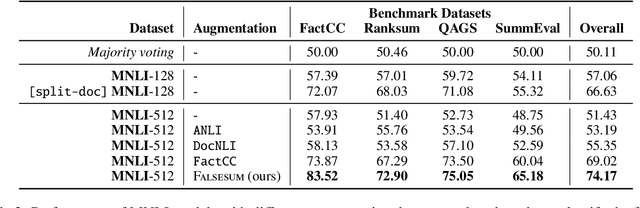
Neural abstractive summarization models are prone to generate summaries which are factually inconsistent with their source documents. Previous work has introduced the task of recognizing such factual inconsistency as a downstream application of natural language inference (NLI). However, state-of-the-art NLI models perform poorly in this context due to their inability to generalize to the target task. In this work, we show that NLI models can be effective for this task when the training data is augmented with high-quality task-oriented examples. We introduce Falsesum, a data generation pipeline leveraging a controllable text generation model to perturb human-annotated summaries, introducing varying types of factual inconsistencies. Unlike previously introduced document-level NLI datasets, our generated dataset contains examples that are diverse and inconsistent yet plausible. We show that models trained on a Falsesum-augmented NLI dataset improve the state-of-the-art performance across four benchmarks for detecting factual inconsistency in summarization. The code to obtain the dataset is available online at https://github.com/joshbambrick/Falsesum
Avoiding Inference Heuristics in Few-shot Prompt-based Finetuning
Sep 09, 2021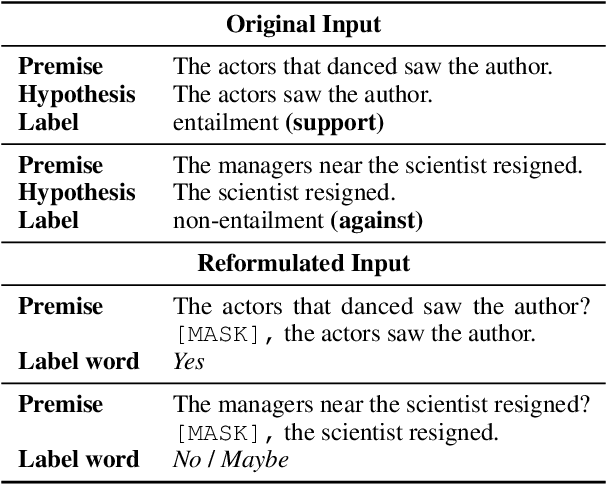
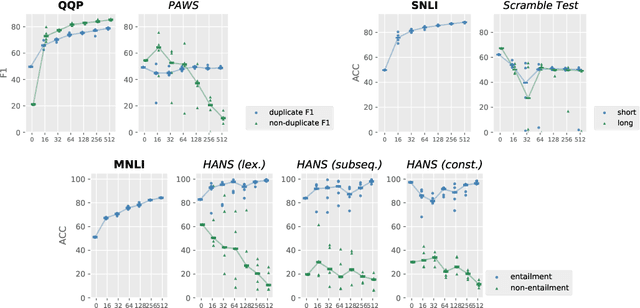

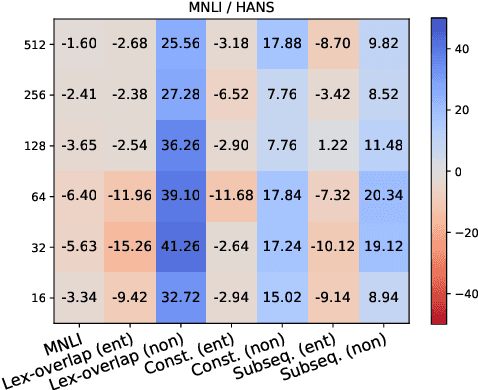
Recent prompt-based approaches allow pretrained language models to achieve strong performances on few-shot finetuning by reformulating downstream tasks as a language modeling problem. In this work, we demonstrate that, despite its advantages on low data regimes, finetuned prompt-based models for sentence pair classification tasks still suffer from a common pitfall of adopting inference heuristics based on lexical overlap, e.g., models incorrectly assuming a sentence pair is of the same meaning because they consist of the same set of words. Interestingly, we find that this particular inference heuristic is significantly less present in the zero-shot evaluation of the prompt-based model, indicating how finetuning can be destructive to useful knowledge learned during the pretraining. We then show that adding a regularization that preserves pretraining weights is effective in mitigating this destructive tendency of few-shot finetuning. Our evaluation on three datasets demonstrates promising improvements on the three corresponding challenge datasets used to diagnose the inference heuristics.
Improving Robustness by Augmenting Training Sentences with Predicate-Argument Structures
Oct 23, 2020
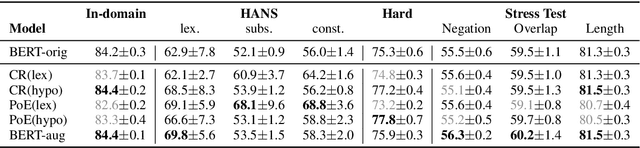


Existing NLP datasets contain various biases, and models tend to quickly learn those biases, which in turn limits their robustness. Existing approaches to improve robustness against dataset biases mostly focus on changing the training objective so that models learn less from biased examples. Besides, they mostly focus on addressing a specific bias, and while they improve the performance on adversarial evaluation sets of the targeted bias, they may bias the model in other ways, and therefore, hurt the overall robustness. In this paper, we propose to augment the input sentences in the training data with their corresponding predicate-argument structures, which provide a higher-level abstraction over different realizations of the same meaning and help the model to recognize important parts of sentences. We show that without targeting a specific bias, our sentence augmentation improves the robustness of transformer models against multiple biases. In addition, we show that models can still be vulnerable to the lexical overlap bias, even when the training data does not contain this bias, and that the sentence augmentation also improves the robustness in this scenario. We will release our adversarial datasets to evaluate bias in such a scenario as well as our augmentation scripts at https://github.com/UKPLab/data-augmentation-for-robustness.
Towards Debiasing NLU Models from Unknown Biases
Oct 13, 2020
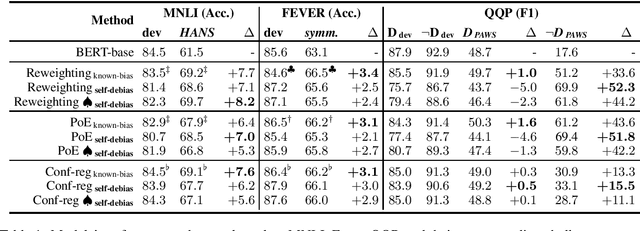
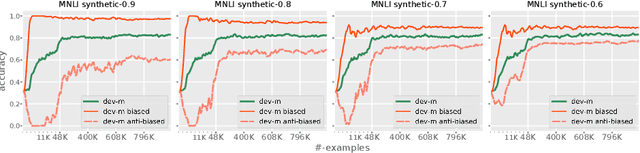
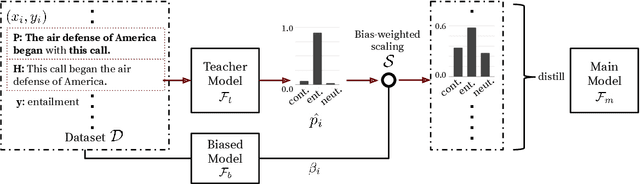
NLU models often exploit biases to achieve high dataset-specific performance without properly learning the intended task. Recently proposed debiasing methods are shown to be effective in mitigating this tendency. However, these methods rely on a major assumption that the types of bias should be known a-priori, which limits their application to many NLU tasks and datasets. In this work, we present the first step to bridge this gap by introducing a self-debiasing framework that prevents models from mainly utilizing biases without knowing them in advance. The proposed framework is general and complementary to the existing debiasing methods. We show that it allows these existing methods to retain the improvement on the challenge datasets (i.e., sets of examples designed to expose models' reliance on biases) without specifically targeting certain biases. Furthermore, the evaluation suggests that applying the framework results in improved overall robustness.
Mind the Trade-off: Debiasing NLU Models without Degrading the In-distribution Performance
May 01, 2020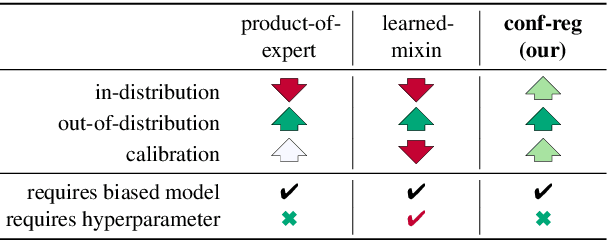
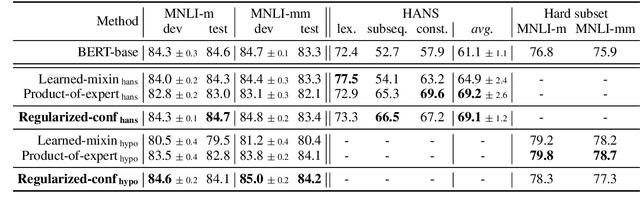
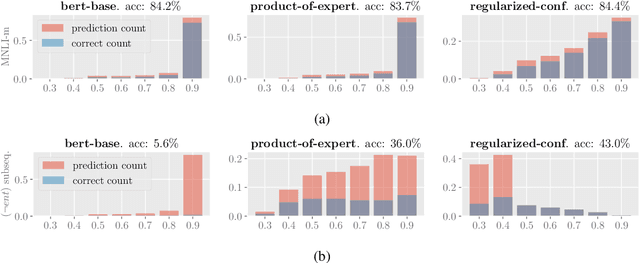
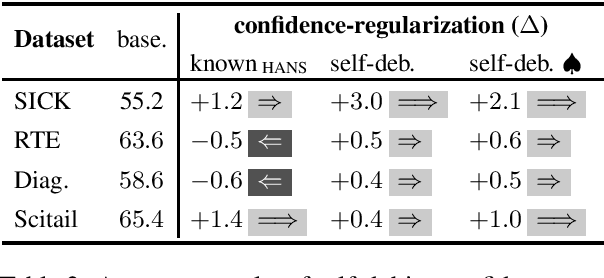
Models for natural language understanding (NLU) tasks often rely on the idiosyncratic biases of the dataset, which make them brittle against test cases outside the training distribution. Recently, several proposed debiasing methods are shown to be very effective in improving out-of-distribution performance. However, their improvements come at the expense of performance drop when models are evaluated on the in-distribution data, which contain examples with higher diversity. This seemingly inevitable trade-off may not tell us much about the changes in the reasoning and understanding capabilities of the resulting models on broader types of examples beyond the small subset represented in the out-of-distribution data. In this paper, we address this trade-off by introducing a novel debiasing method, called confidence regularization, which discourage models from exploiting biases while enabling them to receive enough incentive to learn from all the training examples. We evaluate our method on three NLU tasks and show that, in contrast to its predecessors, it improves the performance on out-of-distribution datasets (e.g., 7pp gain on HANS dataset) while maintaining the original in-distribution accuracy.
Improving Generalization by Incorporating Coverage in Natural Language Inference
Sep 19, 2019
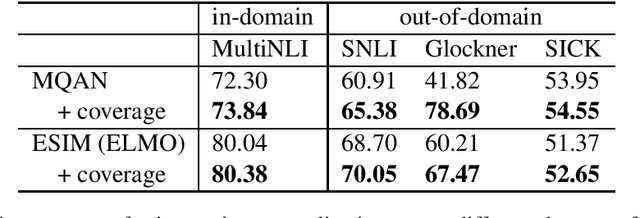

The task of natural language inference (NLI) is to identify the relation between the given premise and hypothesis. While recent NLI models achieve very high performance on individual datasets, they fail to generalize across similar datasets. This indicates that they are solving NLI datasets instead of the task itself. In order to improve generalization, we propose to extend the input representations with an abstract view of the relation between the hypothesis and the premise, i.e., how well the individual words, or word n-grams, of the hypothesis are covered by the premise. Our experiments show that the use of this information considerably improves generalization across different NLI datasets without requiring any external knowledge or additional data. Finally, we show that using the coverage information is not only beneficial for improving the performance across different datasets of the same task. The resulting generalization improves the performance across datasets that belong to similar but not the same tasks.